
三、DDD工程模型
三、DDD工程模型
什么是系统的工程结构,工程框架的作用是什么?
其实,工程结构的存在作用目的,是为了承载工程系统开发的模型划分,定义工程服务开发过程中实施标准。说白了,就是你在工程实现时,在哪个层访问数据库、哪个层使用缓存、哪个层调用外部接口、哪个层做功能实现,这就是工程框架结构定义的目的。
但在 Service + 贫血模型 的三层结构开发指导下,是没有细分出面向对象工程结构设计的趋于划分的。所以在通常意义的 MVC 下,开发过程所有需要的内容,都会堆砌到 Service 实现类中。这也是为什么 DDD 领域驱动设计的落地工程结构,会出现;洋葱架构、整洁架构、菱形架构、六边形架构等这些架构模型。因为我们需要更细致的划分,来承载 DDD 设计概念中映射的领域、仓储、适配、编排、触发,并重视面向对象过程。其实你一上学,学Java就开始学面向对象了,只不过一点点在忘记它。
1、为什么需要引入工程架构
说到开发代码为啥需要架构,就想买了个房子,为啥要隔出厨房、客厅、卧室、卫生间一样,核心目的就是让不同的职责分配到不同的区域内。虽然在代码中是没有马桶要放卫生间、沙发要放客厅、床要放卧室。但他有一些列的科目信息要引入到工程。
在工程开发时会涉及到的核心科目;

如;统一的异常、数据库的连接、日志的打印、外部服务的调用、消息的监听、任务的轮训以及服务的实现等一些列的东西要处理,分配到不同的工程包下承载。在 DDD 之前,我们一直用 MVC 的分层结构承接这些内容;
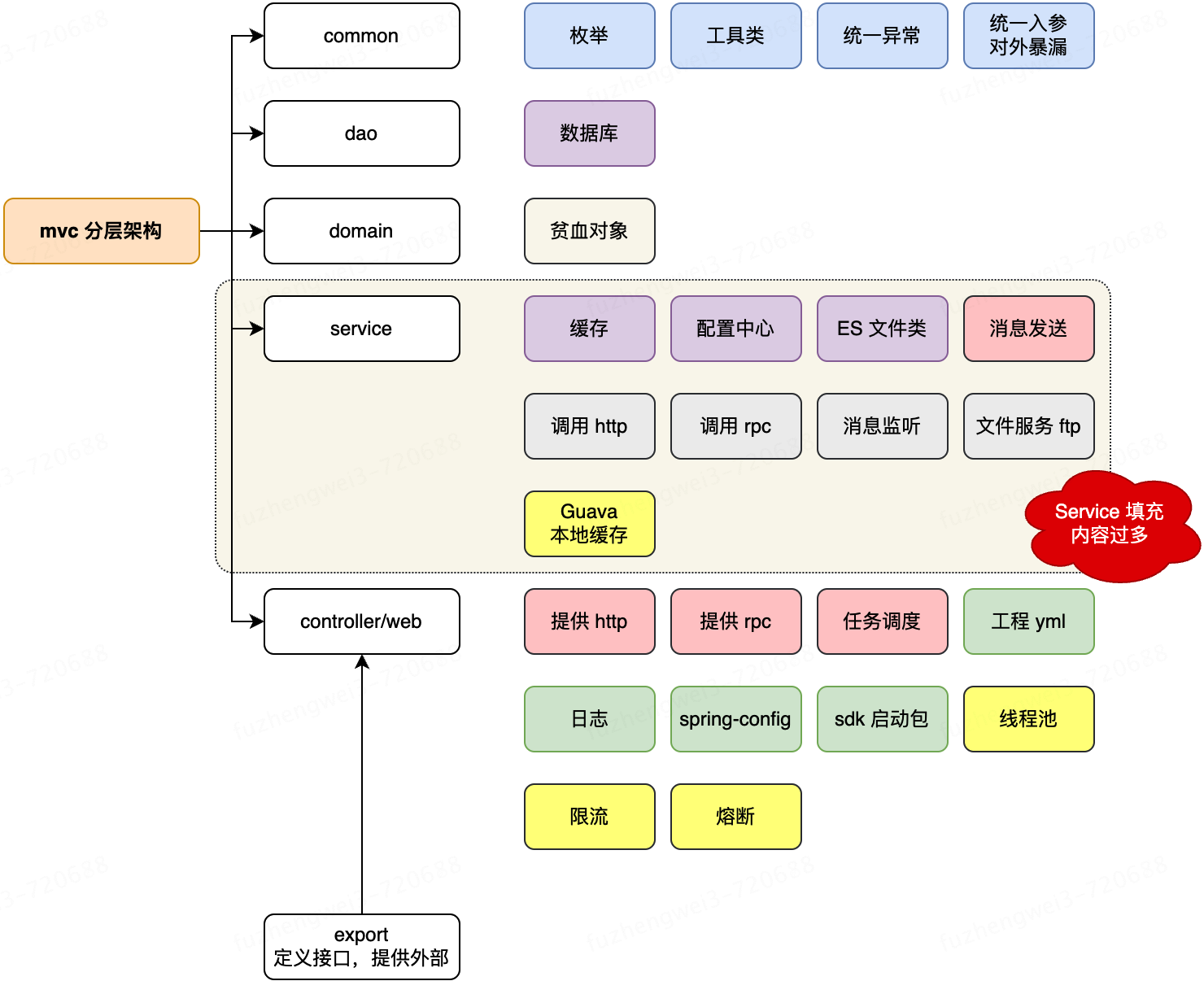
通用的、配置的、组件的、持久化的、内部的、外部的,在以往的单体应用时代开发下,其实是没有这么多东西的,那时候的工程结构都偏向于 Service + 贫血模型实现。
但随着微服务的演进,越来越多的内容被填充到工程中,这个时候你细心的查看架构,就会发现原本的 MVC 结构其实已经变的非常混乱了。一个 Service 中为了实现自己的功能,要引入一堆的东西,这些原子的功能与 Service 自身的服务耦合在一块。也导致了工程的维护成本越来越大。
这样的三层工程结构分配方式,对于要承载庞大的分布式技术栈体系显然是有点小马拉大车,三缸机带不动SUV一样。
2、工程结构设计
2004年,Eric Evans 在发表了一部名为《Domain Driven Design》的著作。2005年 Alistair Cockburn 提出的“六边形关系图”理论,2008年 Jeffrey Palermo 提出了洋葱架构。虽然这些架构并不是专门为 DDD 而出,但巧的是这些架构都在 DDD 一书发表之后陆续推出新的架构模型。同时这些架构的分层设计方式也都与 DDD 非常契合,在这些架构下也可以很好的落地 DDD 设计方法。
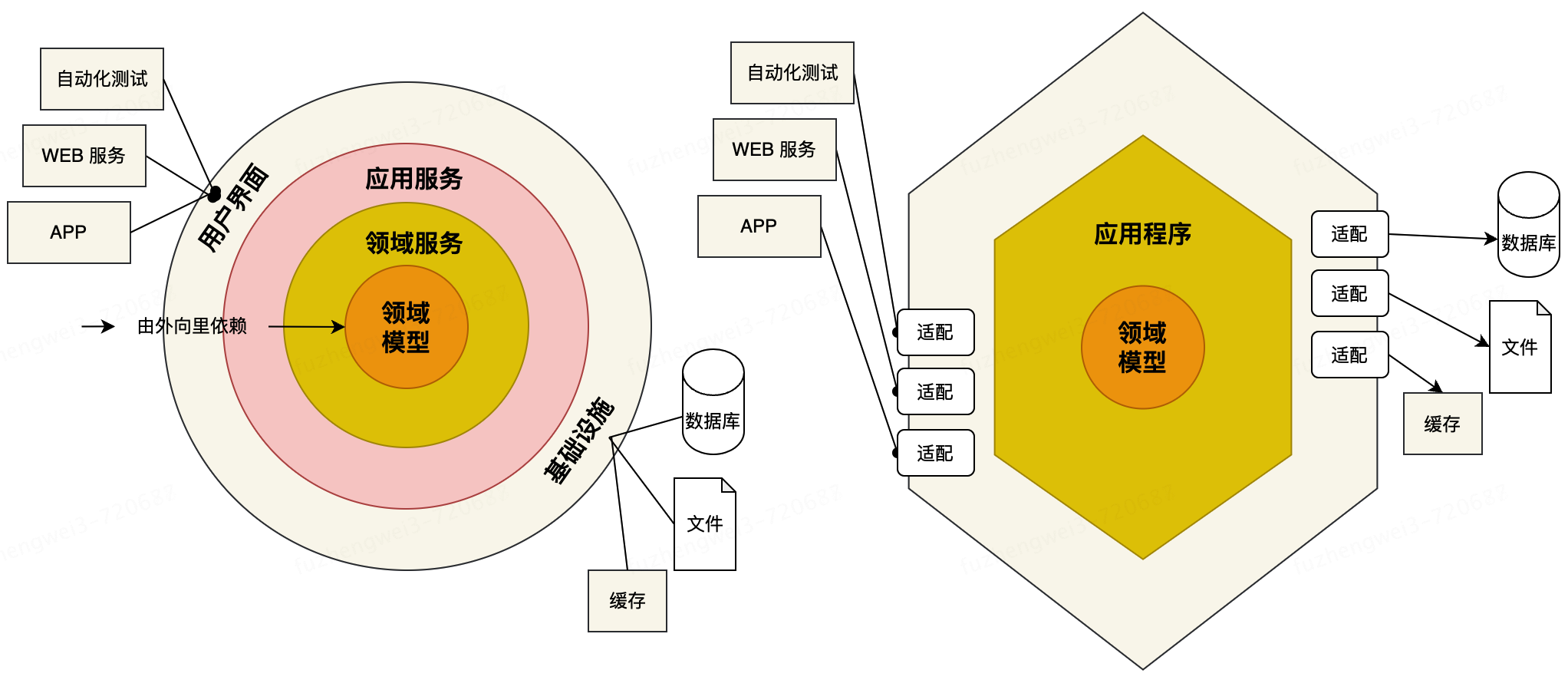
无论是六边形架构,还是洋葱架构,或是张毅老师提到的南向网关/北向网关的菱形架构,他们的目标都是以领域服务为核心,隔离内部实现与外部资源的耦合。
在 DDD 分层架构下,以支撑 domain 核心领域实现拆分出基础设施(infrastructure),来承接对外部资源的调用。触发器(trigger)向外部提供服务。之后 app 为应用启动、api 为接口定义、types 为通用信息、case 为编排。
在这样一套结构下,用于开发工程的各项科目也可以被优雅的分配到各个分层结构了。相对于 Service + 数据模型的贫血模型结构,现在就主要以 domain 为核心开发业务功能,不会在 domain 工程模块下,引入其他各类外部组件了,这样就可以更加关心业务功能开发。
之后是这样的思想映射到工程中,常见的分层结构会有两套,一套是整洁分层,另外一套是六边形分层。
2.1、整洁架构-工程结构
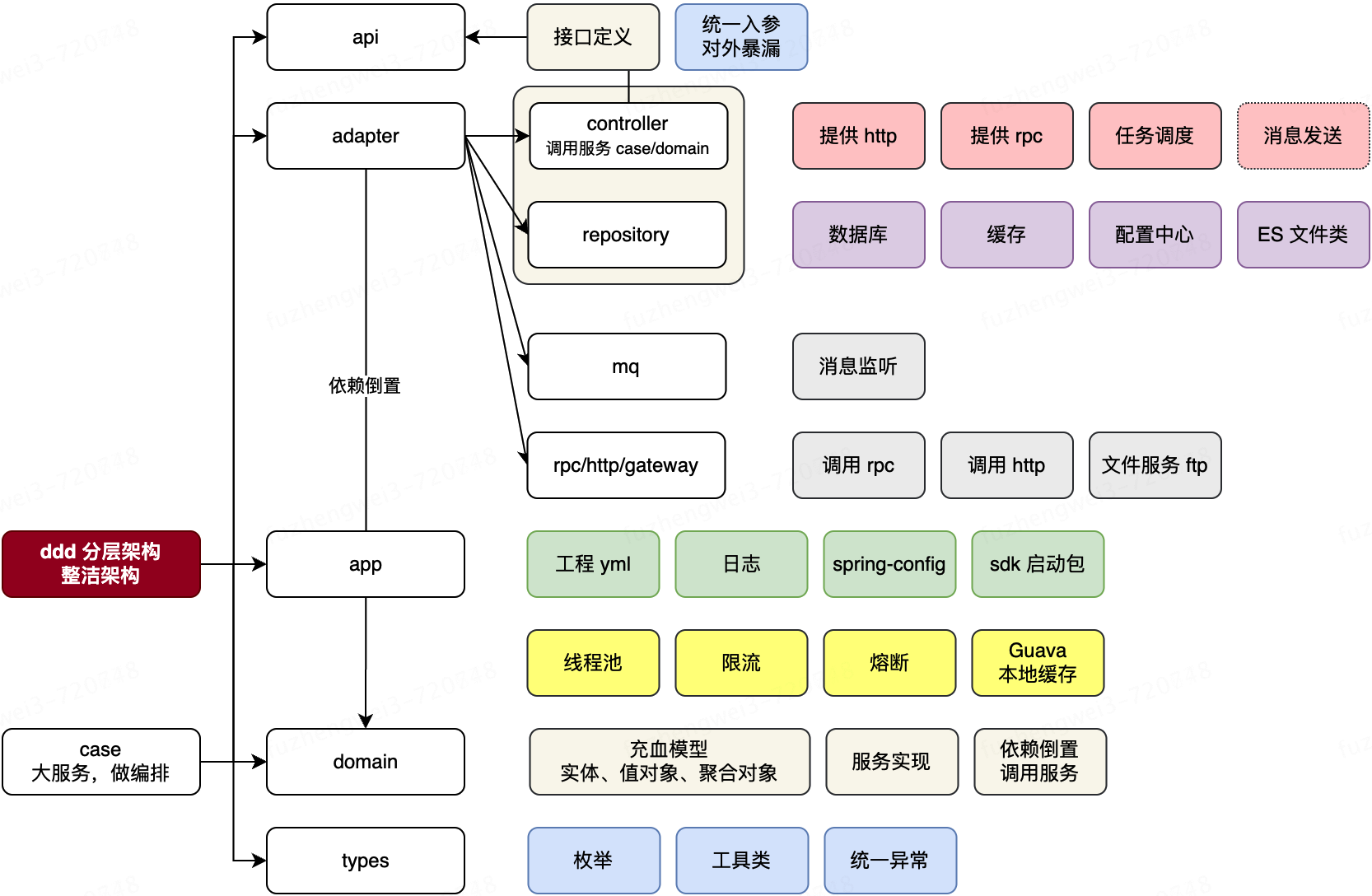
整洁架构的分包形式,会将所有的外部依赖使用和工程内要对外的,统一定义到适配器层。这里可以理解为对适配和对内适配。
阿里的 cola 偏整洁架构 阿里架构 cola 的相关内容
cola 偏整洁架构:https://developer.aliyun.com/article/1321732?spm=5176.26934562.main.1.35977d9cwAhASM
2.2、六边形架构-工程结构

六边形架构,会把本身提供到外部的放到trigger,让接口调用、消息监听、任务调度,都可以统一一个入口处理。而对于需要调用外部同类的能力统一放到 infrastructure 基础设施层,包括;数据库、缓存、配置、调用其他方的接口。
3、领域模型设计
虽然大家用的都是 DDD,也都有对应的模块和分包,但在细节之处还是会有一些差异。就像家里的家庭成员,衣服、裤子、鞋子,是所有人的衣服都放一起,还是每个人有独立的衣柜只放自己的。这块是有差异的。另外这东西没有绝对的好和坏,就像厨房里的碗筷是是放一起的,卫生间的马桶也是共用的,这说明分包也是需要按照最符合自己所需来设定。
3.1、分包方式
如下是两种分包方式:

- 方式1;DDD 领域科目类型分包,类型之下写每个业务逻辑。
- 方式2;业务领域分包,每个业务领域之下有自己所需的 DDD 领域科目。
比如,你现在一个工程下有用户、积分、抽奖、支付,(紧凑的聚合类微服务有时候更易于维护),那么这些包一种是分为独立的业务包方式2这种,另外一种就是大家都在一个坛子里吃饭,要啥去各个地方找。所以你更倾向于那种呢?
3.2、领域模型
DDD 领域驱动设计的中心,主要在于领域模型的设计,以领域所需驱动功能实现和数据建模。一个领域服务下面会有多个领域模型,每个领域模型都是一个充血结构。一个领域模型 = 一个充血结构

- model 模型对象;
- aggreate:聚合对象,实体对象、值对象的协同组织,就是聚合对象。
- entity:实体对象,大多数情况下,实体对象(Entity)与数据库持久化对象(PO)是1v1的关系,但也有为了封装一些属性信息,会出现1vn的关系。
- valobj:值对象,通过对象属性值来识别的对象 By 《实现领域驱动设计》
- repository 仓储服务;从数据库等数据源中获取数据,传递的对象可以是聚合对象、实体对象,返回的结果可以是;实体对象、值对象。因为仓储服务是由基础层(infrastructure) 引用领域层(domain),是一种依赖倒置的结构,但它可以天然的隔离PO数据库持久化对象被引用。
- service 服务设计;这里要注意,不要以为定义了聚合对象,就把超越1个对象以外的逻辑,都封装到聚合中,这会让你的代码后期越来越难维护。聚合更应该注重的是和本对象相关的单一简单封装场景,而把一些重核心业务方到 service 里实现。此外;如果你的设计模式应用不佳,那么无论是领域驱动设计、测试驱动设计还是换了三层和四层架构,你的工程质量依然会非常差。
- 对象解释
- DTO 数据传输对象 (data transfer object),DAO与业务对象或数据访问对象的区别是:DTO的数据的变异子与访问子(mutator和accessor)、语法分析(parser)、序列化(serializer)时不会有任何存储、获取、序列化和反序列化的异常。即DTO是简单对象,不含任何业务逻辑,但可包含序列化和反序列化以用于传输数据。
4、分层调用链路
接下来我们把 DDD 的分层架构平铺展开,看看从一个接口的实现到各个模块分层中的调用链路关系是什么样的。这样在做自己的代码开发中也可以参考到应该把什么的功能分配到哪个模块中处理。

从APP层、触发器层、应用层,这三块主要对领域层的上下文逻辑封装、触发式(MQ、HTTP、JOB)使用,并最终在应用层中打包发布上线。这一部分的都是使用的处理,所以也不会有太复杂的操作。
当进入领域层开始,也是智力集中体现的开始了。所有你对工程的抽象能力,都在这一块区域体现。