Flink中JobGraph生成
Flink中JobGraph生成
由前文我们知道,StreamGraph 表示一个流任务的逻辑拓扑,可以用一个 DAG 来表示(代码实现上没有一个 DAG 结构),DAG 的顶点是 StreamNode,边是 StreamEdge,边包含了由哪个 StreamNode 依赖哪个 StreamNode。本文我们主要介绍一个 StreamGraph 是如何转换成一个 JobGraph。
一、JobGraph 概述
- JobGraph 将会在原来的基础上做相应的优化(主要是算子的 Chain 操作,Chain 在一起的算子将会在同一个 task 上运行,会极大减少 shuffle 的开销)
- JobGraph 用来由 JobClient 提交给 JobManager,是由顶点(JobVertex)、中间结果(IntermediateDataSet)和边(JobEdge)组成的 DAG 图
- JobGraph 定义作业级别的配置,而每个顶点和中间结果定义具体操作和中间数据的设置
为什么要有 StreamGraph 和 JobGraph 两层的 Graph,最主要的原因是为兼容 batch process,Streaming process 最初产生的是 StreamGraph,而 batch process 产生的则是 OptimizedPlan,但是它们最后都会转换为 JobGraph
1.1、JobVertex
JobVertex 相当于是 JobGraph 的顶点,跟 StreamNode 的区别是,它是 Operator Chain 之后的顶点,会包含多个 StreamNode。主要成员:
List<OperatorIDPair> operatorIDs:该 job 节点包含的所有 operator ids,以深度优先方式存储 idsArrayList<JobEdge> inputs:带输入数据的边列表ArrayList<IntermediateDataSet> results:job 节点计算出的中间结果
1.2、IntermediateDataSet
它是由一个 Operator(可能是 source,也可能是某个中间算子)产生的一个中间数据集。中间数据集可能会被其他 operators 读取,物化或丢弃。主要成员:
JobVertex producer:该中间结果的生产者List<JobEdge> consumers:该中间结果消费边,通过消费边指向消费的节点ResultPartitionType resultType:中间结果的分区类型- 流水线的(有界的或无界的):一旦产生数据就向下游发送,可能是逐个发送的,有界或无界的记录流。
- 阻塞:仅在生成完整结果时向下游发送数据。
1.3、JobEdge
它相当于是 JobGraph 中的边(连接通道),这个边连接的是一个 IntermediateDataSet 跟一个要消费的 JobVertex。主要成员:
- IntermediateDataSet sourc:边的源
- JobVertex target:边的目标
- DistributionPattern distributionPattern:决定了在上游节点(生产者)的子任务和下游节点(消费者)之间的连接模式
- ALL_TO_ALL:每个生产子任务都连接到消费任务的每个子任务
- POINTWISE:每个生产子任务都连接到使用任务的一个或多个子任务
二、JobGraph生成
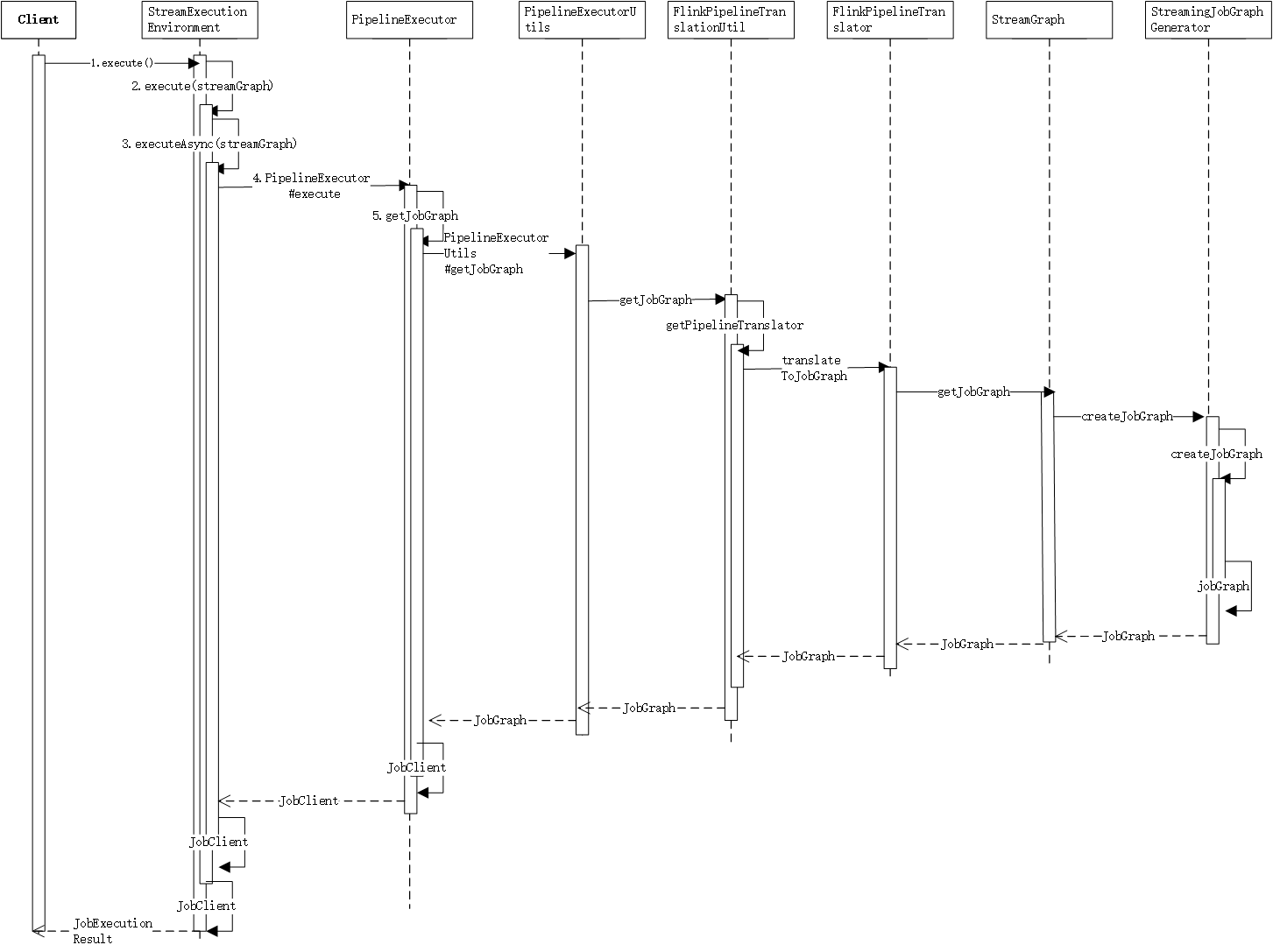
Flink客户端将用户写的代码先生成StreamGraph,就是我们常说的DAG图,这一层图是最接近用户程序本身,然后在execute()中将获取到的StreamGraph异步执行,这个过程中会调用getJobGraph()继续生成作业图,最终会将这个getJobGraph提交到集群中执行。
StreamGraph的生成在execute()方法中,然后会将StreamGraph图提交
public JobExecutionResult execute(String jobName) throws Exception {
final List<Transformation<?>> originalTransformations = new ArrayList<>(transformations);
//生成StreamGraph图
StreamGraph streamGraph = getStreamGraph();
if (jobName != null) {
streamGraph.setJobName(jobName);
}
try {
//在客户端提交StreamGraph,转换成JobGraph
return execute(streamGraph);
} catch (Throwable t) {
Optional<ClusterDatasetCorruptedException> clusterDatasetCorruptedException =
ExceptionUtils.findThrowable(t, ClusterDatasetCorruptedException.class);
if (!clusterDatasetCorruptedException.isPresent()) {
throw t;
}
// Retry without cache if it is caused by corrupted cluster dataset.
invalidateCacheTransformations(originalTransformations);
streamGraph = getStreamGraph(originalTransformations);
return execute(streamGraph);
}
}生成JobGraph的入口:
@Internal
public JobExecutionResult execute(StreamGraph streamGraph) throws Exception {
//将生成的streamGraph一步提交,会生成JobGraph
final JobClient jobClient = executeAsync(streamGraph);
try {
final JobExecutionResult jobExecutionResult;
if (configuration.getBoolean(DeploymentOptions.ATTACHED)) {
jobExecutionResult = jobClient.getJobExecutionResult().get();
} else {
jobExecutionResult = new DetachedJobExecutionResult(jobClient.getJobID());
}
jobListeners.forEach(
jobListener -> jobListener.onJobExecuted(jobExecutionResult, null));
return jobExecutionResult;
} catch (Throwable t) {
// get() on the JobExecutionResult Future will throw an ExecutionException. This
// behaviour was largely not there in Flink versions before the PipelineExecutor
// refactoring so we should strip that exception.
Throwable strippedException = ExceptionUtils.stripExecutionException(t);
jobListeners.forEach(
jobListener -> {
jobListener.onJobExecuted(null, strippedException);
});
ExceptionUtils.rethrowException(strippedException);
// never reached, only make javac happy
return null;
}
}executeAsync:
通过executorServiceLoader获取executorFactory,它是PipelineExecutorFactory类型的,主要为streamGraph的执行提供executor,它的实现类主要有以下几种:
//生成JobGraph
public JobClient executeAsync(StreamGraph streamGraph) throws Exception {
checkNotNull(streamGraph, "StreamGraph cannot be null.");
//工厂模式:根据配置信息创建PipelineExecutorFactory
final PipelineExecutor executor = getPipelineExecutor();
CompletableFuture<JobClient> jobClientFuture =
//执行器里面的执行逻辑
executor.execute(streamGraph, configuration, userClassloader);
try {
JobClient jobClient = jobClientFuture.get();
jobListeners.forEach(jobListener -> jobListener.onJobSubmitted(jobClient, null));
collectIterators.forEach(iterator -> iterator.setJobClient(jobClient));
collectIterators.clear();
return jobClient;
} catch (ExecutionException executionException) {
final Throwable strippedException =
ExceptionUtils.stripExecutionException(executionException);
jobListeners.forEach(
jobListener -> jobListener.onJobSubmitted(null, strippedException));
throw new FlinkException(
String.format("Failed to execute job '%s'.", streamGraph.getJobName()),
strippedException);
}
}PipelineExecutorServiceLoader的实现有三种:
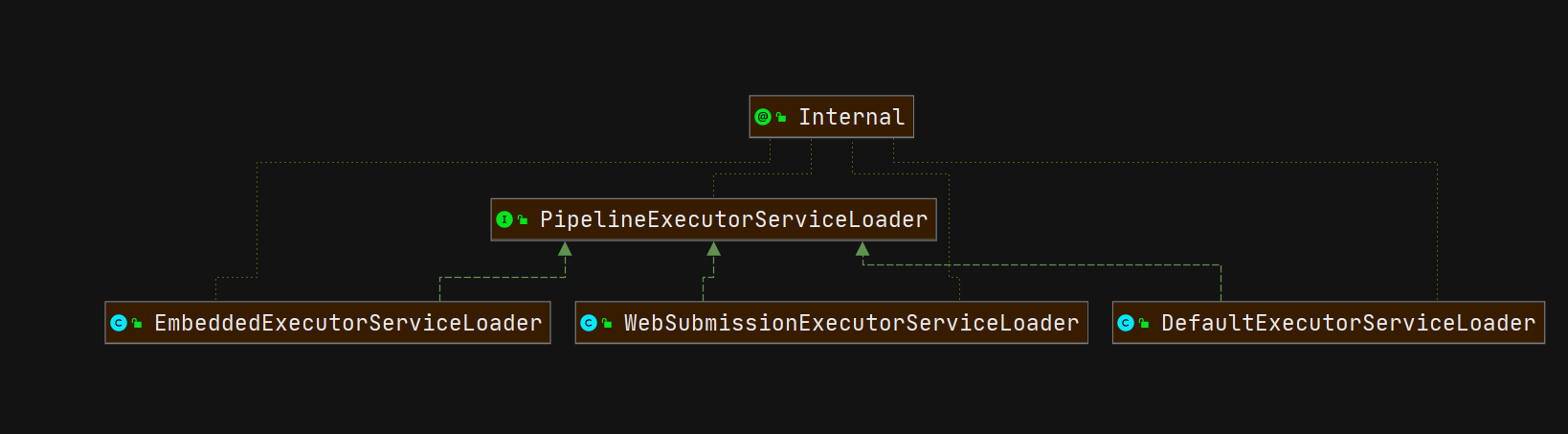
PipelineExecutor实现类
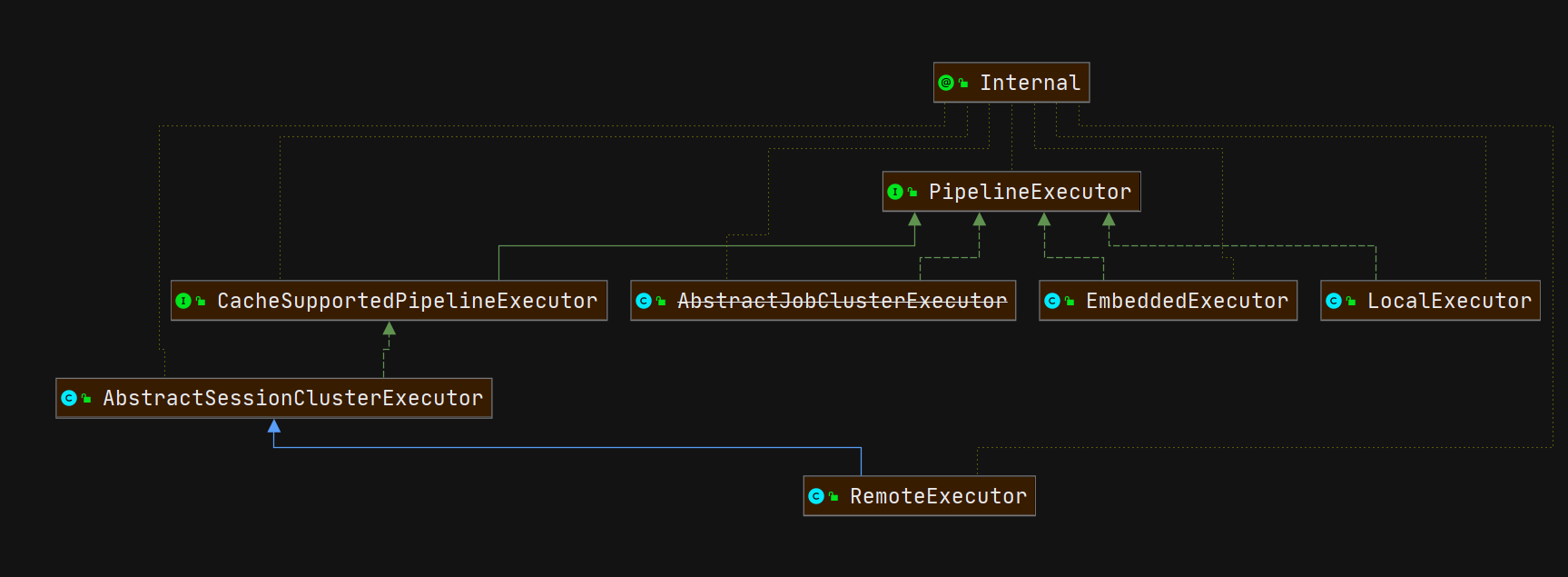
PipelineExecutor不同执行环境的接口。
PipelineExecutorServiceLoader:不同执行器的ServiceLoader
PipelineExecutorFactory:创建不同ServiceLoader的接口
看一下PipelineExecutor 接口的说明
//一个代表了执行用户作业(job)Pipeline的实体对象
@Internal
public interface PipelineExecutor {
//基于用户的configuration 执行Pipeline并且返回一个JobClient
CompletableFuture<JobClient> execute(
final Pipeline pipeline,
final Configuration configuration,
final ClassLoader userCodeClassloader)
throws Exception;
}通过executorFactory获取executor,然后使用executor执行streamGraph,PipelineExecutor 的实现由多种,这里我们先以LocalExecutor为例。LocalExecutor#execute方法代码如下:
public CompletableFuture<JobClient> execute(Pipeline pipeline, Configuration configuration, ClassLoader userCodeClassloader) throws Exception {
Preconditions.checkNotNull(pipeline);
Preconditions.checkNotNull(configuration);
Configuration effectiveConfig = new Configuration();
//配置信息
effectiveConfig.addAll(this.configuration);
effectiveConfig.addAll(configuration);
Preconditions.checkState(configuration.getBoolean(DeploymentOptions.ATTACHED));
//获取JobGraph逻辑主要在这里
JobGraph jobGraph = this.getJobGraph(pipeline, effectiveConfig, userCodeClassloader);
return PerJobMiniClusterFactory.createWithFactory(effectiveConfig, this.miniClusterFactory).submitJob(jobGraph, userCodeClassloader);
}可以看到,在PipelineExecutor接口的execute()方法中,有JobGraph的生成逻辑,然后将jobGraph提交到miniCluster上去进行下一步的操作。LocalExecutor的getJobGraph方法将是本文分析的重点。