
K8S部署Flink集群环境
- 1、K8S部署Flink集群环境
- 2、集群搭建
- 3、k8s问题排查
- 4、搭建私有docker仓库
1、K8S部署Flink集群环境
命令:
https://zhuanlan.zhihu.com/p/423527602
https://blog.csdn.net/m0_56137272/article/details/128727947
1.1、k8s基本资源对象
k8s能分布式的部署并且管理我们的系统。
1.1.1、POD
概念:
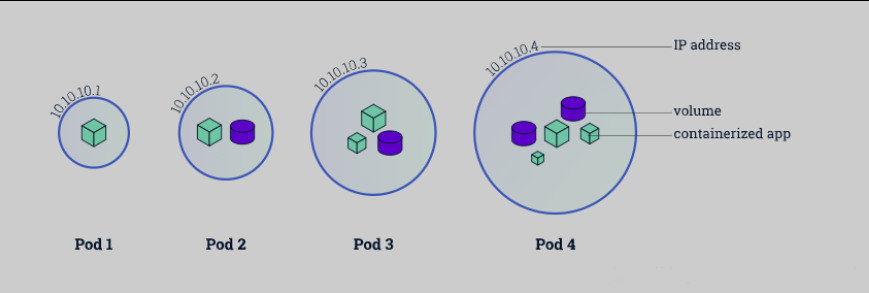
Pod 是 Kubernetes 中的最小部署单元,通常包含一个或多个容器。Pod 共享相同的网络命名空间和存储,它们在同一主机上启动,可以轻松地通信。
作用:
Pod 用于托管应用程序容器。它们提供了一个独立的环境,使容器可以运行在相同的上下文中,共享资源。
工作原理:
Pod 可以包含一个或多个容器,它们共享相同的 IP 地址和端口空间。Pod 的生命周期由容器的生命周期控制。如果 Pod 中的容器失败,Kubernetes 可以重新启动整个 Pod。
Namespace
Kubernetes 支持多个虚拟集群,它们底层依赖于同一个物理集群。这些虚拟集群被称为命名空间
Namespace适用于存在很多跨多个团队或项目的用户的场景。对于只有几到几十个用户的集群,根本不需要创建或考虑名字空间。当需要名称空间提供的功能时,开始使用它们。
Namespace多用于实现多租户资源隔离。Namespace 通过将集群内部的资源对象“分配”到不同的Namespace中,形成逻辑上分组的不同项目、小组或用户组。
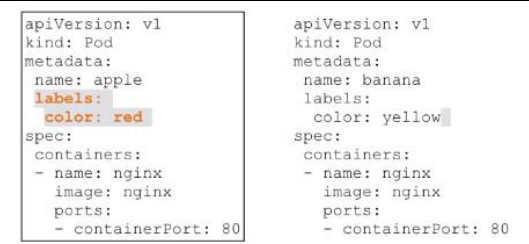
Label
Kubernetes 中的 Label实质是一系列的 Kev/Value键值对,其中 key与 value 可自定义。Label 可以附加到各种资源对象上,如 Node、Pod、Service、RC等。一个资源对象可以定义任意数量的Label,同一个Label也可以被添加到任意数量的资源对象上去。Kubernetes 通过 Label Selector(标签选择器)查询和筛选资源对象。
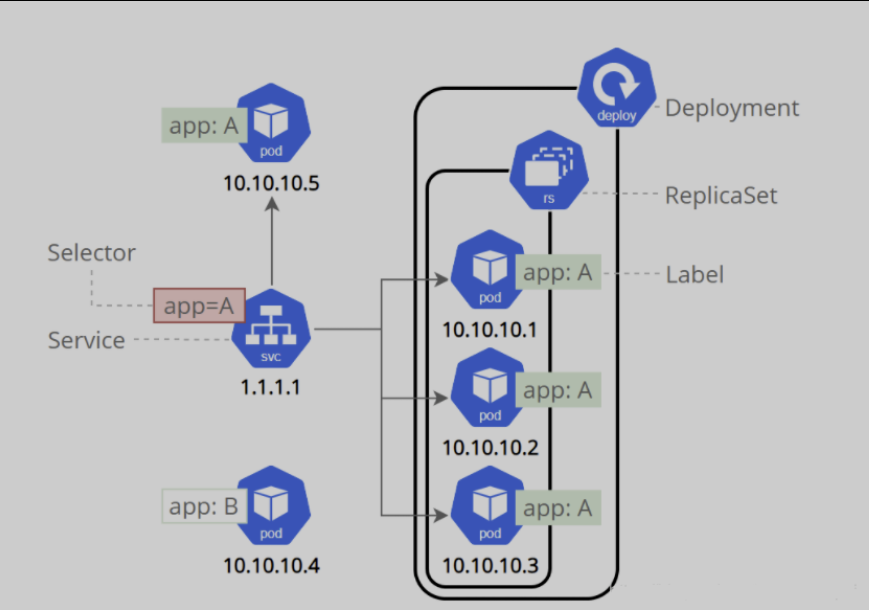
1.1.2、ReplicaSet
概念:
ReplicaSet 用于确保特定数量的 Pod 副本在集群中运行。如果有任何故障或调整,ReplicaSet 会自动调整副本数量。
作用:
ReplicaSet 用于维护容器应用程序的副本数量,确保高可用性和负载均衡。
工作原理:
ReplicaSet 根据定义的副本数量启动 Pod 副本。如果某个 Pod 失败或需要缩放,ReplicaSet 会自动启动或销毁 Pod。
1.1.3、Deployment
概念:
Deployment 是用于声明式管理应用程序部署的对象。它允许您定义所需的状态,Kubernetes 会自动将集群状态调整到所需状态。
作用:
Deployment 简化了应用程序的部署和更新,提供了滚动升级和回滚功能。
工作原理:
Deployment 通过创建 ReplicaSet 来管理 Pod。当需要进行升级时,Deployment 创建一个新的 ReplicaSet,逐步将流量切换到新的 ReplicaSet,并停止旧的 ReplicaSet。
1.1.4、Service
概念:
Service 定义了一组 Pod,并提供这组 Pod 的网络访问入口。Service 可以暴露内部或外部服务。
作用:
Service 用于提供负载均衡和服务发现,使应用程序能够轻松通信。
工作原理:
Service 使用标签选择器来确定将流量路由到哪些 Pod。它为这些 Pod 创建一个虚拟 IP 和 DNS 条目,使其他应用程序能够访问它们。
1.1.5、ConfigMap
概念:
ConfigMap 用于将配置数据与应用程序分开。它可以存储配置文件、环境变量和其他配置数据。
作用:
ConfigMap 使应用程序的配置更加灵活,允许在不重新构建容器的情况下修改配置。
工作原理:
ConfigMap 存储配置数据,然后将这些数据注入 Pod 中的容器中。容器可以将 ConfigMap 数据用作配置文件或环境变量。
1.1.6、StatefulSet
概念:
StatefulSet 是一种用于部署有状态应用程序的控制器。与 ReplicaSet 不同,StatefulSet 为每个 Pod 分配一个唯一的标识符,并支持有状态的持久化存储。
作用:
StatefulSet 适用于需要稳定网络标识和持久化存储的应用程序,如数据库。
工作原理:
StatefulSet 创建有序的 Pod,每个 Pod 都有一个唯一的标识符。这些标识符在 Pod 重新启动时保持不变,使有状态应用程序能够维护一致的标识和状态。
1.1.7、DaemonSet
概念:
DaemonSet 用于在集群中的每个节点上运行一个副本。这对于运行系统级任务或监控代理非常有用。
作用:
DaemonSet 用于确保每个节点都运行特定的 Pod 副本。
工作原理:
DaemonSet 为每个节点创建一个 Pod 副本,当节点加入或离开集群时,DaemonSet 会自动启动或停止相应的 Pod。
1.1.8、Job
概念:
Job 用于运行一次性任务,任务完成后会退出。如果任务失败,Job 可以选择重试。
作用:
Job 适用于批处理任务或需要仅运行一次的任务。
工作原理:
Job 创建一个或多个 Pod,这些 Pod 执行指定的任务。一旦任务完成,Pod 会被终止。
1.1.9、CronJob
概念:
CronJob 是一种基于时间的作业调度器,可以定期执行 Job。它使用类似于 Cron 表达式的时间规则。
作用:
CronJob 用于定期执行批处理任务,如备份或日志清理。
工作原理:
CronJob 根据时间规则创建 Job,这些 Job 定期运行指定的任务。
1.1.10、Horizontal Pod Autoscaler (HPA)
概念:
HPA 用于根据 CPU 使用率或其他指标自动扩展或缩小 Pod 的副本数量。
作用:
HPA 用于确保应用程序能够根据负载需求自动扩展,从而提供性能和可伸缩性。
工作原理:
HPA 监视定义的指标,并根据阈值自动增加或减少 Pod 的副本数量。
小结
1、工作负载型资源
这些资源就是K8S中承载具体的工作的一些资源,常见的类型有:Pod,ReplicaSet,Deployment,StatefulSet,DaemonSet,Job,Cronjon,...
2、服务发现及均衡型资源
这种类型的资源主要和服务相关,负责服务发现,调度等,常见的类型有:Service,Ingress,...
3、配置与存储相关资源:
这类型的资源主要和存储相关,常见类型有:Volume,CSI,ConfigMap,Secret,DownwardAPI,...
4、集群级资源
这类型资源主要提供集群的管理相关的功能,常见类型有:Namespace,Node,Role,ClusteRole,RoleBinding,ClusterRoleBinding
5、元数据型资源
这类型的资源主要提供元数据相关的功能,常见类型有:HPA,PodTemplate,LimitRange, ....
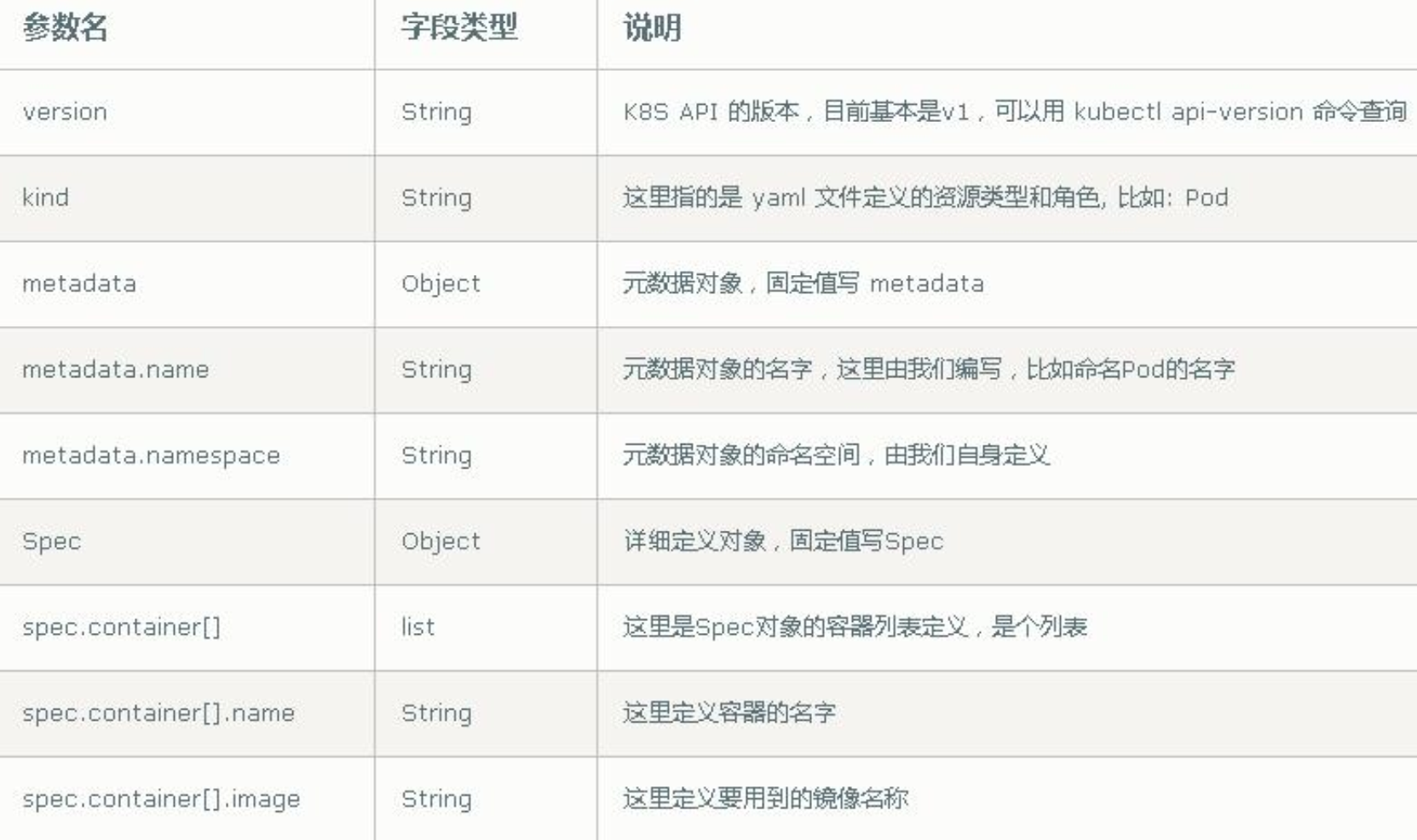
1.2、资源清单配置
1.2.1、一级资源
K8S中的APIServer在创建资源时采用JSON格式的数据,我们可以通过使用yaml格式的配置文件来提供配置,然后K8S内部自动帮我们转换为JSON格式,然后再提交。
资源配置清单关键字, 在一个配置清单中,有五个一级字段及多个下级字段组成,我们先来看下这几个一级字段:
1. apiVersion:[group]/version
APIServer使用分组来管理api,在创建资源配置清单的时候要指定此api属于哪个组,属于core组的资源,在定义时可以省略组名,使用kubectl api-server命令可以来获取api版本。
2、kind:资源类型
kind字段用来指定要管理的资源类型,资源类型如上所述。
3、metadata:元数据
metadata字段用来指定部分元数据,其有多个二级字段:
name:资源名称,在同一个类别中这个名称必须是唯一的
namespace:名称空间,资源所属的名称空间
labels:标签,每个标签都是一对键值对,一个资源可以拥有多个标签,一个标签也可以对应多个资源。标签可以在资源创建时指定,也可以在资源创建之后来管理标签。
标签定义格式:key=value,键名和键值最长长度为63个字符,其中:
key:由字母、数字、_、-、.组成,必须以字母开头
value:可以为空,只能以字母或数字开头或结尾,中间可以使用_、-、.在K8S中,通过标签选择器来筛选资源,其中,标签除了可以指定具体的键值外,还有如下类型:
等值关系:=,==,!=,集合关系:
KEY in (value1,value2,...) :KEY键值在某些集合中
KEY notin (value1,value2,...):KEY键值不在某些集合中
KEY: 存在键KEY
!KEY: 不存在键KEYannotations:注解,其与label不同的地方在于,它不能用于挑选资源对象,仅用于为对象提供元数据,其键和值没有长度限制:
spec
containers:指定容器相关配置,此字段是必填的,部分二级字段如下:
- name:容器名称
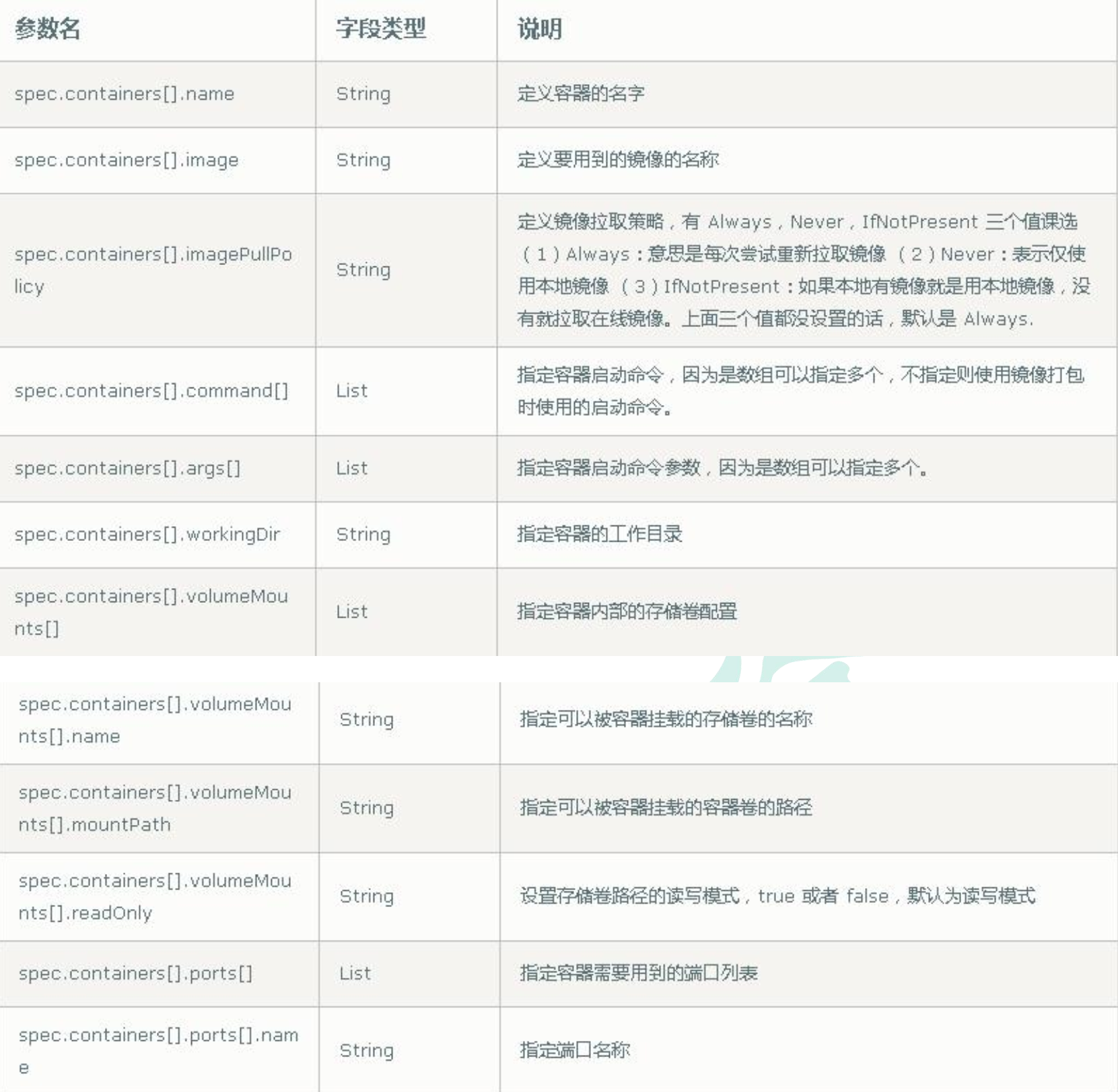
image:启动容器的镜像
imagePullPolicy: 拉取镜像策略,其有三个值可选:Always | Never | IfNotPresent
Always: 表示无论本地是否有镜像文件,每次创建资源时都去镜像仓库中拉取镜像
Never: 表示从不自动从镜像仓库中拉取镜像,启动时需要手动拉取镜像到本地
IfNotPresent: 表示如果本地有镜像时就使用本地镜像,本地没有时就自动去拉取
当不指定此配置时,如果镜像标签是 :latest 的时候,默认采用Always的方式拉取镜像,否则默认采用IfNotPresent方式拉取镜像。
ports:容器暴露的端口信息。在此处暴露端口可为系统提供有关容器使用的网络连接的信息,但仅仅是参考信息。如果在此处没有指定端口,也并不能保证容器没有暴露端口。任何监听容器中“0.0.0.0”地址的端口都可以被访问到。其下级还有如下字段:
- name:暴露端口的名字
containerPort:必填字段,暴露的容器端口号
protocol:协议栈,默认TCP协议,可选UDP,TCP,SCTP
command:容器运行的命令,用来指定替换容器默认的命令,command相当于Dockerfile中的Entrypoint,如果不指定该参数,那么就会采用镜像文件中的ENTRYPOINT指令。
args:entrypoint指令的参数列表,如果不指定这个参数,则使用镜像中的CMD指令
command和args参数分别对应镜像中的ENTRYPOINT和CMD指令,此时就出现如下几种情况:
a、command和args都未指定:运行镜像中的ENTRYPOINT和CMD指令
b、command指定而args未指定:只运行command指令,镜像中的ENTRYPOINT和CMD指令都会被忽略
c、command未指定而args指定:运行镜像中的ENTRYPOINT指令且将args当做参数传给ENTRYPOINT指令且镜像中的CMD指令被忽略
d、command和args都指定:运行command指令,并把args当做参数传递给command,镜像中的ENTRYPOINT和CMD指令都会被忽略
livenessProbe:POD容器存活状态监测,检测探针有三种,ExecAction、TCPSockerAction、HttpGetAction
exec:命令类型探针
command:执行的探测命令,命令运行路径是容器内系统的/,且命令并不会运行在shell中,所以,需要我们手动指定运行的shell,当命令返回值是0时表示状态正常,反之表示状态异常
httpGet:http请求型探针
host:请求的主机地址,默认是POD IP
httpHeaders:HTTP请求头
path:请求的URL
port:请求的端口,必填项
scheme:请求协议,默认是http
tcpSocket:TCP socket型探针
host:请求的主机地址,默认是POD IP
port:请求的端口号,端口范围是1-65535
failureThreshold:连续错误次数,默认3次,即默认连续3次检测错误才表示探测结果为异常
successThreshold:连续成功次数,默认1次,即当出现失败后,出现连续1次检测成功就认为探测结果是正常
periodSeconds:探测时间间隔,默认10秒
timeoutSeconds:探测超时时间,默认1秒
initialDelaySeconds:起始探测时间间隔,表示pod启动后,该间隔之后才开始进行探测
readinessProbe:主容器内进程状态监测,其可用的检测探针类型和livenessProbe是一致的
此检测和service调度有很强的关联性,
当新调度一个pod时,如果没有指定就绪性检测,此时一旦pod创建就会立即被注册到service的后端
如果此时pod内的程序尚无法对外提供服务,就会造成部分请求失败
所以,我们应该让一个pod在注册到service中区之前,已经通过了可用性检测,保证可以对外提供服务
lifecycle:生命周期钩子方法
postStart:容器启动后执行的命令,可用检测探针和livenessProbe是一致的
preStop:容器启动前执行的命令
restartPolicy:重启策略,Always, OnFailure,Never. Default to Always.
nodeSelector:node选择器,可以根据node的标签选择POD运行在某些指定的node上
nodeName:使pod运行在指定nodeName的节点之上5、status:状态字段
status字段描述了当前状态信息,本字段由k8s集群维护
资源配置清单有很多字段,无法一一介绍,K8S也为我们提供了查看这些字段的命令:kubectl explain 资源类别[.字段名],此命令可以为我们提供当前资源类别的定义方式,如果需要知道具体的某一个字段如何定义,可以使用kubectl explain资源类别.字段名,如:
[root@k8s7-22 ~]# kubectl explain pod.metadata.clusterName
KIND: Pod
VERSION: v1
FIELD: clusterName <string>
DESCRIPTION:
The name of the cluster which the object belongs to. This is used to
distinguish resources with same name and namespace in different clusters.
This field is not set anywhere right now and apiserver is going to ignore
it if set in create or update request.案例
编排资源文件:
[root@k8s7-200 manifests]# cat pod-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-demo # pod名称
namespace: default # pod资源所属的namespace
labels: # 标签
app: myapp
tier: frontend
spec:
containers: # 定义容器
- name: myapp # 启动第一个容器,名为myapp
image: harbor.od.com/public/myapp:v1 # 启动容器需要使用的镜像文件
- name: busybox # 启动第二个容器为busybox
image: harbor.od.com/public/busybox:latest # 第二个容器的镜像
command: # 自定义在第二个容器中执行的命令
- "/bin/sh"
- "-c"
- "sleep 3600"然后使用这个资源配置清单来创建资源,我们的资源配置清单可以放在服务器本地,也可以放在资源站上,创建的时候直接指定这个资源配置清单的URL即可:
kubectl create -f http://k8s-yaml.od.com/manifests/pod-demo.yaml
pod/pod-demo created1.2.2、不同资源yaml文件编排
pod资源yaml文件详解
apiVersion: v1 #必选,版本号,例如v1
kind: Pod #必选,指定创建资源的角色/类型
metadata: #必选,资源的元数据/属性
name: string #必选,资源的名字,在同一个namespace中必须唯一
namespace: string #必选,Pod所属的命名空间
labels: #自定义标签,使这个标签在service网络中备案,以便被获知
- name: string #自定义标签名字
annotations: #设置自定义注解列表
- name: string #设置自定义注解名字
spec: #必选,设置该资源的详细定义
containers: #必选,Pod中容器列表
- name: string #必选,容器名称
image: string #必选,容器的镜像名称
imagePullPolicy: [Always | Never | IfNotPresent] #获取镜像的策略 Alawys表示下载镜像 IfnotPresent表示优先使用本地镜像,否则下载镜像,Nerver表示仅使用本地镜像
command: [string] #容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] #容器的启动命令参数列表
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器内部的存储卷配置
- name: string #引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean #是否为只读模式
ports: #需要暴露的端口库号列表
- name: string #端口号名称
containerPort: int #容器需要监听的端口号
hostPort: int #容器所在主机需要监听的端口号,默认与Container相同
protocol: string #端口协议,支持TCP和UDP,默认TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量的值
resources: #资源限制和请求的设置
limits: #资源限制的设置
cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数
memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #Cpu请求,容器启动的初始可用数量
memory: string #内存清楚,容器启动的初始可用数量
livenessProbe: #对Pod内个容器健康检查的设置,当探测无响应几次后将自动重启该容器,检查方法有exec、httpGet和tcpSocket,对一个容器只需设置其中一种方法即可
exec: #对Pod容器内检查方式设置为exec方式
command: [string] #exec方式需要制定的命令或脚本
httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #对Pod内个容器健康检查方式设置为tcpSocket方式
port: number
initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒
periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一次
successThreshold: 0
failureThreshold: 0
securityContext:
privileged:false
restartPolicy: [Always | Never | OnFailure]#Pod的重启策略,Always表示一旦不管以何种方式终止运行,kubelet都将重启,OnFailure表示只有Pod以非0退出码退出才重启,Nerver表示不再重启该Pod
nodeSelector: obeject #设置NodeSelector表示将该Pod调度到包含这个label的node上,以key:value的格式指定
imagePullSecrets: #Pull镜像时使用的secret名称,以key:secretkey格式指定
- name: string
hostNetwork:false #是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络
volumes: #在该pod上定义共享存储卷列表
- name: string #共享存储卷名称 (volumes类型有很多种)
emptyDir: {} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string #Pod所在宿主机的目录,将被用于同期中mount的目录
secret: #类型为secret的存储卷,挂载集群与定义的secre对象到容器内部
scretname: string
items:
- key: string
path: string
configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
path: string点Deployment资源对象yaml详解
apiVersion: extensions/v1beta1
kind: Deployment
metadata: ----------------------------------------#元数据
annotations: -------------------------------------#注释信息
deployment.kubernetes.io/revision: '1'
k8s.kuboard.cn/ingress: 'false'
k8s.kuboard.cn/service: NodePort
k8s.kuboard.cn/workload: nextcloud
labels:-------------------------------------------#标签信息
k8s.kuboard.cn/layer: ''
k8s.kuboard.cn/name: nextcloud
name: nextcloud-----------------------------------#名称
namespace: nextcloud------------------------------#命名空间
spec:-----------------------------------------------#定义容器模板,该模板可以包含多个容器
replicas: 3---------------------------------------#副本数量
selector:-----------------------------------------#标签选择器
matchLabels:
k8s.kuboard.cn/layer: ''
k8s.kuboard.cn/name: nextcloud
strategy:-----------------------------------------#滚动升级策略
type: RollingUpdate-----------------------------#类型
rollingUpdate:----------------------------------#由于replicas为3,则整个升级,pod个数在2-4个之间
maxSurge: 25%---------------------------------#滚动升级时会先启动25%pod
maxUnavailable: 25%---------------------------#滚动升级时允许的最大Unavailable的pod个数
template: #镜像模板
metadata: ------------------------------------#元数据
labels:---------------------------------------#标签
k8s.kuboard.cn/layer: ''
k8s.kuboard.cn/name: nextcloud
spec: ------------------------------------------#定义容器模板,该模板可以包含多个容器
containers: ----------------------------------#容器信息
- name: nextcloud --------------------------#容器名称
image: '172.16.20.100/library/nextcloud:yan' #镜像名称
imagePullPolicy: Always ------------------#镜像下载策略
ports:
- name: http
containerPort: 80
protocol: TCP
env
resources: -------------------------------#CPU内存限制
limits: --------------------------------#限制cpu内存
cpu: 200m
memory: 200m
requests: ------------------------------#请求cpu内存
cpu: 100m
memory: 100m
securityContext: -------------------------#安全设定
privileged: true -----------------------#开启享有特权
volumeMounts: ----------------------------#挂载volumes中定义的磁盘
- name: html ---------------------------#挂载容器1
mountPath: /var/www/html
- name: session ------------------------#挂载容器1
mountPath: /var/lib/php/session
volumes: ------------------------------------#在该pod上定义共享存储卷列表
- name: html -------------------------------#共享存储卷名称 (volumes类型有很多种)
persistentVolumeClaim: -------------------#volumes类型为pvc
claimName: html -----------------------#关联pvc名称
- name: session
persistentVolumeClaim:
claimName: session
restartPolicy: Always ------------------------#Pod的重启策略
#Always表示一旦不管以何种方式终止运行,kubelet都将重启,
#OnFailure表示只有Pod以非0退出码退出才重启,
#Nerver表示不再重启该Pod
schedulerName: default-scheduler -------------#指定pod调度到节点Service资源对象yaml详解
apiVersion: v1
kind: Service
metadata: ---------------------------------#元数据
annotations: -----------------------------#注释信息
k8s.kuboard.cn/workload: nextcloud
labels: ----------------------------------#标签信息
k8s.kuboard.cn/layer: ''
k8s.kuboard.cn/name: nextcloud
name: nextcloud --------------------------#名称
namespace: nextcloud ---------------------#命名空间
spec: --------------------------------------#定义Service模板
clusterIP: 10.0.181.206 ------------------#指定svcip地址 不指定则随机
=================================================================================================
#NodePort类型:集群外网络
type: NodePort ---------------------------#类型为NodePort
ports:
- name: mnwwwp
nodePort: 30001 ----------------------#当type = NodePort时,指定映射到物理机的端口号
port: 80 -----------------------------#服务监听的端口号
protocol: TCP ------------------------#端口协议,支持TCP和UDP,默认TCP
targetPort: 80 -----------------------#需要转发到后端Pod的端口号
==================================================================================================
#ClusterIP类型:集群内网络
type: ClusterIP --------------------------#
ports:
- name: mnwwwp
port: 80
protocol: TCP
targetPort: 80
- name: j5smwx
port: 22
protocol: TCP
targetPort: 22
selector: -------------------------------#label selector配置,将选择具有label标签的Pod作为管理
k8s.kuboard.cn/layer: ''
k8s.kuboard.cn/name: nextcloud
sessionAffinity: None --------------------#是否支持session1.3、k8s集群搭建
Kubernetes 默认 CRI(容器运行时)为 Docker,因此先安装 Docker。
所有节点安装 Docker、kubeadm、kubelet、kubectl
kubelet:每一个节点的代理,需要开机启动,将代理的节点注册到集群当中。
kubectl:和k8s交互的客户端
1.3.1、安装docker
1.3.1.1、删除docker
卸载系统之前的 docker
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
sudo yum remove docker docker-common docker-selinux docker-engine
yum remove docker-ce docker-ce-cli containerd.io
查看docker的版本
docker version1.3.1.2、安装 Docker-CE
安装必须的依赖
sudo yum install -y yum-utils \
device-mapper-persistent-data \
lvm2
设置 docker repo 的 yum 位置
sudo yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
//相当于告诉服务器docker服务器下载的地址在哪里
查看yum中的docker列表
yum list docker-ce --showduplicates | sort -r
安装 docker,以及 docker-cli
sudo yum install -y docker-ce docker-ce-cli containerd.io
//默认安装最新版本,需要指定安装的版本
yum install docker-ce-<VERSION_STRING> docker-ce-cli-<VERSION_STRING> containerd.io
yum -y install docker-ce-18.09.9-3.el7 docker-ce-cli-18.09.9-3.el7 containerd.io
sudo yum install -y docker-ce-17.03.2.ce-1.el7.centos docker-ce-cli-17.03.2.ce-1.el7.centos containerd.io
-y 表示下载的时候自动输入yes,不需要手工输入yes1.3.1.3、配置 docker 加速
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://82m9ar63.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart dockerdocker中正在运行着的容器:docker ps
1.3.1.4、启动 docker & 设置 docker 开机自启
systemctl enable docker
给docker降级的命令
yum downgrade --setopt=obsoletes=0 -y docker-ce-18.09.9-3.el7 docker-ce-cli-18.09.9-3.el7 containerd.io
查看docker版本
docker versionk8s运行的集群,必须要容器环境,所以需要设置docker容器开机启动。
1.3.2、添加阿里云 yum 源
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF安装k8s需要告诉镜像地址,所以添加阿里云镜像地址。
1.3.3、安装 kubeadm,kubelet 和 kubectl
//检查yum中是否有kube安装源
yum list|grep kube
//指定安装版本
yum install -y kubelet-1.17.3 kubeadm-1.17.3 kubectl-1.17.3
//设置代理服务开机启动
systemctl enable kubelet
systemctl start kubelet
查看服务的状态
systemctl status kubelet1.3.4、部署 k8s-master
master 节点初始化
kubeadm init \
--apiserver-advertise-address=192.168.47.100 \ apiserver的地址,这个服务在master上,所以需要指定master的ip地址
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
--kubernetes-version v1.17.3 \
--service-cidr=10.96.0.0/16 \ service的网络地址,提供负载均衡能力
--pod-network-cidr=10.244.0.0/16 pod之间的网络地址
k8s的初始化需要下载很多镜像,所以指定image下载地址为国内
kubeadm init \
--apiserver-advertise-address=192.168.47.100 \
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
--kubernetes-version v1.17.3 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=10.244.0.0/16
执行初始化时候可能会报错;
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR Port-6443]: Port 6443 is in use
[ERROR Port-10259]: Port 10259 is in use
[ERROR Port-10257]: Port 10257 is in use
[ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists
[ERROR Port-10250]: Port 10250 is in use
[ERROR Port-2379]: Port 2379 is in use
[ERROR Port-2380]: Port 2380 is in use
[ERROR DirAvailable--var-lib-etcd]: /var/lib/etcd is not empty
重新启动服务然后初始化:
kubeadm reset //重启kubeadm
master节点启动成功:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
//每次reset后需要重新删除.kube目录中的配置,然后再再次创建配置
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.47.100:6443 --token 2tjpo4.2gnfo4klpt0233fe \
--discovery-token-ca-cert-hash sha256:f6dc92c94d69fc8de732b24081dc1e4fd9fe5d320443795068c57e35a4250fcd
--------------
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.47.100:6443 --token zy22qm.56z0auyft6u4g9tx \
--discovery-token-ca-cert-hash sha256:1ae4db747061106ec55b4b3be25421d9df4f24dfcd861f1dc506f22f1bdd17abkubeadm reset命令:https://kubernetes.io/zh-cn/docs/reference/setup-tools/kubeadm/kubeadm-reset/
由于默认拉取镜像地址 k8s.gcr.io 国内无法访问,这里指定阿里云镜像仓库地址。可以手动按照我们的 images.sh 先拉取镜像,地址变为 registry.aliyuncs.com/google_containers 也可以。
科普:无类别域间路由(Classless Inter-Domain Routing、CIDR)是一个用于给用户分配 IP
地址以及在互联网上有效地路由 IP 数据包的对 IP 地址进行归类的方法。
拉取可能失败,需要下载镜像。
运行完成提前复制:加入集群的令牌
shell脚本下载k8s所有依赖的镜像
#!/bin/bash
images=(
kube-apiserver:v1.19.3
kube-proxy:v1.17.3
kube-controller-manager:v1.17.3
kube-scheduler:v1.17.3
coredns:1.6.5
ctcd:3.4.3-0
pause:3.1
)
for imageName in ${images[@]} ; do
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName k8s.gcr.io/$imageName
doneshell中删除换行符的方法:https://blog.csdn.net/lovelovelovelovelo/article/details/79239068
sed -i 's/\n//g' FileName
yum install dos2unix
删除win下的\r:
dos2unix filename下载的所有镜像:docker images 查看所有的镜像
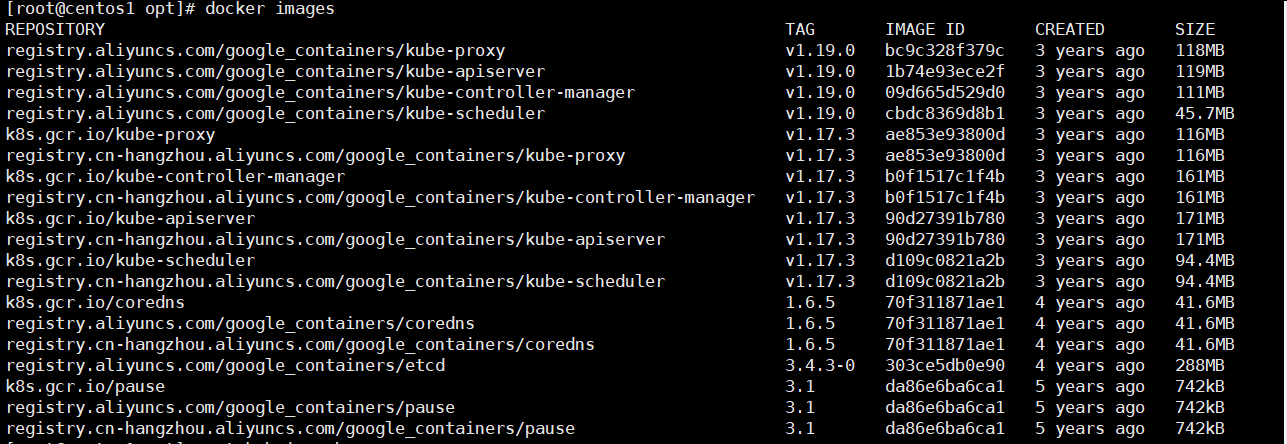
1.3.5测试 kubectl(主节点执行)
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config查看master节点的状态,pod之间通信的网络还没有初始化,所以下面执行网络的初始化。
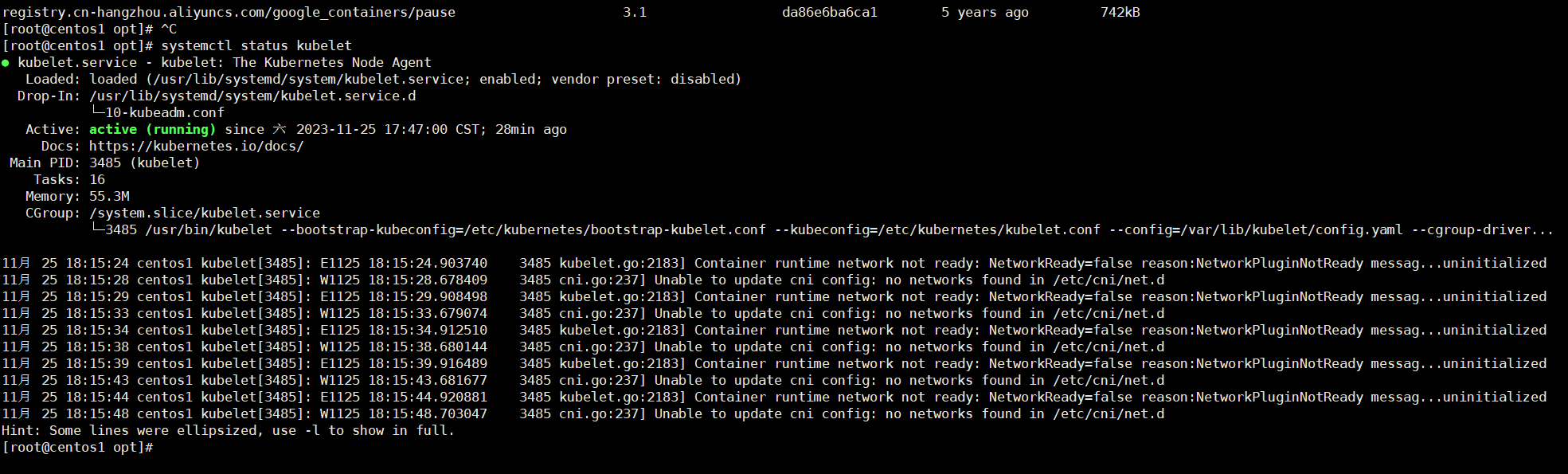 前 master 状态为 notready。等待网络加入完成即可。
前 master 状态为 notready。等待网络加入完成即可。
journalctl -u kubelet 查看 kubelet 日志
kubeadm join 10.0.2.15:6443 --token 8mgmlh.cgtgsp3samkvpksn \
--discovery-token-ca-cert-hash
sha256:3cf99aa2e6bfc114c5490a7c6dffcf200b670af21c5a662c299b6de606023f85应用网络:
kubectl apply -f kube-flannel.yml
删除kube-fl annel.yml文件中指定的所有资源:
kubectl delete -f kube-flannel.yml
---
kind: Namespace
apiVersion: v1
metadata:
name: kube-flannel
labels:
k8s-app: flannel
pod-security.kubernetes.io/enforce: privileged
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
labels:
k8s-app: flannel
name: flannel
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- apiGroups:
- ""
resources:
- nodes
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
- apiGroups:
- networking.k8s.io
resources:
- clustercidrs
verbs:
- list
- watch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
labels:
k8s-app: flannel
name: flannel
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: flannel
subjects:
- kind: ServiceAccount
name: flannel
namespace: kube-flannel
---
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: flannel
name: flannel
namespace: kube-flannel
---
kind: ConfigMap
apiVersion: v1
metadata:
name: kube-flannel-cfg
namespace: kube-flannel
labels:
tier: node
k8s-app: flannel
app: flannel
data:
cni-conf.json: |
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: kube-flannel-ds
namespace: kube-flannel
labels:
tier: node
app: flannel
k8s-app: flannel
spec:
selector:
matchLabels:
app: flannel
template:
metadata:
labels:
tier: node
app: flannel
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
hostNetwork: true
priorityClassName: system-node-critical
tolerations:
- operator: Exists
effect: NoSchedule
serviceAccountName: flannel
initContainers:
- name: install-cni-plugin
image: docker.io/flannel/flannel-cni-plugin:v1.2.0
command:
- cp
args:
- -f
- /flannel
- /opt/cni/bin/flannel
volumeMounts:
- name: cni-plugin
mountPath: /opt/cni/bin
- name: install-cni
image: docker.io/flannel/flannel:v0.22.3
command:
- cp
args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
containers:
- name: kube-flannel
image: docker.io/flannel/flannel:v0.22.3
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
resources:
requests:
cpu: "100m"
memory: "50Mi"
securityContext:
privileged: false
capabilities:
add: ["NET_ADMIN", "NET_RAW"]
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: EVENT_QUEUE_DEPTH
value: "5000"
volumeMounts:
- name: run
mountPath: /run/flannel
- name: flannel-cfg
mountPath: /etc/kube-flannel/
- name: xtables-lock
mountPath: /run/xtables.lock
volumes:
- name: run
hostPath:
path: /run/flannel
- name: cni-plugin
hostPath:
path: /opt/cni/bin
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg
- name: xtables-lock
hostPath:
path: /run/xtables.lock
type: FileOrCreate执行 kubectl -f apply kube-flannel.yml
[root@centos1 k8s]# kubectl apply -f kube-flannel.yml
namespace/kube-flannel created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds created
获取当前节点所有部署的最小单元pod,每一个pod都有自己的名称空间,所以必须要指定具体的名称空间。
查看所有的名称空间:kubectl get ns
查看所有名称空间下的pod:
kubectl get pods --all-namespaces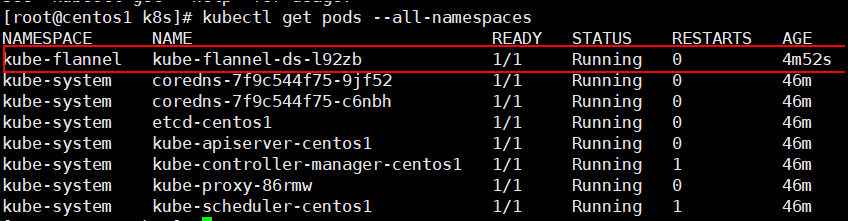
kube-flannel.yml 应用处于running状态,至此,集群的pod间网络通信部署成功。kube-flannel.yml 进程每一个节点都要有才可以通信。
获取集群中的所有节点:kubectl get nodes

master已经处于Ready状态。
让其他的节点加入集群中,在每一个节点上执行下面加入命令
kubeadm join 192.168.47.100:6443 --token 2tjpo4.2gnfo4klpt0233fe \
--discovery-token-ca-cert-hash sha256:f6dc92c94d69fc8de732b24081dc1e4fd9fe5d320443795068c57e35a4250fcd
计入节点的时候可能会报错:
[root@centos3 ~]# kubeadm join 192.168.47.100:6443 --token 2tjpo4.2gnfo4klpt0233fe --discovery-token-ca-cert-hash sha256:f6dc92c94d69fc8de732b24081dc1e4fd9fe5d320443795068c57e35a4250fcd
W1125 18:59:55.890449 11398 join.go:346] [preflight] WARNING: JoinControlPane.controlPlane settings will be ignored when control-plane flag is not set.
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR FileAvailable--etc-kubernetes-kubelet.conf]: /etc/kubernetes/kubelet.conf already exists
[ERROR FileAvailable--etc-kubernetes-pki-ca.crt]: /etc/kubernetes/pki/ca.crt already exists
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
执行:kubeadm reset 重新设置
然后重新启动kubeadm 服务:systemctl restart --now kubelet ; systemctl status kubelet.service --now
[root@centos3 ~]# systemctl restart --now kubelet ; systemctl status kubelet.service --now
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Drop-In: /usr/lib/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: active (running) since 六 2023-11-25 19:07:13 CST; 16ms ago
Docs: https://kubernetes.io/docs/
Main PID: 12272 (kubelet)
Tasks: 1
Memory: 376.0K
CGroup: /system.slice/kubelet.service
└─12272 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml
11月 25 19:07:13 centos3 systemd[1]: Started kubelet: The Kubernetes Node Agent.
11月 25 19:07:13 centos3 systemd[1]: Starting kubelet: The Kubernetes Node Agent...
重新加入节点即可成功:
[root@centos3 ~]# kubeadm join 192.168.47.100:6443 --token 2tjpo4.2gnfo4klpt0233fe --discovery-token-ca-cert-hash sha256:f6dc92c94d69fc8de732b24081dc1e4fd9fe5d320443795068c57e35a4250fcd
W1125 19:07:16.219801 12281 join.go:346] [preflight] WARNING: JoinControlPane.controlPlane settings will be ignored when control-plane flag is not set.
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.17" ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.现在集群中有三个节点,都处于Ready状态,说明集群启动成功。
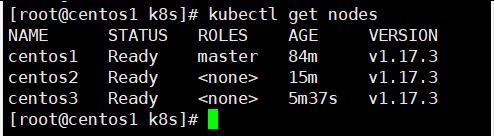
https://blog.csdn.net/m0_59267075/article/details/127781899
在 Node 节点执行。向集群添加新节点,执行在 kubeadm init 输出的 kubeadm join 命令:确保 node 节点成功
token 过期怎么办?
kubeadm token create --print-join-command
kubeadm token create --ttl 0 --print-join-command
kubeadmjoin--tokeny1eyw5.ylg568kvohfdsfco--discovery-token-ca-cert-hash
sha256: 6c35e4f73f72afd89bf1c8c303ee55677d2cdb1342d67bb23c852aba2efc7c73执行 watch kubectl get pod -n kube-system -o wide 监控 pod 进度,等 3-10 分钟,完全都是 running 以后使用 kubectl get nodes 检查状态.
集群中的所有pod:
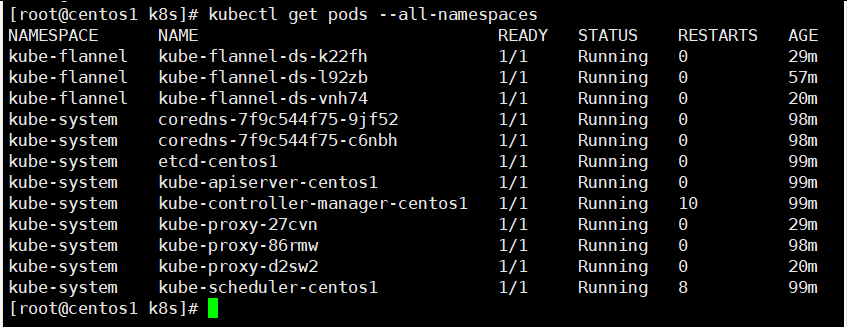
除master的其他节点,默认是不能够执行 kubectl get pods命令。
获取集群上的所有资源:kubectl get all
获取集群上资源的详细信息:kubectl get all -o wide
kubectl get pods --all-namespace:默认系统的pod服务都在kube-system名称空间下。部署的应用,如果不指定都在default默认名称空间下。kubectl get pods -o wide 默认获取default名称空间下的pod信息。一个部署会涉及到多种资源,pod,service,deployment等多种资源。
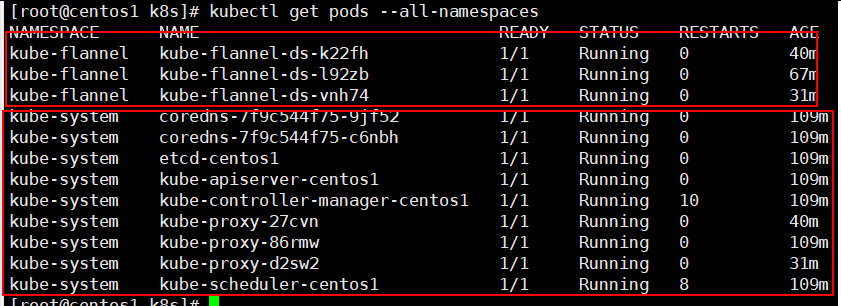
流程;创建 deployment 会管理 replicas,replicas 控制 pod 数量,有 pod 故障会自动拉起 新的 pod,k8s对资源的获取都可以写成ymal文件。
1.3.6、部署tomcat
- 部署一个 tomcat
kubectl create deployment tomcat6 --image=tomcat:6.0.53-jre8
Kubectl get pods -o wide 可以获取到 tomcat 信息- 暴露 nginx 访问
kubectl expose deployment tomcat6 --port=80 --target-port=8080 --type=NodePort
Pod 的 80 映射容器的 8080;service 会代理 Pod 的 80
--target-port=8080:指的是pod里面的容器暴露端口是8080
--port=80:访问pod使用的是80端口
将整个pod作为service作为一个服务暴露出去,使用的是:--type=NodePort 模式 随机分配端口,也可以指定端口
// 获取所有的service
kubectl get svc
kubectl get svc -o wide- 动态扩容
kubectl get deployment
应用升级 kubectl set image (--help 查看帮助)
扩容: kubectl scale --replicas=3 deployment tomcat6
扩容了多份,所有无论访问哪个 node 的指定端口,都可以访问到 tomcat6- 删除资源
Kubectl get all
kubectl delete deploy/nginx 删除部署,也会直接删除pod信息,但是service不会删除
kubectl delete service/nginx-service流程;创建 deployment 会管理 replicas,replicas 控制 pod 数量,有 pod 故障会自动拉起新的 pod
1.4、K8s基础
1.4.1、文档地址
kubectl 文档
https://kubernetes.io/zh-cn/docs/reference/kubectl/
k8s资源类型:
https://kubernetes.io/zh-cn/docs/reference/kubectl/#%E8%B5%84%E6%BA%90%E7%B1%BB%E5%9E%8B
格式化输出:
https://kubernetes.io/zh-cn/docs/reference/kubectl/#%E6%A0%BC%E5%BC%8F%E5%8C%96%E8%BE%93%E5%87%BA
常用操作:
命令参考:
https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands
1.4.2、yaml

- apiVersion:api版本信息
- kind:资源类型
- metaData:元数据
- spec:所操作资源的规格定义
输出标准yaml文件:
kubectl expose deployment tomcat6
--port=80
--target-port=8080 容器暴露的端口
--type=NodePort --dry -o yaml > service.yaml 输出文件内容重定向到service.yaml文件中命令:https://kubernetes.io/zh-cn/docs/reference/kubectl/#示例-��%
cubectl get pods 查看所有的pod
cubectl get pod name //查看pod名字为name的服务的信息
cubectl get pod name -o yaml 查看pod名字为name的pod的定义信息
应用yaml文件
bubectl apply -f app.yaml精简yaml文件:
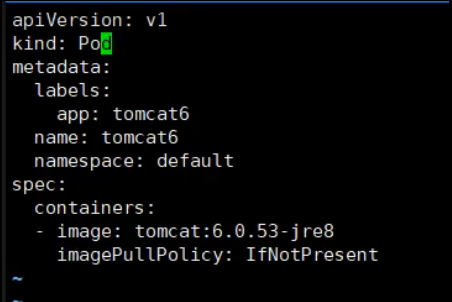
kind:资源类型pod类型
labels:指定pod的名字
image:指定镜像
imagePullPolicy:镜像拉取策略
Pod 是什么,Controller (工作负载资源)是什么 ?
https://kubernetes.io/zh-cn/docs/concepts/workloads/pods/#pods-and-controllers
Pod 和控制器
控制器可以为您创建和管理多个 Pod,管理副本和上线,并在集群范围内提供自修复能力,主要用来控制pod是如何部署的。 例如,如果一个节点失败,控制器可以在不同的节点上调度一样的替身来自动替换 Pod。 包含一个或多个 Pod 的控制器一些示例包括:
- Deployment :创建一个部署,指定副本上线
- StatefulSet :有状态的应用部署
- DaemonSet :让每一个节点都部署一个服务有,比如日志收集。
控制器通常使用您提供的 Pod 模板来创建它所负责的 Pod
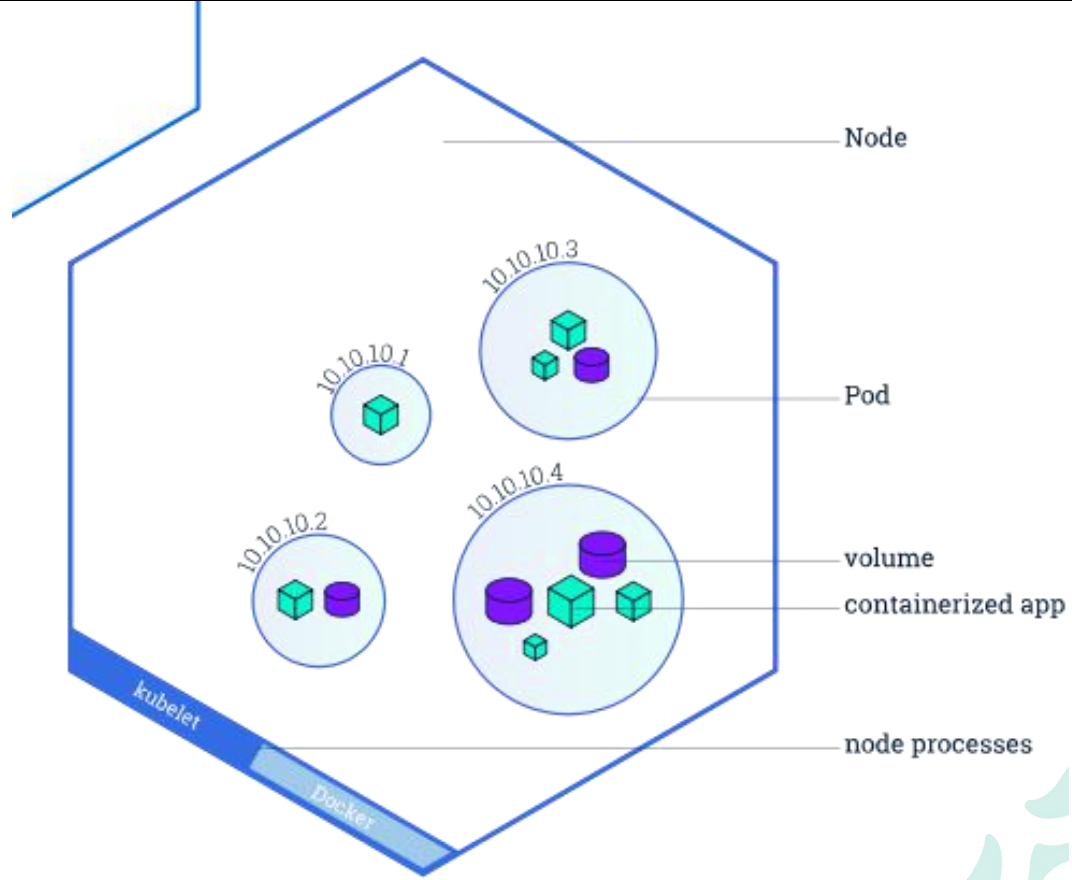
pod是k8s最小的运行单元,一个node节点内运行非常多的程序,每个程序都是以pod方式部署,pod内部可能有多个容器,pod之间可能会共享操作文件夹等,pod之间会有网络连通。这是k8s内部的操作。
Deployment&Service 是什么
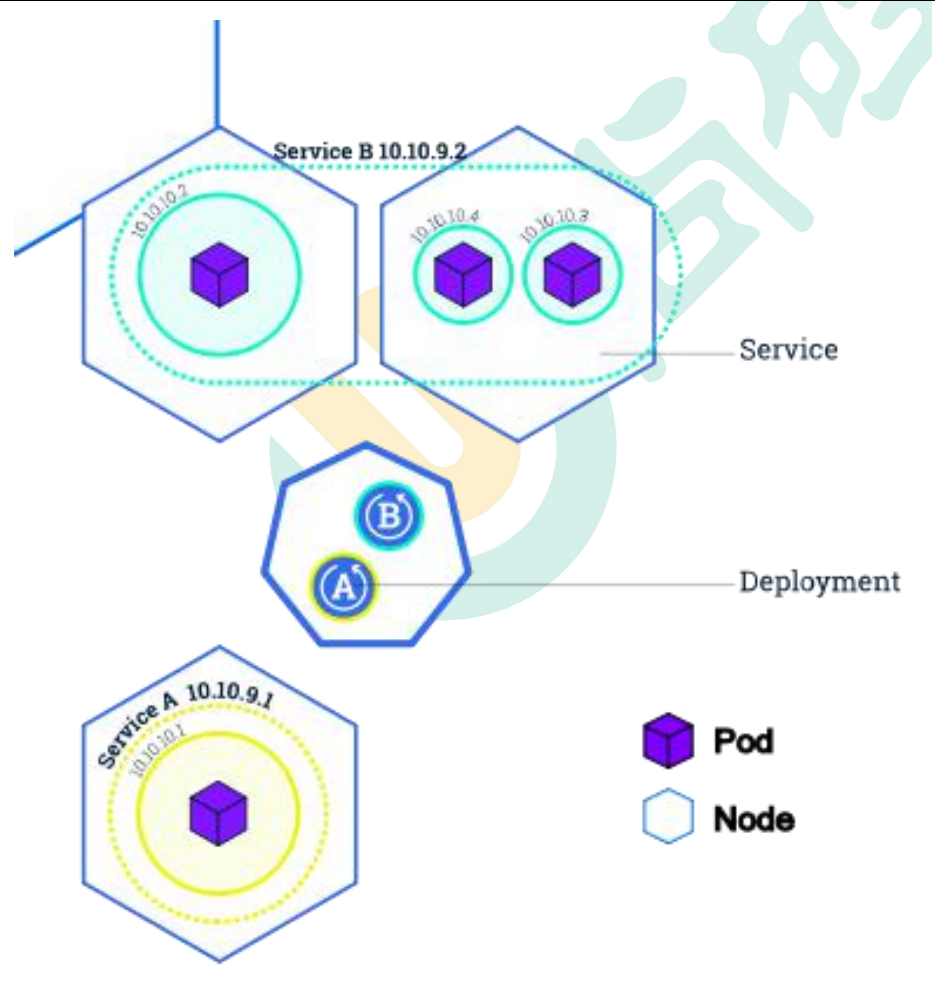
service也有网络地址,节点内部的所有pod是可以相互连接的,节点之间的pod要想相互访问,就需要组成一个service,提供网络地址访问,service会自动将请求转到你内部的pod访问,所以service相当于是对pod的负载均衡。
Service 的意义
1、部署一个 nginx kubectl create deployment nginx --image=nginx
2、暴露 nginx 访问 kubectl expose deployment nginx --port=80 --type=NodePort
统一应用访问入口;
Service 管理一组 Pod。
防止 Pod 失联(服务发现)、定义一组 Pod 的访问策略
现在 Service 我们使用 NodePort 的方式暴露,这样访问每个节点的端口,都可以访问到这 个 Pod,如果节点宕机,就会出现问 。
节点内部的所有pod是可以相互ping通的。不同节点之间的访问,需要组成一个service.
labels and selectors
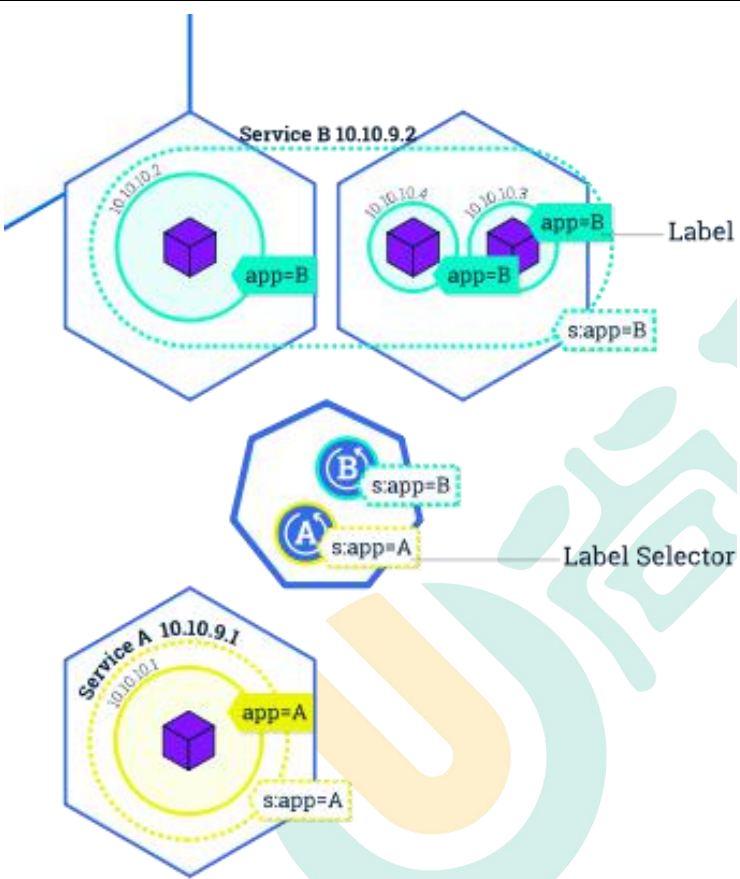
labels:定义一些kv标签,给pod打上标签,可以根据标签进行选择不同的pod部署或者组成不同的service.
完整的一次部署:
- 创建一个部署
kubectl
create deployment 创建一个部署
tomcat6 服务的名字
--image=tomcat:6.0.53-jre8 指定镜像地址
yaml文件写法:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: tomcat6
name: tomcat6
spec:
replicas: 3
selector:
matchLabels:
app: tomcat6
spec:
containers:
- image: tomcat:9.0.53-jre8
name: tomcat执行上面的yaml文件完成创建部署:
kubectl apply -f app.yaml
执行完成上面的脚本后,就在节点上启动了三个pod实例运行tomcat6服务, 执行完部署将会有三个pod部署在不同节点。
为了让三个pod可以对外界使用,使用下面命令暴露service.
kubectl expose deployment tomcat6
--port=80
--target-port=8080 容器暴露的端口
--type=NodePort --dry -o yaml > service.yaml 输出文件内容重定向到service.yaml文件中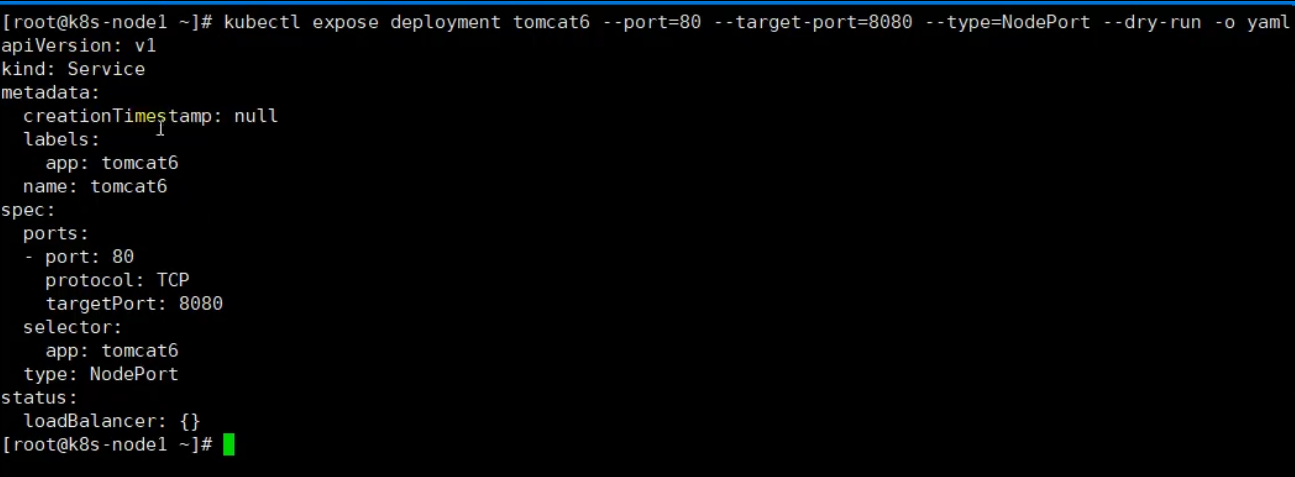
将暴露service的文件和创建pod的文件合并:
-- 部署
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: tomcat6
name: tomcat6
spec:
replicas: 3
selector:
matchLabels:
app: tomcat6
spec:
containers:
- image: tomcat:9.0.53-jre8
name: tomcat
--- yaml中文件分隔符,先部署,然后暴露service
apiVersion: v1
kind: Service
metadata:
creationTimestamp: null
labels:
app: tomcat6
name: tomcat6
spec:
ports:
- port: 80
protocol: TCP
targetPort: 8080
selector:
app: tomcat6
type: NodePort使用一个yaml文件部署暴露:
cubelctl -apply -f tomcat-deploym ent.yaml
项目部署流程:
- 制作项目镜像(将项目制作为 Docker 镜像,要熟悉 Dockerfile 的编写)
- 控制器管理 Pod(编写 k8s 的 yaml 即可)
- 暴露应用
- 日志监控
1.4.3、应用部署
k8s应用部署流程
书写docker.file文件,将项目打包成镜像文件.
为每一个项目生成k8s描述文件
- 创建pod文件,也可以通过可视化页面做
- 暴露service文件
以上整个过程,可以通过Jenkins(流水线工具)工具串起来执行。
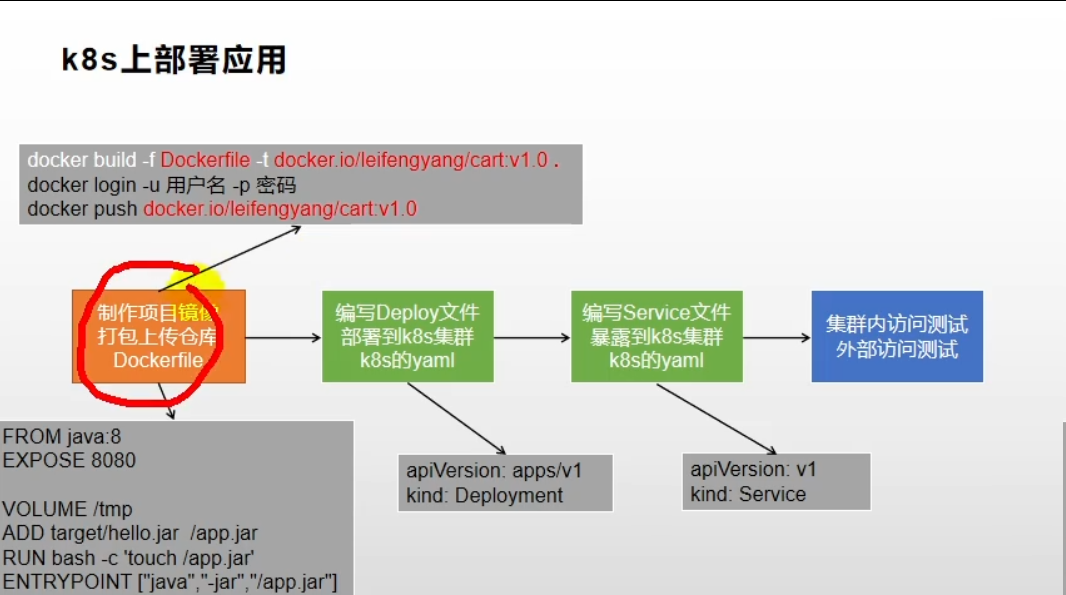
首先是将项目打包成docker镜像。
可以通过docker.file,docker会根据docker.file文件将项目打包成镜像。一般会为每一个微服务项目准备一个docker.file文件。
进入某一个docker容器:
docker exec -it 服务名字 /bin/bash //进入到根目录
kubectl exec -it <pod-name> -n <namespace> -- /bin/bash
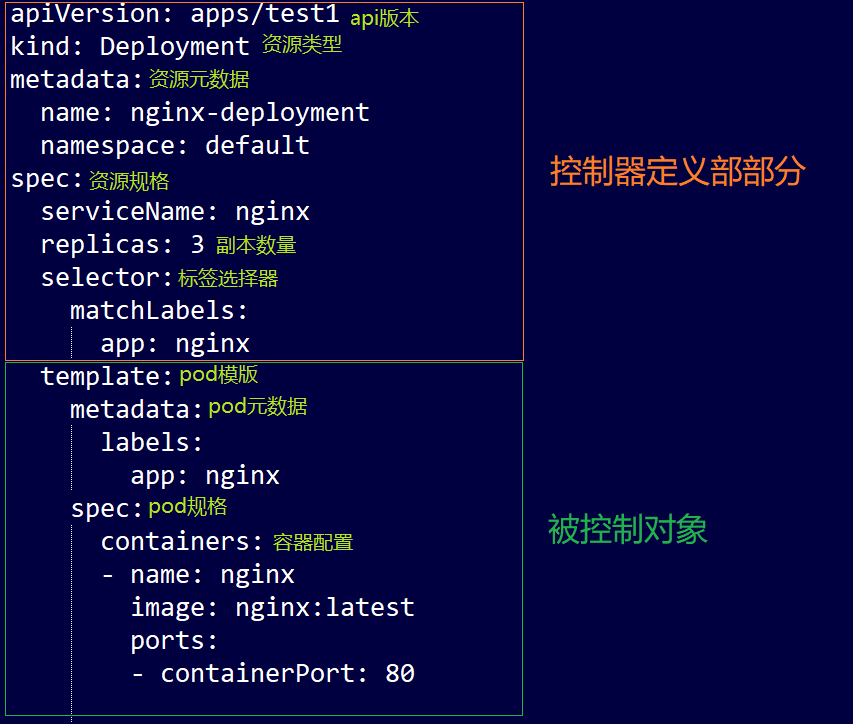
容器编排常用属性
- 每个yaml必须存在的属性
spec : [主要对象]
 yaml详解
yaml详解
apiVersion: v1 #指定api版本,此值必须在kubectl apiversion中
kind: Pod #指定创建资源的角色/类型
metadata: #资源的元数据/属性
name: web04-pod #资源的名字,在同一个namespace中必须唯一
labels: #设定资源的标签
k8s-app: apache
version: v1
kubernetes.io/cluster-service: "true"
annotations: #自定义注解列表
- name: String #自定义注解名字
spec: #specification of the resource content 指定该资源的内容
restartPolicy: Always #表明该容器一直运行,默认k8s的策略,在此容器退出后,会立即创建一个相同的容器
nodeSelector: #节点选择,先给主机打标签kubectl label nodes kube-node1 zone=node1
zone: node1
containers:
- name: web04-pod #容器的名字
image: web:apache #容器使用的镜像地址
imagePullPolicy: Never #三个选择Always、Never、IfNotPresent,每次启动时检查和更新(从registery)images的策略,
# Always,每次都检查
# Never,每次都不检查(不管本地是否有)
# IfNotPresent,如果本地有就不检查,如果没有就拉取
command: ['sh'] #启动容器的运行命令,将覆盖容器中的Entrypoint,对应Dockefile中的ENTRYPOINT
args: ["$(str)"] #启动容器的命令参数,对应Dockerfile中CMD参数
env: #指定容器中的环境变量
- name: str #变量的名字
value: "/etc/run.sh" #变量的值
resources: #资源管理
requests: #容器运行时,最低资源需求,也就是说最少需要多少资源容器才能正常运行
cpu: 0.1 #CPU资源(核数),两种方式,浮点数或者是整数+m,0.1=100m,最少值为0.001核(1m)
memory: 32Mi #内存使用量
limits: #资源限制最大范围
cpu: 0.5
memory: 64Mi
ports:
- containerPort: 80 #容器开发对外的端口
name: httpd #名称
protocol: TCP
livenessProbe: #pod内容器健康检查的设置
httpGet: #通过httpget检查健康,返回200-399之间,则认为容器正常
path: / #URI地址
port: 80
#host: 127.0.0.1 #主机地址
scheme: HTTP
initialDelaySeconds: 180 #表明第一次检测在容器启动后多长时间后开始
timeoutSeconds: 5 #检测的超时时间
periodSeconds: 15 #检查间隔时间
#也可以用这种方法
#exec: 执行命令的方法进行监测,如果其退出码不为0,则认为容器正常
# command:
# - cat
# - /tmp/health
#也可以用这种方法
#tcpSocket: //通过tcpSocket检查健康
# port: number
lifecycle: #生命周期管理
postStart: #容器运行之前运行的任务
exec:
command:
- 'sh'
- 'yum upgrade -y'
preStop:#容器关闭之前运行的任务
exec:
command: ['service httpd stop']
volumeMounts: #数据卷挂载
- name: volume #挂载设备的名字,与volumes[*].name 需要对应
mountPath: /data #挂载到容器的某个路径下
readOnly: True
volumes: #定义一组挂载设备
- name: volume #定义一个挂载设备的名字
#meptyDir: {}
hostPath:
path: /opt #挂载设备类型为hostPath,路径为宿主机下的/opt,这里设备类型支持很多种1.5、DEVOPS
项目开发需要考虑什么事情?
- Dev:怎么开发?
- Ops:怎么运维?
- 高并发:怎么承担高并发
- 高可用:怎么做到高可用
1.5.1、什么是devops?
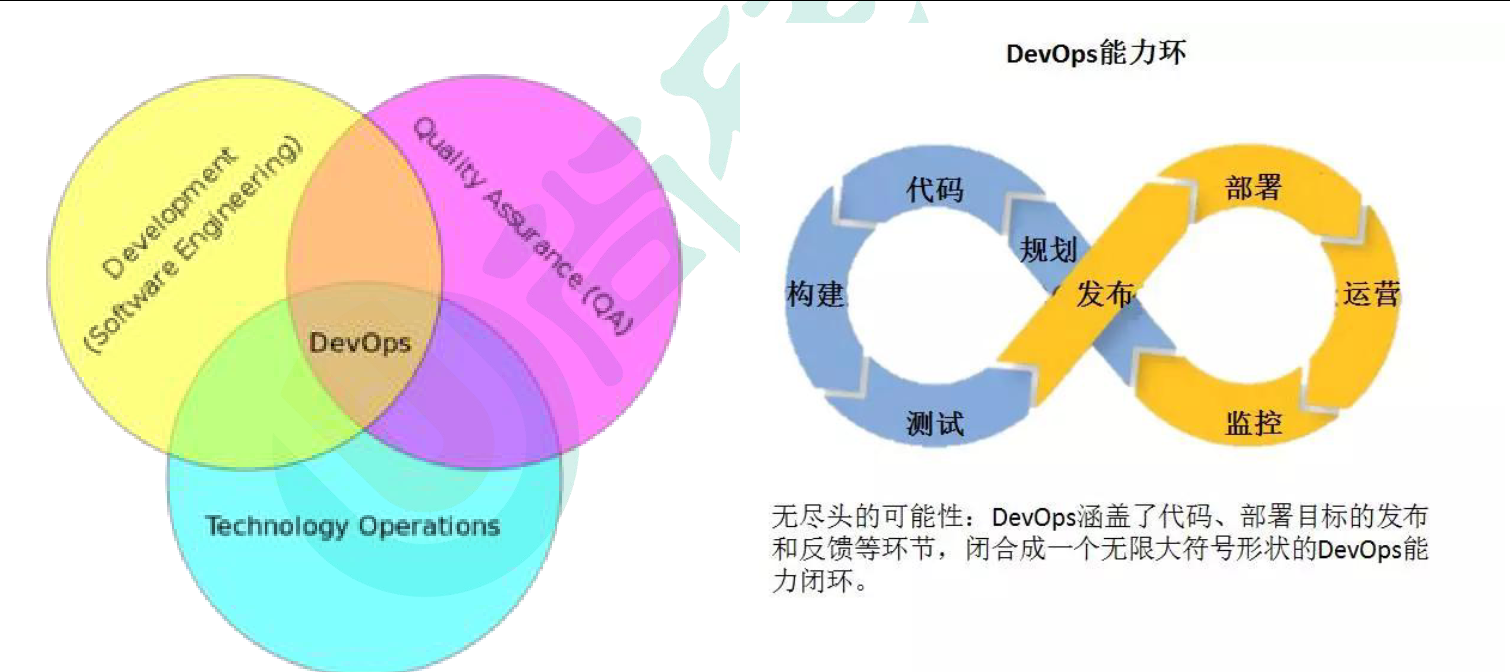
微服务,服务自治。
DevOps: Development 和 Operations 的组合
- DevOps 看作开发(软件工程)、技术运营和质量保障(QA)三者的交集。
- 突出重视软件开发人员和运维人员的沟通合作,通过自动化流程来使得软件构建、测试、发布更加快捷、频繁和可靠。
- DevOps 希望做到的是软件产品交付过程中IT 工具链的打通,使得各个团队减少时间损耗,更加高效地协同工作。专家们总结出了下面这个 DevOps 能力图,良好的闭环可以大大增加整体的产出。
1.5.2、什么是CI & CD
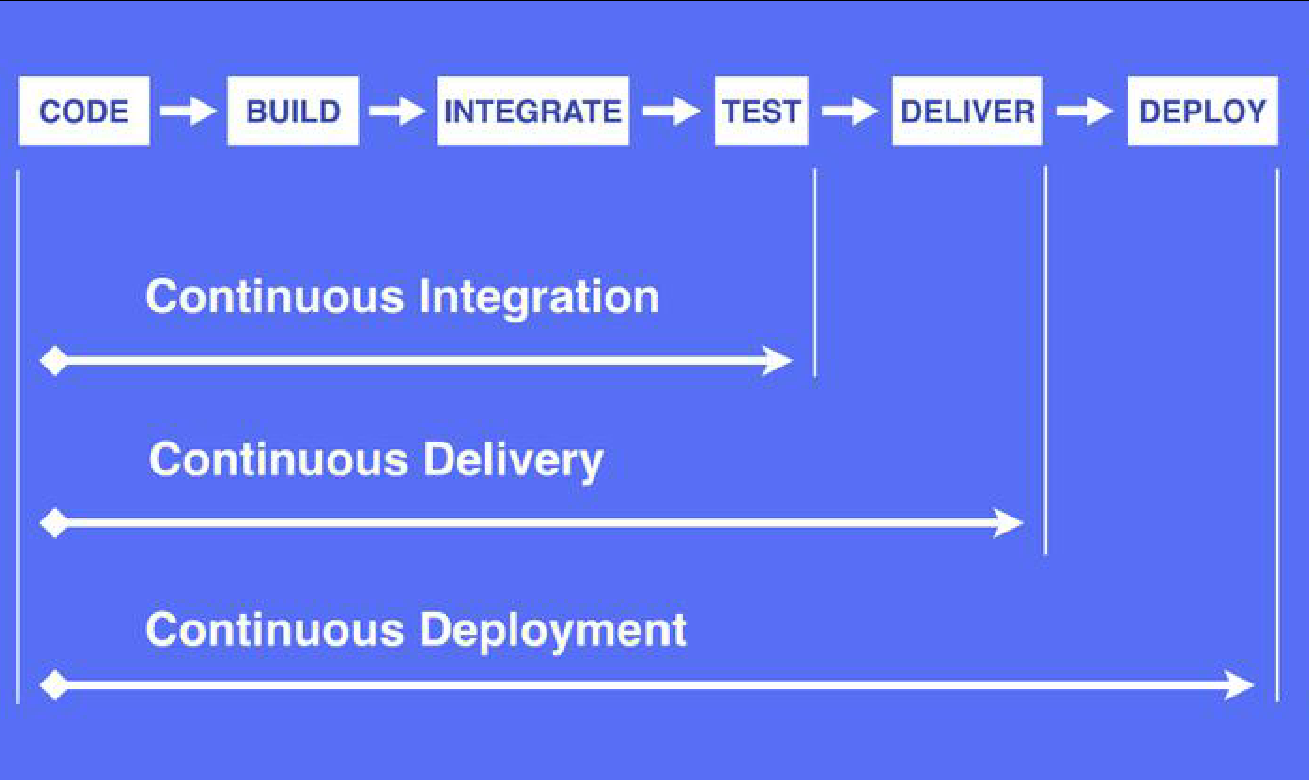
code:开发
build:打包
integrate:集成到总的项目
Test:测试
以上步骤是CI
持续集成(Continuous Integration)
齿距集成可以使用jenks工具。
持续集成是指软件个人研发的部分向软件整体部分交付,频繁进行集成以便更快地发现
其中的错误。“持续集成”源自于极限编程(XP),是 XP 最初的 12 种实践之一。
CI 需要具备这些:
- 全面的自动化测试。这是实践持续集成&持续部署的基础,同时,选择合适的自动化测试工具也极其重要;
- 灵活的基础设施。容器,虚拟机的存在让开发人员和 QA 人员不必再大费周折;
- 版本控制工具。如Git,CVS,SVN 等;
- 自动化的构建和软件发布流程的工具,如Jenkins,flow.ci;
- 反馈机制。如构建/测试的失败,可以快速地反馈到相关负责人,以尽快解决达到一个更稳定的版本。
持续交付(Continuous Delivery)
持续交付在持续集成的基础上,将集成后的代码部署到更贴近真实运行环境的「类生产环境」
(production-like environments)中。持续交付优先于整个产品生命周期的软件部署,建立在高水平自动化持续集成之上。
灰度发布。
持续交付和持续集成的优点非常相似:
- 快速发布。能够应对业务需求,并更快地实现软件价值。
- 编码->测试->上线->交付的频繁迭代周期缩短,同时获得迅速反馈;
- 高质量的软件发布标准。整个交付过程标准化、可重复、可靠,
- 整个交付过程进度可视化,方便团队人员了解项目成熟度;
- 更先进的团队协作方式。从需求分析、产品的用户体验到交互 设计、开发、测试、运维等角色密切协作,相比于传统的瀑布式软件团队,更少浪费。
持续部署(Continuous Deployment)
持续部署是指当交付的代码通过评审之后,自动部署到生产环境中。持续部署是持续交付的最高阶段。这意味着,所有通过了一系列的自动化测试的改动都将自动部署到生产环境。它也可以被称为“Continuous Release”。
“开发人员提交代码,持续集成服务器获取代码,执行单元测试,根据测试结果决定是否部署到预演环境,如果成功部署到预演环境,进行整体验收测试,如果测试通过,自动部署到产品环境,全程自动化高效运转。”
持续部署主要好处是,可以相对独立地部署新的功能,并能快速地收集真实用户的反馈。
下图是由 Jams Bowman 绘制的持续交付工具链图:
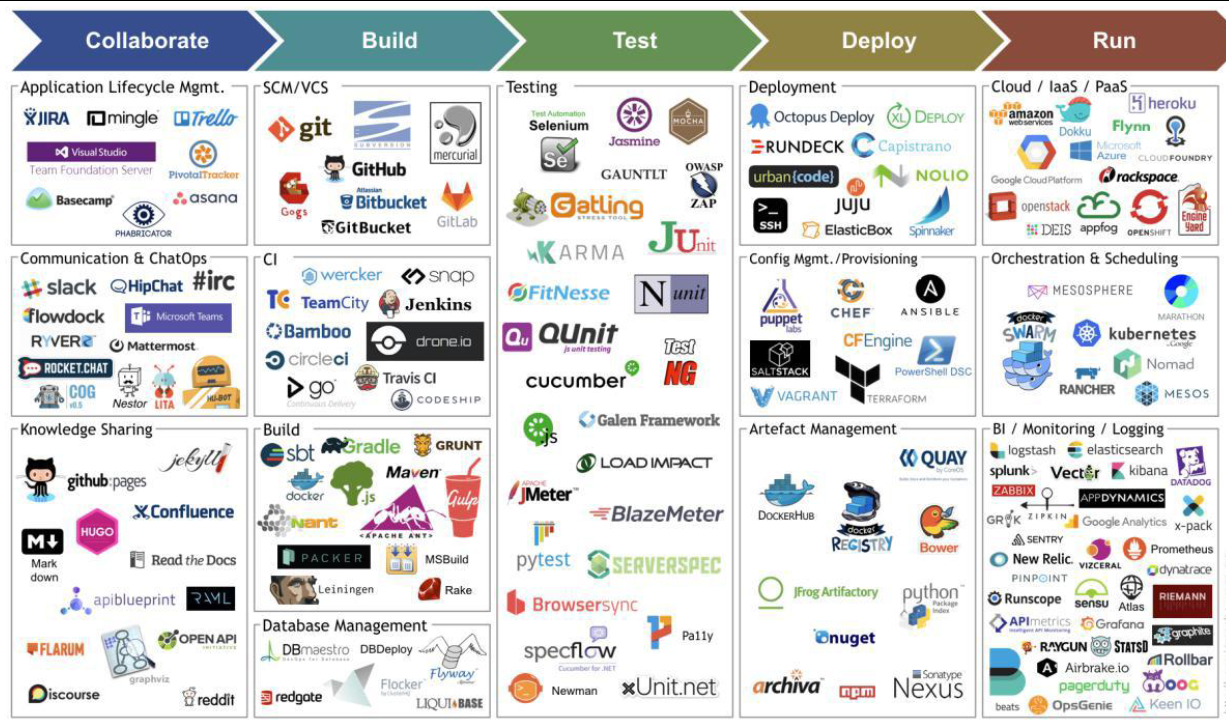
Collaborate:协作开发:项目生命周期管理
- jira
- 禅道
Build:
- scm:gitlab
- ci:jenkins
- build:maven
test:
- jmater:压力测试
deploy:
- ssh
- docker镜像
run:
- 云平台
- k8s
项目开发部署流程:
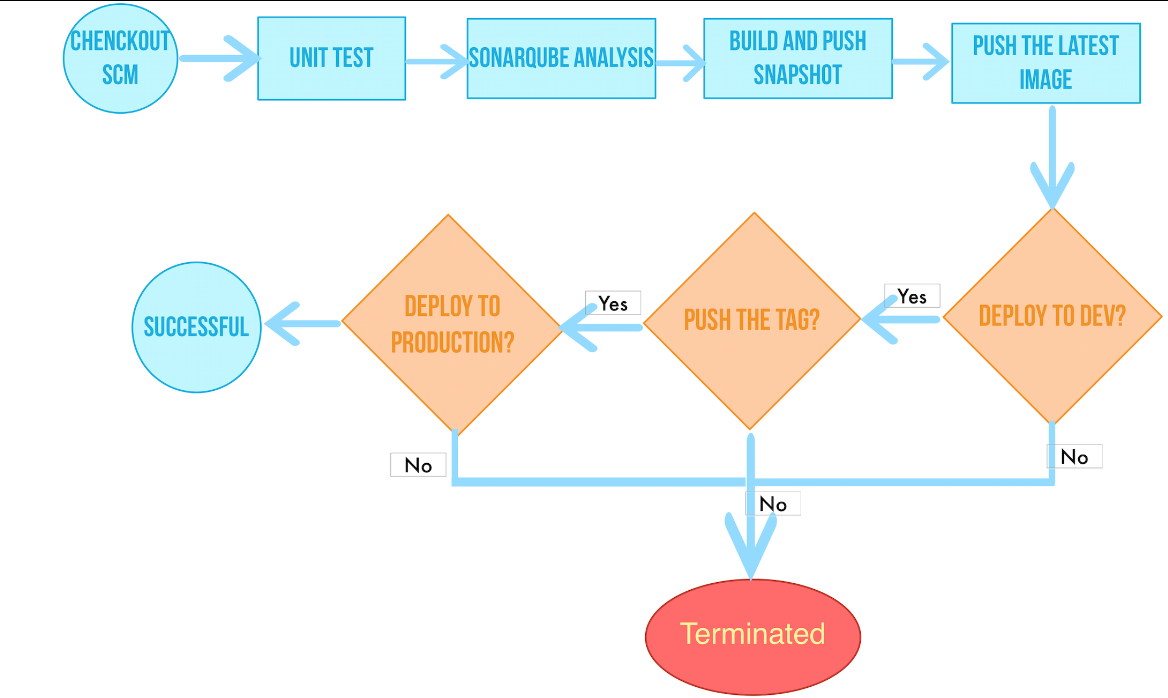
checkout scm:胆码仓库检出代码
unit:执行一些简单的测试或者代码扫描,比如奇安信
sonarqube analysis:代码分析
build push sanpshot:将代码打包成镜
push the latest image:推送镜像到远程仓库
1.6、k8s基础
1.6.1、简介
Kubernetes 简称 k8s。是用于自动部署,扩展和管理容器化应用程序的开源系统。
中文官网:https://kubernetes.io/zh/
中文社区:https://www.kubernetes.org.cn/
官方文档:https://kubernetes.io/zh/docs/home/
社区文档:http://docs.kubernetes.org.cn/
应用部署方式的进化:
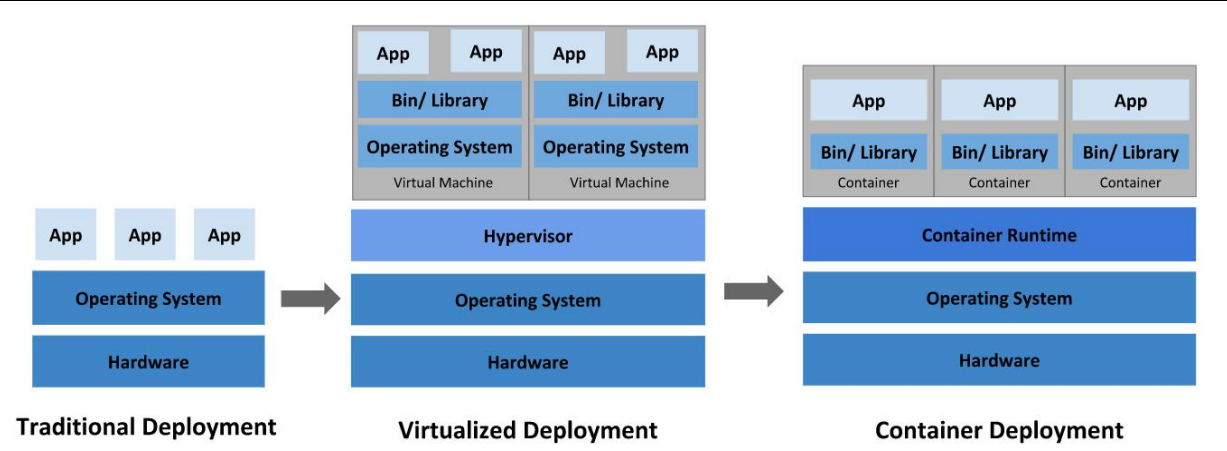
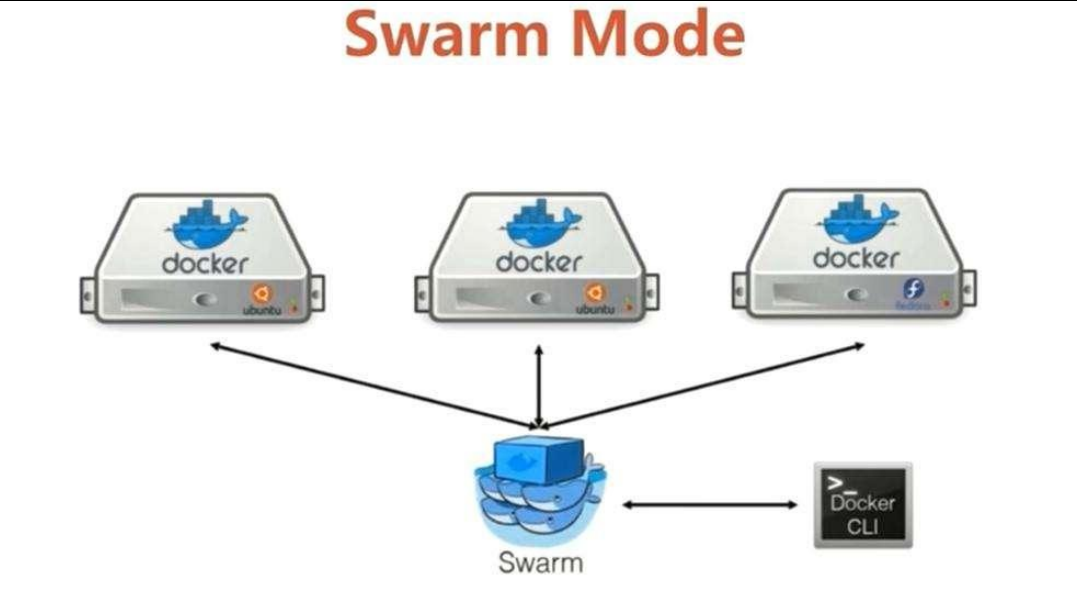
现在有三台服务器,每一台服务器上都安装了docker运行环境,每一个服务器上都运行了大量的容器,现在所有部署的docker容器如何编排,假设现在一号服务器上部署商品服务,根据流量的大小需要对商品服务进行扩容,流量大就扩充,流量小就缩小;当我们部署一个新的模块时候,需要找一个资源相对较多的服务器起一个容器,这个过程中对容器的整个编排工作很麻烦,要管理很多的服务器,并且还要管理服务器上的容器集群,docker官方有一个Swrm来管理部署docker集群,如果我们需要跑商品服务,并且部署三份,那么swarm会找三台服务器,启动三个容器跑商品服务,如果有一个服务宕机,那么swarm会感知宕机的服务,重新找一个服务器启动容器运行我们的服务,总汇保持有三台服务器同时运行我们的服务。swarm只能够用来管理docker容器集群。
但是现实开发中有很多种运行时容器环境,k8s就是用来管理不同运行时环境的工具。 k8s的角色类似于swarm,但是可以适用于不同的运行时容器环境。
k8s本质上是用来管理我们容器服务器集群的环境。
1.6.2、k8s可以做什么
1.6.3、k8s架构
整体架构
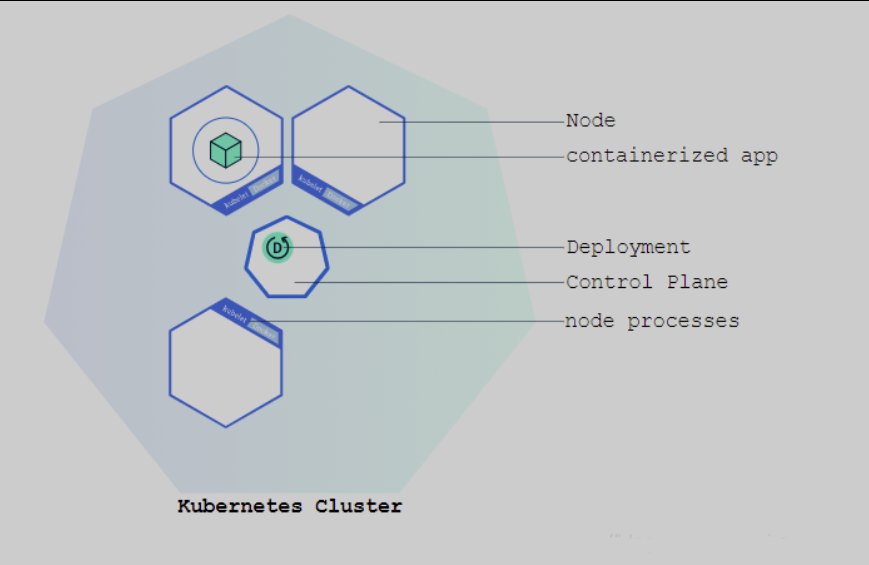
整体主从方式 :
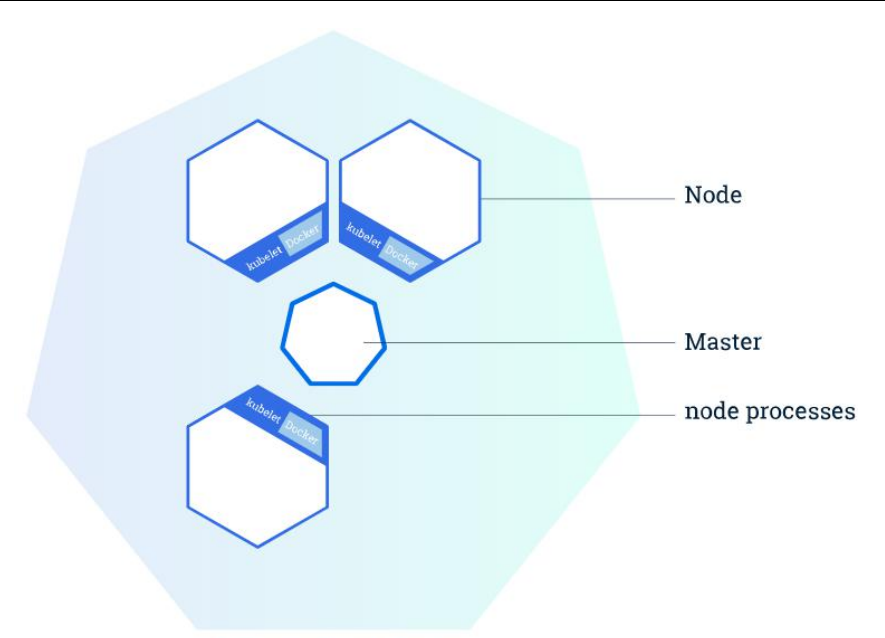
k8s整体上主从架构,一个master加点管理多个node工作节点,每一个node节点上面有docker运行时环境负责部署服务。
集群架构
集群组件:
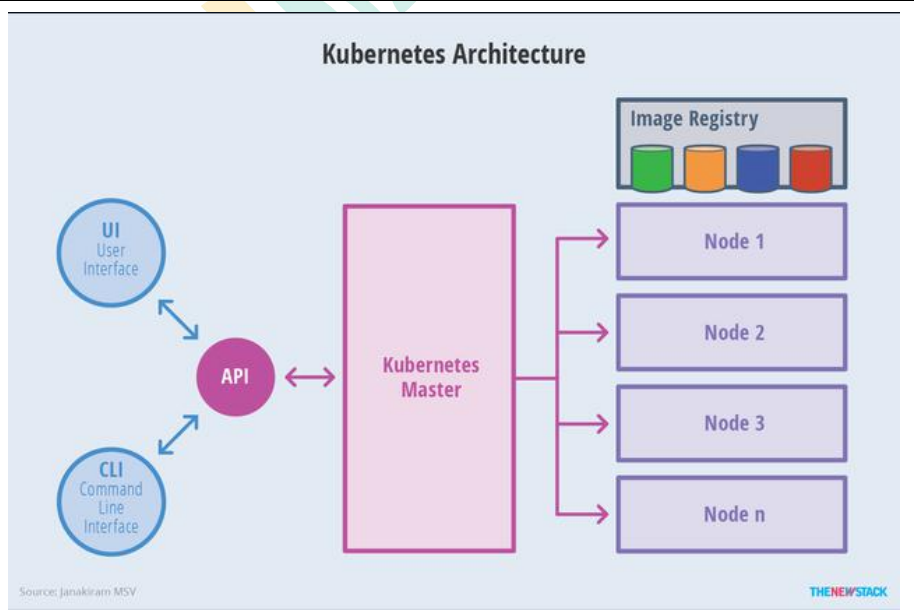
用户通过ui或者命令行方式发送命令到master节点,master负责将消息发送给node节点,node上运行了我们整个的服务集群,node上面有我们的docker容器,在启动集群的时候,容器需要一个外部的镜像仓库去拉取打包好的镜像启动。
Master节点架构
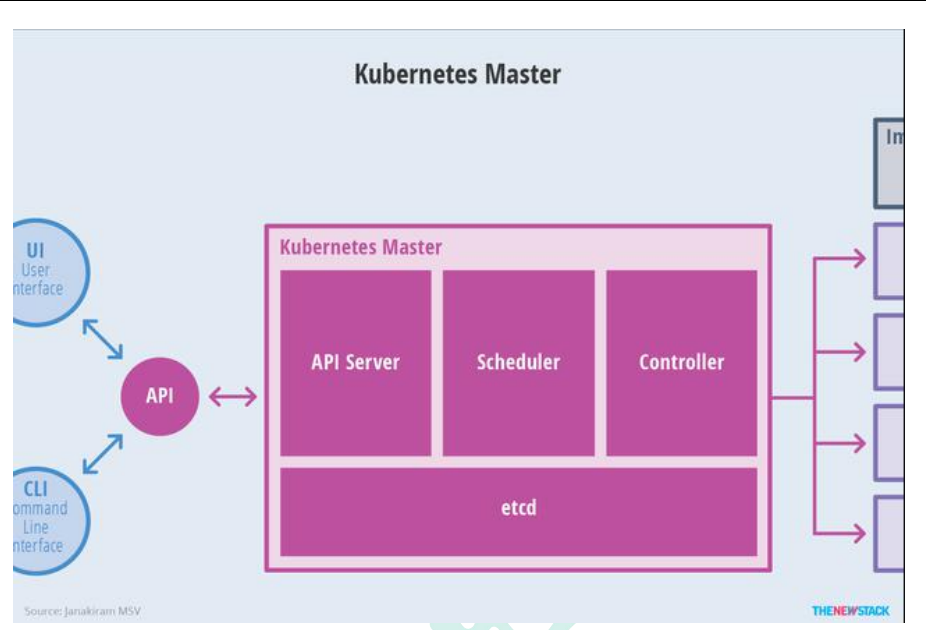
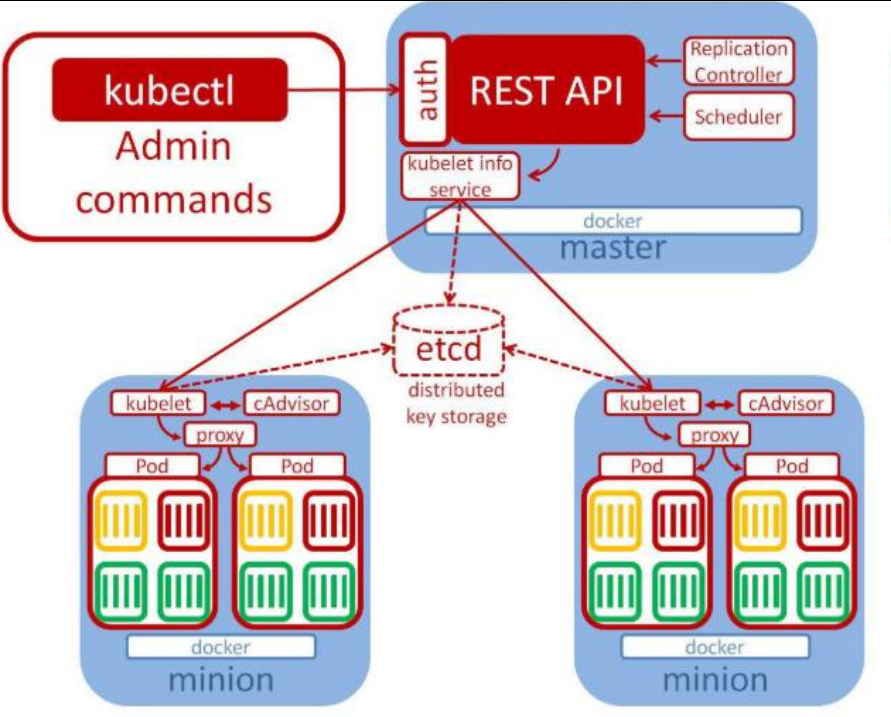
kube-apiserver
- 对外暴露 K8S 的 api 接口,是外界进行资源操作的唯一入口
- 提供认证、授权、访问控制、API 注册和发现等机制
etcd:存储元数据,可以理解为mysql数据库,kv数据库。也可以高可用部署。
- etcd 是兼具一致性和高可用性的键值数据库,可以作为保存 Kubernetes 所有集 群数据的后台数据库。
- Kubernetes 集群的 etcd 数据库通常需要有个备份计划
kube-scheduler
- 主节点上的组件,该组件监视那些新创建的未指定运行节点的 Pod,并选择节点 让 Pod 在上面运行。
- 所有对 k8s 的集群操作,都必须经过主节点进行调度
kube-controller-manager
在主节点上运行控制器的组件
这些控制器包括:
- 节点控制器(Node Controller): 负责在节点出现故障时进行通知和响应。
- 副本控制器(Replication Controller): 负责为系统中的每个副本控制器对象维护正确数量的 Pod。
- 端点控制器(Endpoints Controller): 填充端点(Endpoints)对象(即加入 Service 与 Pod)。
- 服务帐户和令牌控制器(Service Account & Token Controllers): 为新的命名 空间创建默认帐户和 API 访问令牌
apiserver接收到用户的部署请求之后,会将这些信息存储起来,然后scheduler会去etcd中查询用户提交的作业进行调度。真正负责部署执行的是controller控制器。
Node节点架构
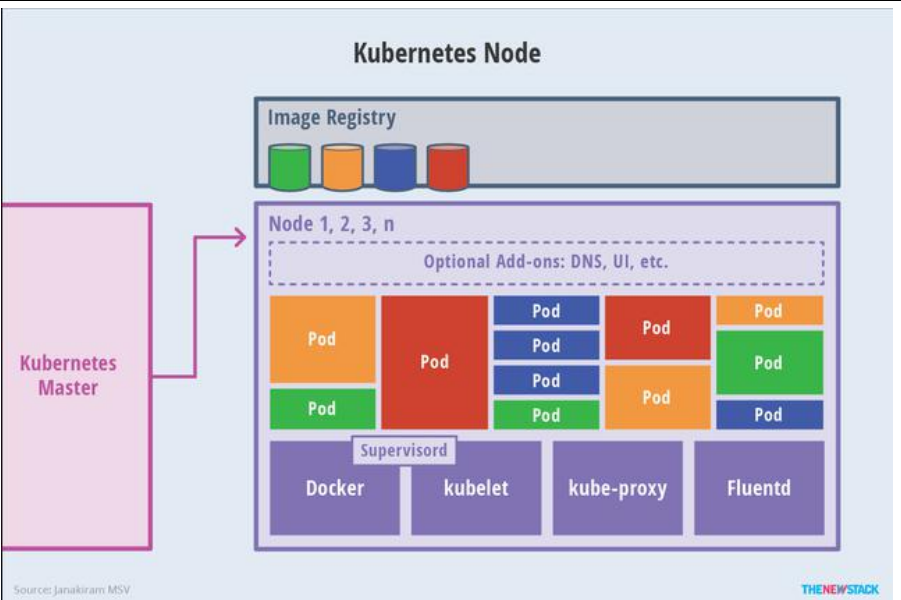
kubelet
- 一个在集群中每个节点上运行的代理。它保证容器都运行在 Pod 中。一个pod中可以包含多个容器同时完成一个服务。
- 负责维护容器的生命周期,同时也负责 Volume(CSI)和网络(CNI)的管理;
kube-proxy
- 负责为 Service 提供 cluster 内部的服务发现和负载均衡;
容器运行环境(Container Runtime)
- 容器运行环境是负责运行容器的软件。
- Kubernetes 支持多个容器运行环境: Docker、 containerd、cri-o、 rktlet 以及任 何实现 Kubernetes CRI (容器运行环境接口)。
fluentd
- 是一个守护进程,它有助于提供集群层面日志 集群层面的日志
整体运行架构
kubelet负责启动和部署应用,bube-proxy负责代理访问容器。
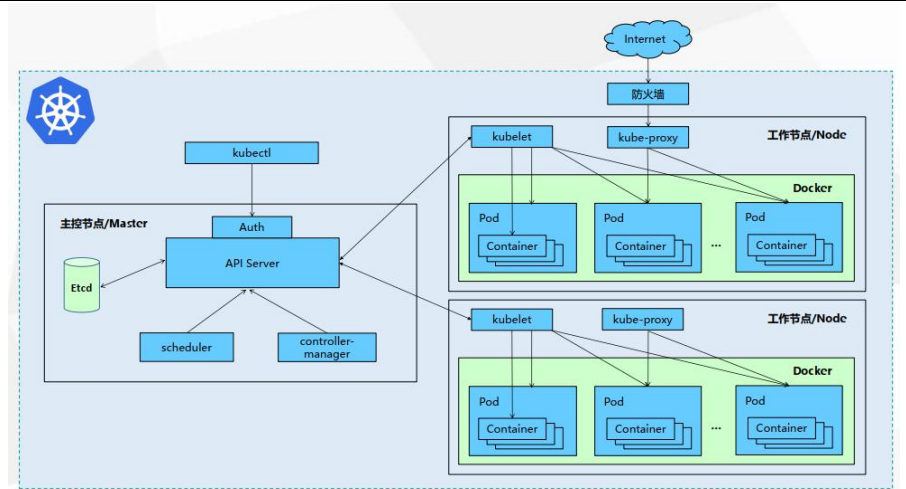
Container:容器,可以是 docker 启动的一个容器
Pod:一组容器的集合
- k8s 使用 Pod 来组织一组容器
- 一个 Pod 中的所有容器共享同一网络。
- Pod 是 k8s 中的最小部署单
Volume
- 声明在 Pod 容器中可访问的文件目录
- 可以被挂载在 Pod 中一个或多个容器指定路径下
- 支持多种后端存储抽象(本地存储,分布式存储,云存 储…)
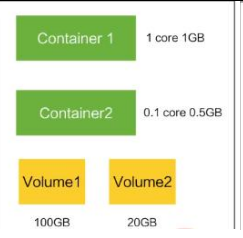
Controllers:更高层次对象,部署和管理 Pod; 部署一个应用,就是k8s执行一次controller。controller理解为一个容器。
- ReplicaSet:确保预期的 Pod 副本数量
- Deplotment:无状态应用部署 :开发的应用程序属于无状态应用,当即后立马启动一份就可以运行,mysql是有状态的,其存储的数据在磁盘上,如果这台服务器崩掉,在别的服务器重启mysql是没办法恢复另一台服务器上的数据的,数据丢失。
- StatefulSet:有状态应用部署
- DaemonSet:确保所有 Node 都运行一个指定 Pod
- Job:一次性任务
- Cronjob:定时任务
Deployment:
- 定义一组 Pod 的副本数目、版本等
- 通过控制器(Controller)维持 Pod 数目(自动回 复失败的 Pod)
- 通过控制器以指定的策略控制版本(滚动升级,回滚等)
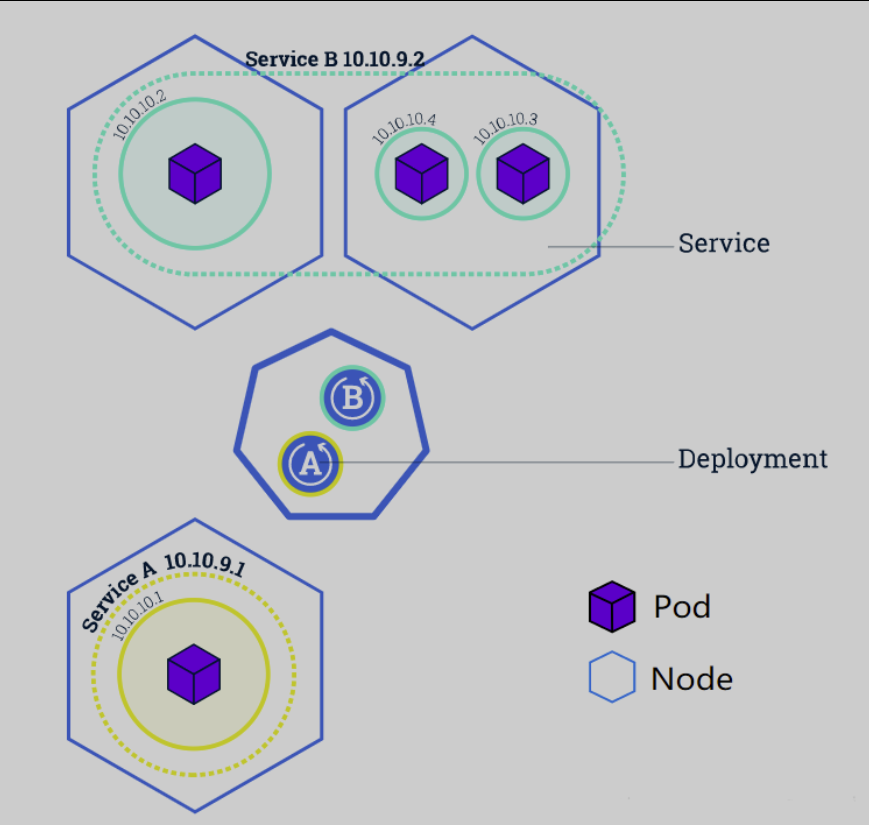
Service :一个service是一组pod, 可能是多个pod的组合,完成一个业务,业务即service.
- 定义一组 Pod 的访问策略
- Pod 的负载均衡,提供一个或者多个 Pod 的稳定 访问地址
- 支持多种方式(ClusterIP、NodePort、LoadBalance)
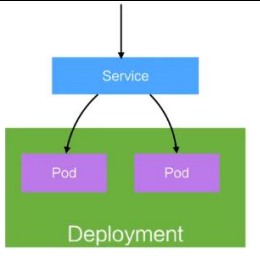
pod组合一些controller相当于集群部署,service组合一个pod相当于一个业务。一个service相当于一个业务,对外提供负载均衡能力。service知道自己的业务部署在哪些pod上。然后挑选一组负载最低的pod对外提供服务。一次deployment就是将各个pod部署到不同的节点里面。
Label:标签,用于对象资源的查询,筛选
Namespace:命名空间,逻辑隔离
- 一个集群内部的逻辑隔离机制(鉴权,资源)
- 每个资源都属于一个 namespace
- 同一个 namespace 所有资源名不能重复
- 不同 namespace 可以资源名重复
API: 我们通过 kubernetes 的 API 来操作整个集群。 可以通过 kubectl、ui、curl 最终发送 http+json/yaml 方式的请求给 API Server,然后控制 k8s 集群。k8s 里的所有的资源对象都可以采用 yaml 或 JSON 格式的文件定义或描述 :

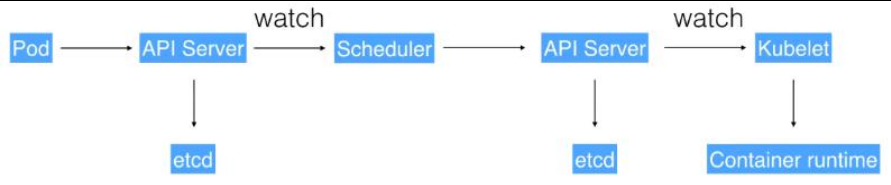
运行流程:
1、通过 Kubectl 提交一个创建 RC(Replication Controller)的请求,该请求通过 APIServer 被写入 etcd 中
2、此时 Controller Manager 通过 API Server 的监听资源变化的接口监听到此 RC 事件
3、分析之后,发现当前集群中还没有它所对应的 Pod 实例,
4、于是根据 RC 里的 Pod 模板定义生成一个 Pod 对象,通过 APIServer 写入 etcd
5、此事件被 Scheduler 发现,它立即执行一个复杂的调度流程,为这个新 Pod 选定一 个落户的 Node,然后通过 API Server 讲这一结果写入到 etcd 中,
6、目标 Node 上运行的 Kubelet 进程通过 APIServer 监测到这个“新生的”Pod,并按照它 的定义,启动该 Pod 并任劳任怨地负责它的下半生,直到 Pod 的生命结束。
7、随后,我们通过 Kubectl 提交一个新的映射到该 Pod 的 Service 的创建请求
8、ControllerManager 通过 Label 标签查询到关联的 Pod 实例,然后生成 Service 的 Endpoints 信息,并通过 APIServer 写入到 etcd 中, 9、接下来,所有 Node 上运行的 Proxy 进程通过 APIServer 查询并监听 Service 对象与 其对应的 Endpoints 信息,建立一个软件方式的负载均衡器来实现 Service 访问到后端 Pod 的流量转发功能。
注 k8s 里的所有的资源对象都可以采用 yaml 或 JSON 格式的文件定义或描
2、集群搭建
2.1、Flink集群搭建
1)flink下载
下载地址:https://flink.apache.org/downloads.html
wget https://dlcdn.apache.org/flink/flink-1.14.6/flink-1.14.6-bin-scala_2.12.tgz --no-check-certificate2)构建基础镜像
docker pull apache/flink:1.14.6-scala_2.12
docker tag apache/flink:1.14.6-scala_2.12 myharbor.com/bigdata/flink:1.14.6-scala_2.12
docker push myharbor.com/bigdata/flink:1.14.6-scala_2.123)session模式
Flink Session 集群作为长时间运行的 Kubernetes Deployment 执行。你可以在一个Session 集群上运行多个 Flink 作业。每个作业都需要在集群部署完成后提交到集群。
Kubernetes 中的Flink Session 集群部署至少包含三个组件:
- 运行JobManager的部署
- TaskManagers池的部署
- 暴露JobManager 的REST 和 UI 端口的服务
创建命名空间:
kubectl create ns flink-session
创建账户
kubectl create serviceaccount flink -n flink
获取所有的serviceaccount
kubectl get sa
给flink-session ns创建一个名字是flink-session-account的账户
kubectl create serviceaccount flink-session-account -n flink-session
给账号授权
kubectl create clusterrolebinding flink-role-bind --clusterrole=edit --serviceaccount=flink-session:flink-session-account
[root@centos2 bin]# kubectl create serviceaccount flink-session -n flink
Error from server (NotFound): namespaces "flink" not found
[root@centos2 bin]# kubectl create serviceaccount flink-session-account -n flink-session
serviceaccount/flink-session-account created
[root@centos2 bin]# kubectl create clusterrolebinding flink-role-bind --clusterrole=edit --serviceaccount=flink-session:flink-session-account
clusterrolebinding.rbac.authorization.k8s.io/flink-role-bind created
启动flink集群
bin/kubernetes-session.sh \
-Dkubernetes.namespace=flink-session \
-Dkubernetes.jobmanager.service-account=flink-session-account \
-Dkubernetes.rest-service.exposed.type=NodePort \
-Dkubernetes.cluster-id=flink-cluster \
-Dkubernetes.jobmanager.cpu=0.2 \
-Djobmanager.memory.process.size=1024m \
-Dresourcemanager.taskmanager-timeout=3600000 \
-Dkubernetes.taskmanager.cpu=0.2 \
-Dtaskmanager.memory.process.size=1024m \
-Dtaskmanager.numberOfTaskSlots=1
创建成功的flink集群
[root@centos2 flink-1.17.1]#
[root@centos2 flink-1.17.1]# bin/kubernetes-session.sh \
> -Dkubernetes.namespace=flink-session \
> -Dkubernetes.jobmanager.service-account=flink-session-account \
> -Dkubernetes.rest-service.exposed.type=NodePort \
> -Dkubernetes.cluster-id=flink-cluster \
> -Dkubernetes.jobmanager.cpu=0.2 \
> -Djobmanager.memory.process.size=1024m \
> -Dresourcemanager.taskmanager-timeout=3600000 \
> -Dkubernetes.taskmanager.cpu=0.2 \
> -Dtaskmanager.memory.process.size=1024m \
> -Dtaskmanager.numberOfTaskSlots=1
2023-11-26 14:35:44,429 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.memory.process.size, 1728m
2023-11-26 14:35:44,444 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.bind-host, localhost
2023-11-26 14:35:44,445 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.bind-host, localhost
2023-11-26 14:35:44,445 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.host, localhost
2023-11-26 14:35:44,446 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: parallelism.default, 1
2023-11-26 14:35:44,446 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.execution.failover-strategy, region
2023-11-26 14:35:44,446 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.rpc.address, localhost
2023-11-26 14:35:44,447 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.numberOfTaskSlots, 1
2023-11-26 14:35:44,447 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: rest.address, localhost
2023-11-26 14:35:44,447 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.memory.process.size, 1600m
2023-11-26 14:35:44,448 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.rpc.port, 6123
2023-11-26 14:35:44,448 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: rest.bind-address, localhost
2023-11-26 14:35:46,110 INFO org.apache.flink.client.deployment.DefaultClusterClientServiceLoader [] - Could not load factory due to missing dependencies.
2023-11-26 14:36:03,559 INFO org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils [] - The derived from fraction jvm overhead memory (102.400mb (107374184 bytes)) is less than its minvalue 192.000mb (201326592 bytes), min value will be used instead
2023-11-26 14:36:03,797 INFO org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils [] - The derived from fraction jvm overhead memory (102.400mb (107374184 bytes)) is less than its minvalue 192.000mb (201326592 bytes), min value will be used instead
2023-11-26 14:36:03,800 INFO org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils [] - The derived from fraction network memory (57.600mb (60397978 bytes)) is less than its min value 64.000mb (67108864 bytes), min value will be used instead
2023-11-26 14:36:05,050 INFO org.apache.flink.kubernetes.utils.KubernetesUtils [] - Kubernetes deployment requires a fixed port. Configuration blob.server.port will be set to 6124
2023-11-26 14:36:05,050 INFO org.apache.flink.kubernetes.utils.KubernetesUtils [] - Kubernetes deployment requires a fixed port. Configuration taskmanager.rpc.port will be set to 6122
2023-11-26 14:36:05,344 WARN org.apache.flink.configuration.Configuration [] - Config uses deprecated configuration key 'kubernetes.jobmanager.cpu' instead of proper key 'kubernetes.jobmanager.cpu.amount'
2023-11-26 14:36:21,361 INFO org.apache.flink.kubernetes.KubernetesClusterDescriptor [] - Create flink session cluster flink-cluster successfully, JobManager Web Interface: http://192.168.47.101:31733
提交任务执行:
./bin/flink run \
--target kubernetes-session \
-Dkubernetes.namespace=flink-session \
-Dkubernetes.cluster-id=flink-cluster \
./examples/streaming/WordCount.jar --output /opt查看flink集群信息:

查看集群描述信息
kubectl describe pod flink-cluster-5864d7b948-v5r6z -n flink-session
查看svc信息
kubectl get svc -n flink-session
查看flink-session命名空间
kubectl get pod -n flink-sessionhttps://blog.csdn.net/yy8623977/article/details/124989262
3、k8s问题排查
3.1、某一个pod长时间处于ContainerCreating状态
在K8s中,当一个pod的状态显示为“ContainerCreating”,意味着该pod已经被调度到一个节点上(已经决定了该pod应该运行在哪个节点上),并且该节点上的kubelet正在为该pod创建容器。
在这个阶段,会执行以下操作:
- 将所需的Docker镜像拉取到节点上(如果它们在本地尚不可用)。
- 从这些镜像创建容器。
- 启动容器。
如果一切顺利,一旦pod中的所有容器都启动并运行,pod的状态就会从“ContainerCreating”转变为“Running”。
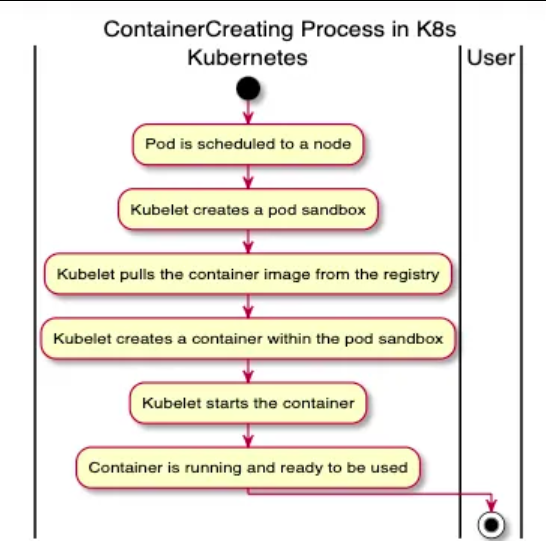
一个pod长时间处于ContainerCreating状态,可能存在一下原因:
- 镜像拉取问题:这是最常见的问题之一。可能是指定的镜像不存在,镜像名拼写错误,或者有网络问题导致镜像无法拉取。
- 资源不足:如果节点没有足够的CPU或内存资源来运行容器,那么pod就无法跨越“ContainerCreating”状态。
- 网络问题:如果有网络问题,比如CNI(容器网络接口)插件出现问题,可能会阻止容器的创建。
- 安全上下文问题:如果pod或容器的安全上下文没有正确配置(例如,pod试图以一个不存在的用户身份运行),它会阻止容器启动。
- Docker或运行时问题:如果有Docker守护进程或容器运行时的问题,可能会阻止容器的创建。
- 持久卷问题:如果pod依赖于一个持久卷声明(PVC),并且该PVC不可用或因为某些原因无法挂载,那么pod将保持在“ContainerCreating”状态。
3.1.1、镜像拉取问题
可以使用kubectl describe pod my-pod-name -n ns命令检查pod事件。
寻找“Failed to pull image”或“ImagePullBackOff”事件。这些会表明拉取Docker镜像有问题。
[root@centos2 opt]# kubectl describe pod flink-cluster-5864d7b948-v5r6z -n flink-session
Name: flink-cluster-5864d7b948-v5r6z
Namespace: flink-session
Priority: 0
Node: centos3/192.168.47.102
Start Time: Sun, 26 Nov 2023 15:37:16 +0800
Labels: app=flink-cluster
component=jobmanager
pod-template-hash=5864d7b948
type=flink-native-kubernetes
Annotations: <none>
Status: Pending
IP:
IPs: <none>
Controlled By: ReplicaSet/flink-cluster-5864d7b948
Containers:
flink-main-container:
Container ID:
Image: apache/flink:1.17.1-scala_2.12
Image ID:
Ports: 8081/TCP, 6123/TCP, 6124/TCP
Host Ports: 0/TCP, 0/TCP, 0/TCP
Command:
/docker-entrypoint.sh
Args:
bash
-c
kubernetes-jobmanager.sh kubernetes-session
State: Waiting
Reason: ContainerCreating
Ready: False
Restart Count: 0
Limits:
cpu: 200m
memory: 1Gi
Requests:
cpu: 200m
memory: 1Gi
Environment:
_POD_IP_ADDRESS: (v1:status.podIP)
Mounts:
/opt/flink/conf from flink-config-volume (rw)
/var/run/secrets/kubernetes.io/serviceaccount from flink-session-account-token-kfdg9 (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
flink-config-volume:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: flink-config-flink-cluster
Optional: false
flink-session-account-token-kfdg9:
Type: Secret (a volume populated by a Secret)
SecretName: flink-session-account-token-kfdg9
Optional: false
QoS Class: Guaranteed
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 10m default-scheduler Successfully assigned flink-session/flink-cluster-5864d7b948-v5r6z to centos3
Normal Pulling 10m kubelet, centos3 Pulling image "apache/flink:1.17.1-scala_2.12"3.1.2、资源不足
可以使用:kubectl describe node命令检查节点的资源情况。
[root@centos2 opt]# kubectl describe node centos3
Name: centos3
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=centos3
kubernetes.io/os=linux
Annotations: flannel.alpha.coreos.com/backend-data: {"VNI":1,"VtepMAC":"5e:07:31:6c:39:2e"}
flannel.alpha.coreos.com/backend-type: vxlan
flannel.alpha.coreos.com/kube-subnet-manager: true
flannel.alpha.coreos.com/public-ip: 192.168.47.102
kubeadm.alpha.kubernetes.io/cri-socket: /var/run/dockershim.sock
node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Sun, 26 Nov 2023 13:43:11 +0800
Taints: <none>
Unschedulable: false
Lease:
HolderIdentity: centos3
AcquireTime: <unset>
RenewTime: Sun, 26 Nov 2023 15:49:28 +0800
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
NetworkUnavailable False Sun, 26 Nov 2023 13:43:20 +0800 Sun, 26 Nov 2023 13:43:20 +0800 FlannelIsUp Flannel is running on this node
MemoryPressure False Sun, 26 Nov 2023 15:46:19 +0800 Sun, 26 Nov 2023 15:15:39 +0800 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Sun, 26 Nov 2023 15:46:19 +0800 Sun, 26 Nov 2023 15:15:39 +0800 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Sun, 26 Nov 2023 15:46:19 +0800 Sun, 26 Nov 2023 15:15:39 +0800 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Sun, 26 Nov 2023 15:46:19 +0800 Sun, 26 Nov 2023 15:15:39 +0800 KubeletReady kubelet is posting ready status
Addresses:
InternalIP: 192.168.47.102
Hostname: centos3
Capacity:
cpu: 2
ephemeral-storage: 28289540Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 1865308Ki
pods: 110
Allocatable:
cpu: 2
ephemeral-storage: 26071640021
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 1762908Ki
pods: 110
System Info:
Machine ID: 0c75e2df9b7341c6a6b9dc7958c842ae
System UUID: A5394D56-049A-E496-8E0F-E04B386B5074
Boot ID: d6c401c9-c8ae-4d3e-a8ea-1db53ce6fbab
Kernel Version: 3.10.0-862.el7.x86_64
OS Image: CentOS Linux 7 (Core)
Operating System: linux
Architecture: amd64
Container Runtime Version: docker://18.9.9
Kubelet Version: v1.17.3
Kube-Proxy Version: v1.17.3
PodCIDR: 10.244.1.0/24
PodCIDRs: 10.244.1.0/24
Non-terminated Pods: (5 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
flink-session flink-cluster-5864d7b948-v5r6z 200m (10%) 200m (10%) 1Gi (59%) 1Gi (59%) 12m
kube-flannel kube-flannel-ds-jsnms 100m (5%) 0 (0%) 50Mi (2%) 0 (0%) 126m
kube-system coredns-7f9c544f75-fcz6r 100m (5%) 0 (0%) 70Mi (4%) 170Mi (9%) 6m38s
kube-system coredns-7f9c544f75-kp442 100m (5%) 0 (0%) 70Mi (4%) 170Mi (9%) 6m36s
kube-system kube-proxy-557lx 0 (0%) 0 (0%) 0 (0%) 0 (0%) 126m
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 500m (25%) 200m (10%)
memory 1214Mi (70%) 1364Mi (79%)
ephemeral-storage 0 (0%) 0 (0%)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal NodeHasSufficientMemory 33m (x9 over 126m) kubelet, centos3 Node centos3 status is now: NodeHasSufficientMemory
Normal NodeHasNoDiskPressure 33m (x9 over 126m) kubelet, centos3 Node centos3 status is now: NodeHasNoDiskPressure
Normal NodeHasSufficientPID 33m (x9 over 126m) kubelet, centos3 Node centos3 status is now: NodeHasSufficientPID
Normal NodeReady 33m (x2 over 126m) kubelet, centos3 Node centos3 status is now: NodeReady打印详细的日志:
journalctl -u kubelet -f"cni0" already has an IP address different from 如何解决
背景
网络插件使用flannel的k8s集群,出错报错network: failed to delegate add: failed to set bridge addr: "cni0" already has an IP address different from...
Warning FailedCreatePodSandBox 114s kubelet, centos2 Failed to create pod sandbox: rpc error: code = Unknown desc = failed to set up sandbox container "a7b522daaf989f641599e446c797af26dc125ec99f10643fbb6819c5d5353a22" network for pod "flink-taskmanager-789c6bcb5c-75sgg": networkPlugin cni failed to set up pod "flink-taskmanager-789c6bcb5c-75sgg_default" network: failed to delegate add: failed to set bridge addr: "cni0" already has an IP address different from 10.244.1.1/24解决
删除网络设备
删除网络设备
ifconfig cni0 down
ifconfig flannel.1 down
ip link delete cni0
ip link delete flannel.1
重建此节点的flannel pod
kubectl delete pod -n kube-flannel kube-flannel-ds-g6p6x
kubectl delete pod -n kube-system ${podname}
先在每一个节点上山删除网络设备,然后在主节点上删除pod重建网络4、搭建私有docker仓库
在使用Docker拉取镜像时,Docker首先默认从Docker Hub官方下载镜像,很多时候我们的镜像都是使用Dockerfile自定义私有镜像,不对外公开,而且为了安全起见,docker可能在内网环境下运行,所以我们有必要搭建一套docker本地私有镜像仓库,以供整个内网集群环境使用。
搭建镜像仓库主流的有两种方法,一种是使用docker官方提供的registry镜像搭建仓库,简单快捷,但是功能有限;另一种是使用harbor搭建本地镜像仓库,harbor功能更强,使用范围更广,这里介绍使用registry搭建本地镜像仓库。
环境说明
架构:centos1作为私有仓库,centos2作为docker客户端
| 服务器 | 操作系统版本 | 进程 | 功能 |
|---|---|---|---|
| centos1/192.168.47.100 | centos 7.3 | register | register镜像仓库 |
| centos2/192.168.47.101 | centos 7.3 | docker | docker客户端 |
k8smaster节点配置镜像仓库
拉取registry镜像
[root@centos1 dockerrepo]# docker pull hub.c.163.com/library/registry:latest
latest: Pulling from library/registry
25728a036091: Pull complete
0da5d1919042: Pull complete
e27a85fd6357: Pull complete
d9253dc430fe: Pull complete
916886b856db: Pull complete
Digest: sha256:fce8e7e1569d2f9193f75e9b42efb07a7557fc1e9d2c7154b23da591e324f3d1
Status: Downloaded newer image for hub.c.163.com/library/registry:latest
查看拉去的镜像
[root@centos1 dockerrepo]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
flannel/flannel v0.22.3 e23f7ca36333 2 months ago 70.2MB
flannel/flannel-cni-plugin v1.2.0 a55d1bad692b 4 months ago 8.04MB
k8s.gcr.io/kube-proxy v1.17.3 ae853e93800d 3 years ago 116MB
registry.aliyuncs.com/google_containers/kube-proxy v1.17.3 ae853e93800d 3 years ago 116MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy v1.17.3 ae853e93800d 3 years ago 116MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver v1.17.3 90d27391b780 3 years ago 171MB
k8s.gcr.io/kube-apiserver v1.17.3 90d27391b780 3 years ago 171MB
registry.aliyuncs.com/google_containers/kube-apiserver v1.17.3 90d27391b780 3 years ago 171MB
registry.aliyuncs.com/google_containers/kube-controller-manager v1.17.3 b0f1517c1f4b 3 years ago 161MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager v1.17.3 b0f1517c1f4b 3 years ago 161MB
k8s.gcr.io/kube-controller-manager v1.17.3 b0f1517c1f4b 3 years ago 161MB
k8s.gcr.io/kube-scheduler v1.17.3 d109c0821a2b 3 years ago 94.4MB
registry.aliyuncs.com/google_containers/kube-scheduler v1.17.3 d109c0821a2b 3 years ago 94.4MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler v1.17.3 d109c0821a2b 3 years ago 94.4MB
k8s.gcr.io/coredns 1.6.5 70f311871ae1 4 years ago 41.6MB
registry.aliyuncs.com/google_containers/coredns 1.6.5 70f311871ae1 4 years ago 41.6MB
registry.cn-hangzhou.aliyuncs.com/google_containers/coredns 1.6.5 70f311871ae1 4 years ago 41.6MB
registry.aliyuncs.com/google_containers/etcd 3.4.3-0 303ce5db0e90 4 years ago 288MB
registry.cn-hangzhou.aliyuncs.com/google_containers/etcd 3.4.3-0 303ce5db0e90 4 years ago 288MB
k8s.gcr.io/pause 3.1 da86e6ba6ca1 5 years ago 742kB
registry.aliyuncs.com/google_containers/pause 3.1 da86e6ba6ca1 5 years ago 742kB
registry.cn-hangzhou.aliyuncs.com/google_containers/pause 3.1 da86e6ba6ca1 5 years ago 742kB
hub.c.163.com/library/registry latest 751f286bc25e 6 years ago 33.2MB查看registry镜像的端口:EXPOSE 5000/tcp 数据卷:VOLUME [/var/lib/registry]
[root@centos1 dockerrepo]# docker history hub.c.163.com/library/registry:latest
IMAGE CREATED CREATED BY SIZE COMMENT
751f286bc25e 6 years ago /bin/sh -c #(nop) CMD ["/etc/docker/registr… 0B
<missing> 6 years ago /bin/sh -c #(nop) ENTRYPOINT ["/entrypoint.… 0B
<missing> 6 years ago /bin/sh -c #(nop) COPY file:7b57f7ab1a8cf85c… 155B
<missing> 6 years ago /bin/sh -c #(nop) EXPOSE 5000/tcp 0B
<missing> 6 years ago /bin/sh -c #(nop) VOLUME [/var/lib/registry] 0B
<missing> 6 years ago /bin/sh -c #(nop) COPY file:6c4758d509045dc4… 295B
<missing> 6 years ago /bin/sh -c #(nop) COPY file:b99d4fe47ad1addf… 22.8MB
<missing> 6 years ago /bin/sh -c set -ex && apk add --no-cache… 5.61MB
<missing> 6 years ago /bin/sh -c #(nop) CMD ["/bin/sh"] 0B
<missing> 6 years ago /bin/sh -c #(nop) ADD file:89e72bfc19e81624b… 4.81MB创建registry容器,registry镜像生成容器作为私有仓库
-p 5000:5000做端口映射,物理机端口5000:容器端口5000
-v /docker/var/lib/registry:/var/lib/registry数据卷挂载,物理机目录/docker/var/lib/registry:容器目录/var/lib/registry
[root@centos1 dockerrepo]# docker run -dit --restart=always --name=docker-registry -p 5000:5000 -v /docker/var/lib/registry:/var/lib/registry hub.c.163.com/library/registry:latest
1b097a309fe0c2d6c08634749ec8cb6cbc2d149ab9cc68a9032e175b30e73536
查看docker镜像
[root@centos1 dockerrepo]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1b097a309fe0 hub.c.163.com/library/registry:latest "/entrypoint.sh /etc…" 36 seconds ago Up 35 seconds 0.0.0.0:5000->5000/tcp docker-registry此时镜像仓库还没有下载任何文件:
[root@centos1 registry]# pwd
/docker/var/lib/registry
[root@centos1 registry]# ll
总用量 0
[root@centos1 registry]#centos2节点配置从私有仓库上传和拉取镜像
上传镜像到私有仓库
现在在centos2配置docker客户端
查看现有的镜像,如果没有镜像,直接docker pull即可
[root@centos2 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
flannel/flannel v0.22.3 e23f7ca36333 2 months ago 70.2MB
flannel/flannel-cni-plugin v1.2.0 a55d1bad692b 4 months ago 8.04MB
tomcat latest fb5657adc892 23 months ago 680MB
apache/flink latest 319b46b3fabd 23 months ago 658MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy v1.17.3 ae853e93800d 3 years ago 116MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager v1.17.3 b0f1517c1f4b 3 years ago 161MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver v1.17.3 90d27391b780 3 years ago 171MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler v1.17.3 d109c0821a2b 3 years ago 94.4MB
registry.cn-hangzhou.aliyuncs.com/google_containers/coredns 1.6.5 70f311871ae1 4 years ago 41.6MB
registry.cn-hangzhou.aliyuncs.com/google_containers/etcd 3.4.3-0 303ce5db0e90 4 years ago 288MB
registry.cn-hangzhou.aliyuncs.com/google_containers/pause 3.1 da86e6ba6ca1 5 years ago 742kBdocker tag对镜像进行重命名,命名格式为:私有仓库ip:端口/分类/镜像:镜像版本
可以对本地的镜像进行重命名,然后推送到本地仓库中。
docker tag hub.c.163.com/library/wordpress 192.168.110.137:5000/boke/wordpress:latest
docker tag hub.c.163.com/library/tomcat 192.168.110.137:5000/web/tomcat:v1
docker tag hub.c.163.com/library/mysql 192.168.110.137:5000/db/mysql:5.7
// 对tomcat镜像重新命名
docker tag tomcat 192.168.47.100:5000/web/tomcat:v1
查看命名后的镜像 现在是v1版本
[root@centos2 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
flannel/flannel v0.22.3 e23f7ca36333 2 months ago 70.2MB
flannel/flannel-cni-plugin v1.2.0 a55d1bad692b 4 months ago 8.04MB
192.168.47.100:5000/web/tomcat v1 fb5657adc892 23 months ago 680MB
tomcat latest fb5657adc892 23 months ago 680MB
apache/flink latest 319b46b3fabd 23 months ago 658MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy v1.17.3 ae853e93800d 3 years ago 116MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver v1.17.3 90d27391b780 3 years ago 171MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager v1.17.3 b0f1517c1f4b 3 years ago 161MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler v1.17.3 d109c0821a2b 3 years ago 94.4MB
registry.cn-hangzhou.aliyuncs.com/google_containers/coredns 1.6.5 70f311871ae1 4 years ago 41.6MB
registry.cn-hangzhou.aliyuncs.com/google_containers/etcd 3.4.3-0 303ce5db0e90 4 years ago 288MB
registry.cn-hangzhou.aliyuncs.com/google_containers/pause 3.1 da86e6ba6ca1 5 years ago 742kB把我们命名好的镜像推送到k8smatser的仓库里,但是报错了,报错客户端的连接为HTTPS,但是服务器端返回的是http
[root@centos2 ~]# docker push 192.168.47.100:5000/web/tomcat:v1
The push refers to repository [192.168.47.100:5000/web/tomcat]
Get https://192.168.47.100:5000/v2/: http: server gave HTTP response to HTTPS client解决方式有两种:第一种修改/usr/lib/systemd/system/docker.service文件
[root@centos2 ~]# systemctl status docker
● docker.service - Docker Application Container Engine
Loaded: loaded (/usr/lib/systemd/system/docker.service; enabled; vendor preset: disabled)
Active: active (running) since 六 2023-12-02 08:09:51 CST; 1h 12min ago
Docs: https://docs.docker.com
Main PID: 1230 (dockerd)
Tasks: 14
Memory: 759.5M
CGroup: /system.slice/docker.service
└─1230 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
12月 02 08:11:13 centos2 dockerd[1230]: time="2023-12-02T08:11:13.435889366+08:00" level=error msg="error unmounting /var/lib/docker/overlay2/a80d6cf9bad90cdd69b29daa14c7c9a3950b868b683c3eb36fbdd312f091f16f/merged: invalid...ge-driver=overlay2
12月 02 08:18:26 centos2 dockerd[1230]: time="2023-12-02T08:18:26.270636811+08:00" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
12月 02 08:43:17 centos2 dockerd[1230]: time="2023-12-02T08:43:17.424764801+08:00" level=info msg="Layer sha256:f7d012098143356ae4e18546a5707a86551a00476c370f35b5618717c152ae68 cleaned up"
12月 02 08:43:17 centos2 dockerd[1230]: time="2023-12-02T08:43:17.425166572+08:00" level=info msg="Layer sha256:b8ceef7b845f917d9f666c1814c2b64f3080880dfcca0d34cf54f921dafe4886 cleaned up"
12月 02 08:43:17 centos2 dockerd[1230]: time="2023-12-02T08:43:17.425182810+08:00" level=info msg="Layer sha256:b00285bb8c4bf3dfa5fc89e038662e2741abbc8c71ccefa70b6eb7c6e01cb7dc cleaned up"
12月 02 08:43:17 centos2 dockerd[1230]: time="2023-12-02T08:43:17.425193579+08:00" level=info msg="Layer sha256:0856724680c3d80d54963db8fb92379629450ac3a5d3793c18f16b731df16883 cleaned up"
12月 02 08:43:17 centos2 dockerd[1230]: time="2023-12-02T08:43:17.425204100+08:00" level=info msg="Layer sha256:b8a36d10656ac19ddb96ef3107f76820663717708fc37ce929925c36d1b1d157 cleaned up"
12月 02 08:43:17 centos2 dockerd[1230]: time="2023-12-02T08:43:17.425256230+08:00" level=info msg="Attempting next endpoint for pull after error: failed to register layer: error creating overlay mount to /var/lib/docker/ov...file or directory"
12月 02 09:11:30 centos2 dockerd[1230]: time="2023-12-02T09:11:30.598232413+08:00" level=warning msg="failed to retrieve runc version: unknown output format: runc version 1.1.10\ncommit: v1.1.10-0-g18a0cb0\nspec: 1.0.2-dev...bseccomp: 2.3.1\n"
12月 02 09:21:18 centos2 dockerd[1230]: time="2023-12-02T09:21:18.351471785+08:00" level=info msg="Attempting next endpoint for push after error: Get https://192.168.47.100:5000/v2/: http: server gave HTTP response to HTTPS client"
Hint: Some lines were ellipsized, use -l to show in full.
#/usr/bin/dockerd有一个参数--insecure-registry用于指定不安全的仓库
[root@centos2 ~]# /usr/bin/dockerd --help | grep insecure
--insecure-registry list Enable insecure registry communication
[root@centos2 ~]# vim /usr/lib/systemd/system/docker.service
#修改内容如下:添加了私有仓库地址和端口 --insecure-registry 192.168.47.100:5000
[root@centos2 ~]# cat /usr/lib/systemd/system/docker.service | grep insecure-registry
ExecStart=/usr/bin/dockerd --insecure-registry 192.168.47.100:5000 -H fd:// --containerd=/run/containerd/containerd.sock
#重新加载配置文件并重启docker
[root@k8sworker1 ~]# systemctl daemon-reload ; systemctl restart docker
[root@k8sworker1 ~]# systemctl status docker
● docker.service - Docker Application Container Engine
Loaded: loaded (/usr/lib/systemd/system/docker.service; enabled; vendor preset: disabled)
Active: active (running) since 二 2022-01-04 17:57:26 CST; 14s ago
Docs: https://docs.docker.com
Main PID: 62817 (dockerd)
Memory: 49.0M
CGroup: /system.slice/docker.service
└─62817 /usr/bin/dockerd --insecure-registry 192.168.110.137:5000 -H fd:// --containerd=/run/containerd/containerd.sock
#此时,推送wordpress镜像到私有仓库成功
[root@k8sworker1 ~]# docker push 192.168.110.137:5000/boke/wordpress:latest
The push refers to repository [192.168.110.137:5000/boke/wordpress]
53e16fa1f104: Pushed
562dd11ed871: Pushed
......
ddd6dcab19ff: Pushed
2c40c66f7667: Pushed
latest: digest: sha256:ca4cf4692b7bebd81f229942c996b1c4e6907d6733e977e93d671a54b8053a22 size: 4078第二种方式是修改/etc/docker/daemon.json
文件内容:
[root@centos2 ~]# cat /etc/docker/daemon.json
{
"registry-mirrors": ["https://82m9ar63.mirror.aliyuncs.com"]
}
[root@centos2 ~]#
#新增"insecure-registries":["192.168.47.100:5000"]
[root@centos2 ~]# cat /etc/docker/daemon.json
{
"registry-mirrors": ["https://82m9ar63.mirror.aliyuncs.com"],
"insecure-registries":["192.168.47.100:5000"]
}
[root@centos2 ~]# systemctl restart docker
#推送tomcat镜像到私有仓库成功
[root@centos2 ~]# docker push 192.168.47.100:5000/web/tomcat:v1
The push refers to repository [192.168.47.100:5000/web/tomcat]
3e2ed6847c7a: Preparing
3e2ed6847c7a: Pushed
bd2befca2f7e: Pushed
59c516e5b6fa: Pushed
3bb5258f46d2: Pushed
832e177bb500: Pushed
f9e18e59a565: Pushed
26a504e63be4: Pushed
8bf42db0de72: Pushed
31892cc314cb: Pushed
11936051f93b: Pushed
v1: digest: sha256:e6d65986e3b0320bebd85733be1195179dbce481201a6b3c1ed27510cfa18351 size: 2422查看私有仓库里的镜像
[root@centos2 ~]# curl 192.168.47.100:5000/v2/_catalog
{"repositories":["web/tomcat"]}
现在查看centos1服务器上的仓库内容,可以看到tomcat已经被成功推到本地私有镜像仓库
[root@centos1 web]# pwd
/docker/var/lib/registry/docker/registry/v2/repositories/web
[root@centos1 web]# ll
总用量 0
drwxr-xr-x 5 root root 55 12月 2 09:29 tomcat查看某个镜像的版本
{"repositories":["web/tomcat"]}
[root@centos2 ~]# curl 192.168.47.100:5000/v2/web/tomcat/tags/list
{"name":"web/tomcat","tags":["v1"]}从私有仓库里拉取镜像
从私有仓库中拉去镜像:
[root@centos2 ~]# docker pull 192.168.47.100:5000/web/tomcat:v1
v1: Pulling from web/tomcat
Digest: sha256:e6d65986e3b0320bebd85733be1195179dbce481201a6b3c1ed27510cfa18351
Status: Image is up to date for 192.168.47.100:5000/web/tomcat:v1
注意,现在私有镜像仓库是在centos1节点上,ip是:192.168.47.100,如果想要其他节点从这个私有仓库拉去镜像,
那么每个节点都需要在以下文件中新增内容:然后重启docker服务
#新增"insecure-registries":["192.168.47.100:5000"]
[root@centos2 ~]# cat /etc/docker/daemon.json
{
"registry-mirrors": ["https://82m9ar63.mirror.aliyuncs.com"],
"insecure-registries":["192.168.47.100:5000"]
}
现在在centos1节点配置中新增内容,然后拉去镜像:
[root@centos1 web]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
flannel/flannel v0.22.3 e23f7ca36333 2 months ago 70.2MB
flannel/flannel-cni-plugin v1.2.0 a55d1bad692b 4 months ago 8.04MB
192.168.47.100:5000/web/tomcat v1 fb5657adc892 23 months ago 680MB从docker客户端上传镜像之后,仓库文件夹里已经存在镜像了
[root@centos1 web]# pwd
/docker/var/lib/registry/docker/registry/v2/repositories/web
[root@centos1 web]# ll
总用量 0
drwxr-xr-x 5 root root 55 12月 2 09:29 tomcat
[root@centos1 web]# cd tomcat/
[root@centos1 tomcat]# ll
总用量 0
drwxr-xr-x 3 root root 20 12月 2 09:28 _layers
drwxr-xr-x 4 root root 35 12月 2 09:29 _manifests
drwxr-xr-x 2 root root 6 12月 2 09:29 _uploads参考:https://www.cnblogs.com/renshengdezheli/p/16646969.html
Flink1.17.1镜像构建
参考:https://www.zhihu.com/question/573041172
Docker指令
dockerfile 指令详解
FROM
基础镜像,必须是可以下载下来的,定制的镜像都是基于 FROM 的镜像,这里的 centos就是定制需要的基础镜像。后续的操作都是基于centos镜像
MAINTAINER
指定镜像的作者信息
RUN
指定在当前镜像构建过程中要运行的命令
包含两种模式
1. Shell
RUN <command> (shell模式,这个是最常用的,需要记住)
RUN ls2. exec模式
RUN ["executable","param1","param2"]
RUN ["/bin/bash","-c","ls"]
等价于/bin/bash -c lsEXPOSE指令
仅仅只是声明端口
作用:
1、帮助镜像使用者理解这个镜像服务的守护端口,以方便配置[映射]
2、在运行时使用随机端口映射
时,也就是 docker run -p 时,会自动随机映射 EXPOSE 的端口
3、可以是一个或者多个端口,也可以指定多个EXPOSE
格式:EXPOSE <端口1> [<端口2>...]
CMD
类似于 RUN 指令,用于运行程序,但二者运行的时间点不同:
1、CMD 在docker run 时运行
2、RUN 是在 docker build构建镜像时运行的
作用:
为启动的容器指定默认要运行的程序,程序运行结束,容器也就结束。
CMD 指令指定的程序可被 docker run 命令行参数中指定要运行的程序所覆盖.
如:
CMD ["/usr/sbin/nginx","-g","daemon off;"]ENTERYPOINT
类似于 CMD 指令,但其不会被 docker run 的命令行参数指定的指令所覆盖,而且这些命令行参数会被当作参数送给 ENTRYPOINT 指令指定的程序。
但是, 如果运行 docker run 时使用了 --entrypoint 选项,将覆盖 entrypoint指令指定的程序
优点:在执行 docker run 的时候可以指定 ENTRYPOINT 运行所需的参数。
注意:如果 Dockerfile 中如果存在多个 ENTRYPOINT 指令,仅最后一个生效
#格式:
ENTERYPOINT [“executable”,“param1”,“param2”](exec模式)
ENTERYPOINT command (shell模式)
可以搭配 CMD 命令使用:一般是变参
才会使用 CMD ,这里的 CMD 等于是在给 ENTRYPOINT 传参COPY
COPY <src>..<dest>
COPY["<src>" "<dest>"]
复制指令,从上下文目录中复制文件或者目录到容器里指定路径
格式:
COPY [--chown=<user>:<group>] <源路径1>... <目标路径>
COPY [--chown=<user>:<group>] ["<源路径1>",... "<目标路径>"]
[--chown=<user>:<group>]:可选参数,用户改变复制到容器内文件的拥有者和属组。
<源路径>:源文件
或者源目录,这里可以是通配符
表达式
例如:
COPY hom* /mydir/
COPY hom?.txt /mydir/
<目标路径>:容器内的指定路径,该路径不用事先建好,路径不存在的话,会自动创建。ADD
ADD <src> <dest>
ADD ["<src>" "<dest>"]
ADD 指令和 COPY 的使用格式一致(同样需求下,官方推荐使用 COPY)。功能也类似,不同之处如下:
ADD 的优点:在执行 <源文件> 为 tar 压缩文件的话,压缩格式为 gzip
, bzip2 以及 xz 的情况下,会自动复制并解压到 <目标路径>。
ADD 的缺点:在不解压的前提下,无法复制 tar 压缩文件。会令镜像构建缓存失效,从而可能会令镜像构建变得比较缓慢。具体是否使用,可以根据是否需要自动解压来决定。
ADD vs COPY
ADD包含类似tar的解压功能
如果单纯复制文件,dockerfile推荐使用COPYVOLUME
定义匿名数据卷。在启动容器时忘记挂载数据卷,会自动挂载到匿名卷。
作用:
1、避免重要的数据,因容器重启而丢失,这是非常致命的。
2、避免容器不断变大。
格式:
VOLUME ["<路径1>", "<路径2>" ...]
VOLUME <路径>
在启动容器 docker run 的时候,我们可以通过 -v 参数修改挂载点WORKDIR
指定工作目录。用 WORKDIR 指定的工作目录,会在构建镜像的每一层中都存在。(WORKDIR 指定的工作目录,必须是提前创建好的)。
docker build 构建镜像过程中的,每一个 RUN 命令都是新建的一层。只有通过 WORKDIR 创建的目录才会一直存在。 格式: WORKDIR :工作目录
WORKDIR /usr/local/nginxARG
构建参数,与 ENV 作用一至。不过作用域不一样。ARG 设置的环境变量仅对 Dockerfile 内有效,也就是说只有 docker build 的过程中有效,构建好的镜像内不存在此环境变量
ENV
设置环境变量
ENV <key> <value>
ENV <key>=<value>...
NODE_VERSION =6.6.6在 Dockerfile 中,ARG 和 ENV 都可以用于定义变量,但它们在作用和使用方式上有一些区别
- 作用范围:
- ARG:构建参数,只在构建过程中有效。可以通过 --build-arg 选项向 Docker 引擎传递构建参数的值。
- ENV:环境变量,在容器运行时有效。可以在构建过程中设置默认值,并在容器运行时被使用。
- 可见性:
- ARG:构建参数在构建过程中可见,但在生成的镜像和容器中不可见。
- ENV:环境变量在构建过程中和容器运行时都可见。可以在构建过程中设置默认值,并在容器运行时被使用。
- 动态性:
- ARG:可以在构建过程中动态设置,例如通过命令行参数
- --build-arg 来指定参数值。
- ENV:在构建过程中设置的环境变量值
- 是静态的,不可更改。但在容器运行时,可以通过 -e 选项来覆盖环境变量的值。
- 用途:
- ARG:通常用于构建过程中的条件逻辑判断
- 、动态配置等操作。
- ENV:用于在容器运行时配置应用程序的行为、传递参数或者提供运行时所需的信息
如上面的dockerfile中,在docker build时可以指定--build-arg来修改dockerfile中的版本
ARG NGINX_VERSION=1.22.1
ENV NGINX_VERSION=$NGINX_VERSION构建镜像时替换
docker build --build-arg NGINX_VERSION="1.17.1" -t nginx:v1 .USER
用于指定执行后续命令的用户和用户组
,这边只是切换后续命令执行的用户(用户和用户组必须提前已经存在)。
格式:
USER <用户名>[:<用户组>]
USER daemon
USER nginx
USER user
USER uid
USER user:group
USER uid:gid
USER user:gid
USER uid:groupONBUILD
用于延迟构建命令的执行。简单的说,就是 Dockerfile 里用 ONBUILD 指定的命令,在本次构建镜像的过程中不会执行(假设镜像为 test-build)。当有新的 Dockerfile 使用了之前构建的镜像 FROM test-build ,这时执行新镜像的 Dockerfile 构建时候,会执行 test-build 的 Dockerfile 里的 ONBUILD 指定的命令。
格式:
ONBUILD <其它指令>
为镜像添加触发器当一个镜像被其他镜像作为基础镜像时需要写上OBNBUILD
会在构建时插入触发器指令
LABEL
指令用来给镜像添加一些元数据
(metadata),以键值对
的形式,语法格式如下:
LABEL …
比如我们可以添加镜像的作者:
LABEL org.opencontainers.image.authors="xianchao"HEALTHCHECK
用于指定某个程序或者指令来监控 docker 容器服务的运行状态
格式:
HEALTHCHECK [选项] CMD <命令>:设置检查容器健康状况的命令
HEALTHCHECK NONE:如果基础镜像有健康检查指令,使用这行可以屏蔽掉其健康检查指令
HEALTHCHECK [选项] CMD <命令> : 这边 CMD 后面跟随的命令使用,可以参考 CMD 的用法。Flink1.17.1 Dockerfile编写
https://www.cnblogs.com/chouc/p/17330527.html
这里直接通过docker拉取Flink 1.17.1版本的镜像:
# 拉去flink镜像
[root@centos2 ~]# docker pull flink:1.17.1
# 将镜像上传到本地私有仓库