
Hbase技术手册
Hbase技术手册
第1章 HBase简介
1.1 什么是HBase
HBase的原型是Google的BigTable论文,受到了该论文思想的启发,目前作为Hadoop的子项目来开发维护,用于支持结构化的数据存储。
- 2006年Google发表BigTable白皮书
- 2006年开始开发HBase
- 2008年北京成功开奥运会,程序员默默地将HBase弄成了Hadoop的子项目
- 2010年HBase成为Apache顶级项目
- 现在很多公司二次开发出了很多发行版本,也开始使用了。
HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBASE技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
HBase是Google Bigtable的开源实现,但是也有很多不同之处。比如:Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MAPREDUCE来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用Chubby作为协同服务,HBase利用Zookeeper作为对应。
1.2 HBase特点
1)海量存储
Hbase适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据。这与Hbase的极易扩展性息息相关。正式因为Hbase良好的扩展性,才为海量数据的存储提供了便利。
2)列式存储
这里的列式存储其实说的是列族存储,Hbase是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须指定。
3)极易扩展
Hbase的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS)。
通过横向添加RegionSever的机器,进行水平扩展,提升Hbase上层的处理能力,提升Hbsae服务更多Region的能力。
备注:RegionServer的作用是管理region、承接业务的访问,这个后面会详细的介绍通过横向添加Datanode的机器,进行存储层扩容,提升Hbase的数据存储能力和提升后端存储的读写能力。
4)高并发
由于目前大部分使用Hbase的架构,都是采用的廉价PC,因此单个IO的延迟其实并不小,一般在几十到上百ms之间。这里说的高并发,主要是在并发的情况下,Hbase的单个IO延迟下降并不多。能获得高并发、低延迟的服务。
5)稀疏
稀疏主要是针对Hbase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
1.3 HBase架构
Hbase架构如图所示:
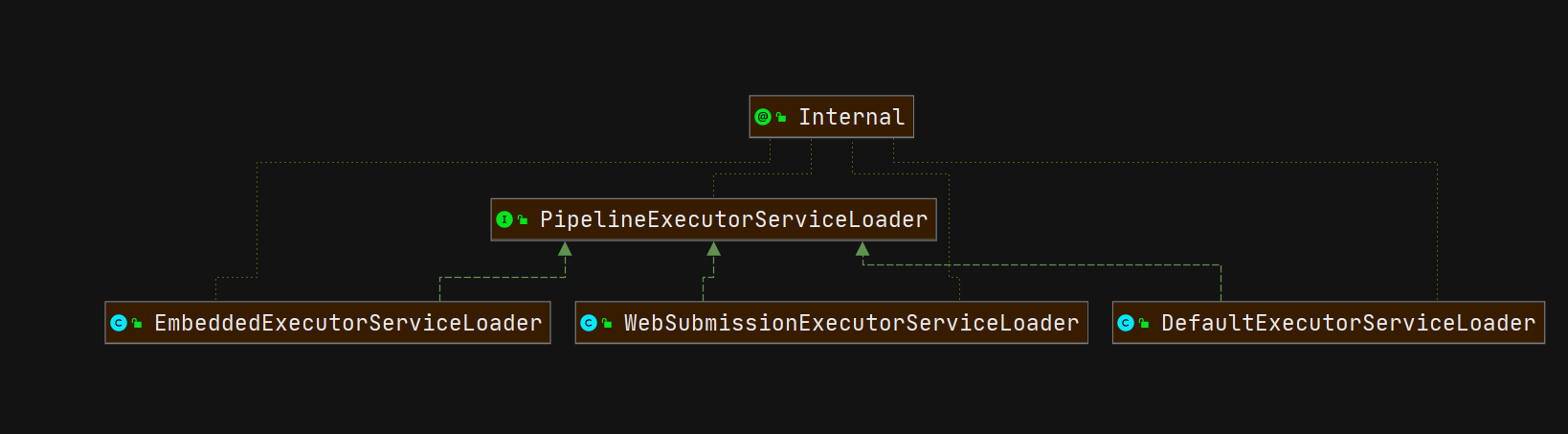
从图中可以看出Hbase是由Client、Zookeeper、Master、HRegionServer、HDFS等几个组件组成,下面来介绍一下几个组件的相关功能:
1)Client
Client包含了访问Hbase的接口,另外Client还维护了对应的cache来加速Hbase的访问,比如cache的.META.元数据的信息。
2)Zookeeper
HBase通过Zookeeper来做master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。具体工作如下:
- 高可用:通过Zoopkeeper来保证集群中只有1个master在运行,如果master异常,会通过竞争机制产生新的master提供服务
- 节点上下线:通过Zoopkeeper来监控RegionServer的状态,当RegionSevrer有异常的时候,通过回调的形式通知Master RegionServer上下线的信息
- 通过Zoopkeeper存储元数据的统一入口地址
3)Hmaster
Master 是所有 Region Server 的管理者,其实现类为 HMaster,主要作用如下:
- 为RegionServer分配Region
- 维护整个集群的负载均衡
- 维护集群的元数据信息,对于表的操作:create, delete, alter,也就是对所有表的元数据进行管理。
- 发现失效的Region,并将失效的Region分配到正常的RegionServer上,对于 RegionServer的操作:分配 regions到每个RegionServer,监控每个 RegionServer的状态,负载均衡和故障转移。如果master某一个时间挂掉的话,那么做数据级别的增删改查是可以的,但是不可以做表级别的修改。
- 当RegionSever失效的时候,协调对应Hlog的拆分
- 主要管理DDL的操作,对表进行操作。
- master自带HA高可用机制。
**4)HregionServer:Region Server 为 Region 的管理者,其实现类为 HRegionServer,**HregionServer直接对接用户的读写请求,是真正的“干活”的节点。它的功能概括如下:
- 管理master为其分配的Region
- 处理来自客户端的读写请求,对于数据的操作:get, put, delete;
- 负责和底层HDFS的交互,存储数据到HDFS
- 负责Region变大以后的拆分,对于 Region 的操作:splitRegion、compactRegion。
- 负责Storefile的合并工作
- 主要管理DML操作,也就是主要对数据进行操作。
5)HDFS
HDFS为Hbase提供最终的底层数据存储服务,同时为HBase提供高可用(Hlog存储在HDFS)的支持,具体功能概括如下:
- 提供元数据和表数据的底层分布式存储服务
- 数据多副本,保证的高可靠和高可用性
1.3 HBase中的角色
1.3.1 HMaster
功能
1.监控RegionServer
2.处理RegionServer故障转移
3.处理元数据的变更
4.处理region的分配或转移
5.在空闲时间进行数据的负载均衡
6.通过Zookeeper发布自己的位置给客户端
1.3.2 RegionServer
功能
1.负责存储HBase的实际数据
2.处理分配给它的Region
3.刷新缓存到HDFS
4.维护Hlog
5.执行压缩
6.负责处理Region分片
1.2.3 其他组件
1.Write-Ahead logs
HBase的修改记录,当对HBase读写数据的时候,数据不是直接写进磁盘,它会在内存中保留一段时间(时间以及数据量阈值可以设定)。但把数据保存在内存中可能有更高的概率引起数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile的文件中,然后再写入内存中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
由于数据要经MemStore排序后才能刷写到HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile的文件中,然后再写入MemStore中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
2.Region
Hbase表的分片,HBase表会根据RowKey值被切分成不同的region存储在RegionServer中,在一个RegionServer中可以有多个不同的region。
3.Store
HFile存储在Store中,一个Store对应HBase表中的一个列族。
4.MemStore
顾名思义,就是内存存储,位于内存中,用来保存当前的数据操作,所以当数据保存在WAL中之后,RegsionServer会在内存中存储键值对。
5.StoreFile(HFile)
这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。StoreFile是以Hfile的形式存储在HDFS的。每个Store会有一个或多个StoreFile(HFile),数据在每个StoreFile中都是有序的。
- MemStore
写缓存,由于HFile中的数据要求是有序的,所以数据是先存储在MemStore中,排好序后,等到达刷写时机才会刷写到HFile,每次刷写都会形成一个新的HFile。
- BlockCache
读缓存,每次查询出的数据会缓存在BlockCache中,方便下次查询。
1.4、Hbase数据模型
逻辑上,HBase 的数据模型同关系型数据库很类似,数据存储在一张表中,有行有列。
但从 HBase 的底层物理存储结构(K-V)来看,HBase 更像是一个 multi-dimensional map。
namespace—→数据库
region—→表
row—→行
column—→列
Name Space
命名空间,类似于关系型数据库的 DatabBase 概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别是 hbase 和 default,hbase 中存放的是 HBase 内置的表,default 表是用户默认使用的命名空间。
可以简单的把命名空间理解为mysql中的数据库。
Region
类似于关系型数据库的表概念。不同的是,HBase 定义表时只需要声明列族即可,不需要声明具体的列。这意味着,往 HBase 写入数据时,字段可以动态、按需指定。因此,和关系型数据库相比,HBase 能够轻松应对字段变更的场景。
Row
HBase 表中的每行数据都由一个 RowKey 和多个 Column(列)组成,数据是按照 RowKey的字典顺序存储的,并且查询数据时只能根据 RowKey 进行检索,所以 RowKey 的设计十分重要。
Column
HBase 表中的每行数据都由一个 RowKey 和多个 Column(列)组成,数据是按照 RowKey的字典顺序存储的,并且查询数据时只能根据 RowKey 进行检索,所以 RowKey 的设计十分重要。
Time Stamp
用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会自动为其加上该字段,其值为写入 HBase 的时间。除了版本和值不同以外,其他的部分必须相同
Cell
由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。cell 中的数据是没有类型的,全部是字节码形式存贮。
1.5、Hbase逻辑结构
一个大表可以切分为多个Region,Region在表中叫做切片,接下来是列族,列族下面是列,接下来是值,但是值可能是覆盖其他数据的值,所以在HBase要想确定一个数据,需要根据列族,列row_key和时间戳可以唯一确定一条数据记录。根据这些条件唯一确定的数据记录又叫做一个cell。单元格中所有的数据都没有数据类型,在底层全部是字节数组存储。表和Region有对应关系,因为一张表可以进行横向和纵向的切分操作,形成切片,最小可以切分为cell。
1.6、Hbase物理存储结构

第2章 HBase安装
2.1 Zookeeper正常部署
首先保证Zookeeper集群的正常部署,并启动之:
[rzf@hadoop102 zookeeper-3.4.10]$ bin/zkServer.sh start
[rzf@hadoop103 zookeeper-3.4.10]$ bin/zkServer.sh start
[rzf@hadoop104 zookeeper-3.4.10]$ bin/zkServer.sh start2.2 Hadoop正常部署
Hadoop集群的正常部署并启动:
[rzf@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
[rzf@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh2.3 HBase的解压
解压HBase到指定目录:
[rzf@hadoop102 software]$ tar -zxvf hbase-1.3.1-bin.tar.gz -C /opt/module2.4 HBase的配置文件
修改HBase对应的配置文件。
1)hbase-env.sh修改内容:
export JAVA_HOME=/opt/module/jdk1.8.0_144
export HBASE_MANAGES_ZK=false2)hbase-site.xml修改内容:
<configuration>
<name>hbase.rootdir</name>
</property>
<property>
<value>true</value>
<property>
<value>16000</value>
<name>hbase.zookeeper.quorum</name>
</property>
<property>
<value>/opt/module/zookeeper-3.4.10/zkData</value>
</configuration>3)regionservers:
hadoop102
hadoop1044)软连接hadoop配置文件到hbase:
[rzf@hadoop102 module]$ ln -s /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml
/opt/module/hbase/conf/core-site.xml
[rzf@hadoop102 module]$ ln -s /opt/module/hadoop-2.7.2/etc/hadoop/hdfs-site.xml
/opt/module/hbase/conf/hdfs-site.xml2.5 HBase远程发送到其他集群
[rzf@hadoop102 module]$ xsync hbase/
2.6 HBase服务的启动
1.启动方式1
[rzf@hadoop102 hbase]$ bin/hbase-daemon.sh start master
[rzf@hadoop102 hbase]$ bin/hbase-daemon.sh start regionserver
提示:如果集群之间的节点时间不同步,会导致regionserver无法启动,抛出ClockOutOfSyncException异常。
修复提示:
- 同步时间服务
- 属性:hbase.master.maxclockskew设置更大的值
<property>
<value>180000</value>
</property>2.启动方式2
[rzf@hadoop102 hbase]$ bin/start-hbase.sh
对应的停止服务:
[rzf@hadoop102 hbase]$ bin/stop-hbase.sh
2.7 查看HBase页面
启动成功后,可以通过“host:port”的方式来访问HBase管理页面,例如:
第3章 HBase Shell操作
3.1 基本操作
1.进入HBase客户端命令行
[rzf@hadoop102 hbase]$ bin/hbase shell2.查看帮助命令
hbase(main):001:0> help3.查看当前数据库中有哪些表
//默认看不到系统表
hbase(main):002:0> list3.2 表的操作
1.创建表
//创建一个student表并且查看,create 后面直接添加表名,表名后面紧跟着的是列族
hbase(main):002:0> create 'student','info'
//创建具有两个列族的表
hbase(main):009:0> create 'stu','info1','info2'2.插入数据到表
hbase(main):003:0> put 'student','1001','info:sex','male'
hbase(main):004:0> put 'student','1001','info:age','18'
hbase(main):005:0> put 'student','1002','info:name','Janna'
hbase(main):006:0> put 'student','1002','info:sex','female'
hbase(main):007:0> put 'student','1002','info:age','20'3.扫描查看表数据
hbase(main):008:0> scan 'student'
hbase(main):009:0> scan 'student',{STARTROW => '1001', STOPROW => '1001'}
hbase(main):010:0> scan 'student',{STARTROW => '1001'}4.查看表结构
hbase(main):011:0> describe ‘student’5.更新指定字段的数据
列族是最小的修改单元
hbase(main):012:0> put 'student','1001','info:name','Nick'
hbase(main):013:0> put 'student','1001','info:age','100'6.查看“指定行”或“指定列族:列”的数据
hbase(main):014:0> get 'student','1001'
hbase(main):015:0> get 'student','1001','info:name'7.统计表数据行数
hbase(main):021:0> count 'student'8.删除数据
删除某rowkey的全部数据:
hbase(main):016:0> deleteall 'student','1001'删除某rowkey的某一列数据:
hbase(main):017:0> delete 'student','1002','info:sex'9.清空表数据
hbase(main):018:0> truncate 'student'提示:清空表的操作顺序为先disable,然后再truncate。
10.删除表
首先需要先让该表为disable状态:
hbase(main):019:0> disable 'student'然后才能drop这个表:
hbase(main):020:0> drop 'student'提示:如果直接drop表,会报错:ERROR: Table student is enabled. Disable it first.
11.变更表信息
将info列族中的数据存放3个版本:
hbase(main):022:0> alter 'student',{NAME=>'info',VERSIONS=>3}
hbase(main):022:0> get 'student','1001',{COLUMN=>'info:name',VERSIONS=>3}- 查看命名空间,相当于数据库
hbase(main):008:0> list_namespace
NAMESPACE
default
hbase
//创建命名空间
hbase(main):009:0> create_namespace 'bigTable'
0 row(s) in 0.9330 seconds
hbase(main):010:0> list_namespace
NAMESPACE
bigTable
default
hbase
3 row(s) in 0.0450 seconds- 在命名空间下创建一张表
hbase(main):011:0> create "bigTable:stu","info"
0 row(s) in 2.3340 seconds
=> Hbase::Table - bigTable:stu
//查看
hbase(main):012:0> list
TABLE
bigTable:stu
stu
2 row(s) in 0.0170 seconds
=> ["bigTable:stu", "stu"]如果表的前面没有命名空间名字,那么就是说表在default命名空间下
- 删除命名空间
不能删除非空的命名空间,要想删除,必须先把命名空间中的表全部下线,然后在删除命名空间
//先让命名空间下的表全部下线
hbase(main):013:0> disable "bigTable:stu"
0 row(s) in 2.3380 seconds
//然后在删除命名空间下的表
hbase(main):014:0> drop "bigTable:stu"
0 row(s) in 1.3060 seconds
hbase(main):015:0> list
TABLE
stu
1 row(s) in 0.0190 seconds
=> ["stu"]
//最后在删除命名空间
hbase(main):016:0> drop_namespace "bigTable"
0 row(s) in 0.9300 seconds
hbase(main):017:0> list_namespace
NAMESPACE
default
hbaseDML操作
- 向表中put数据
//需要四个参数信息
hbase> put 'ns1:t1', 'r1', 'c1', 'value'
'ns1:t1':命名空间下的表名
r1:表示row_KEY
c1:表示列信息,需要指出列族,列族:列名
value:插入的数据
//向stu表的info1列族下的name列插入名字张三
hbase(main):021:0> put "default:stu",'1001','info1:name',"张三"
//插入一些数据
hbase(main):034:0> scan 'stu'
ROW COLUMN+CELL
1001 column=info1:name, timestamp=1616821229741, value=\xE5\xBC\xA0\xE4\xB8\x89
1001 column=info1:sex, timestamp=1616821744141, value=male
1001 column=info2:addr1, timestamp=1616821799187, value=shanghai
1002 column=info1:name, timestamp=1616821926859, value=lisi
1002 column=info1:phone1, timestamp=1616821930949, value=123456
1003 column=info2:addr, timestamp=1616821970138, value=beijing
//有多少个row_key就有多少条数据
3 row(s) in 0.0580 second- 查询数据
- 第一种查询,直接扫描全表
hbase(main):022:0> scan 'stu'
ROW COLUMN+CELL
1001 column=info1:name, timestamp=1616821229741, value=\xE5\xBC\xA0\xE4\xB8\x89 //发生中文乱码
//scan也可以进行范围扫描,区间是左闭右开
hbase(main):040:0> scan 'stu',{STARTROW=>'1001',STOPROW=>'1003'}
ROW COLUMN+CELL
1001 column=info1:name, timestamp=1616821229741, value=\xE5\xBC\xA0\xE4\xB8\x89
1001 column=info1:sex, timestamp=1616821744141, value=male
1001 column=info2:addr1, timestamp=1616821799187, value=shanghai
1002 column=info1:name, timestamp=1616821926859, value=lisi
1002 column=info1:phone1, timestamp=1616821930949, value=123456
//重新插入数据 10010
hbase(main):041:0> put 'stu','10010','info1:name','banzhang'
0 row(s) in 0.0280 seconds
hbase(main):042:0> scan 'stu'
ROW COLUMN+CELL
1001 column=info1:name, timestamp=1616821229741, value=\xE5\xBC\xA0\xE4\xB8\x89
1001 column=info1:sex, timestamp=1616821744141, value=male
1001 column=info2:addr1, timestamp=1616821799187, value=shanghai
10010 column=info1:name, timestamp=1616822799179, value=banzhang
1002 column=info1:name, timestamp=1616821926859, value=lisi
1002 column=info1:phone1, timestamp=1616821930949, value=123456
1003 column=info2:addr, timestamp=1616821970138, value=beijing
//插入是按照row_key的字典顺序进行插入- 第二种查询,使用get
hbase(main):024:0> get 'stu','1001'
COLUMN CELL
info1:name timestamp=1616821229741, value=\xE5\xBC\xA0\xE4\xB8\x89
//get案例
hbase> t.get 'r1'
hbase> t.get 'r1', {TIMERANGE => [ts1, ts2]}
hbase> t.get 'r1', {COLUMN => 'c1'}
hbase> t.get 'r1', {COLUMN => ['c1', 'c2', 'c3']}
hbase> t.get 'r1', {COLUMN => 'c1', TIMESTAMP => ts1}
hbase> t.get 'r1', {COLUMN => 'c1', TIMERANGE => [ts1, ts2], VERSIONS => 4}
hbase> t.get 'r1', {COLUMN => 'c1', TIMESTAMP => ts1, VERSIONS => 4}
hbase> t.get 'r1', {FILTER => "ValueFilter(=, 'binary:abc')"}
hbase> t.get 'r1', 'c1'
hbase> t.get 'r1', 'c1', 'c2'
hbase> t.get 'r1', ['c1', 'c2']
hbase> t.get 'r1', {CONSISTENCY => 'TIMELINE'}
hbase> t.get 'r1', {CONSISTENCY => 'TIMELINE', REGION_REPLICA_ID => 1}
//查询row_key=1001的数据,显示的是三个列,每一个列都对应有自己的时间戳
hbase(main):035:0> get 'stu','1001'
COLUMN CELL
info1:name timestamp=1616821229741, value=\xE5\xBC\xA0\xE4\xB8\x89
info1:sex timestamp=1616821744141, value=male
info2:addr1 timestamp=1616821799187, value=shanghai
//也可以指定查看某一个列族下的列
hbase(main):037:0> get 'stu','1001','info1:name'
COLUMN CELL
info1:name timestamp=1616821229741, value=\xE5\xBC\xA0\xE4\xB8\x89
//查看指定列族下的所有列和其值
hbase(main):038:0> get 'stu','1001','info1'
COLUMN CELL
info1:name timestamp=1616821229741, value=\xE5\xBC\xA0\xE4\xB8\x89
info1:sex timestamp=1616821744141, value=maleget可以根据row_key查看某一条数据的全部信息,可以指定:列族:列查看某列的信息,也可以只指定:列族查看列族下的某条数据全部信息
- 修改数据
hbase里面没有直接的alter更改数据操作,但是可以通过put对数据记性更新操作
//通过put更新操作修改数据
hbase(main):043:0> put 'stu','1001','info1:name','zhangsansan'
0 row(s) in 0.0280 seconds
hbase(main):044:0> scan 'stu'
ROW COLUMN+CELL
1001 column=info1:name, timestamp=1616823351586, value=zhangsansan
1001 column=info1:sex, timestamp=1616821744141, value=male
1001 column=info2:addr1, timestamp=1616821799187, value=shanghai
10010 column=info1:name, timestamp=1616822799179, value=banzhang
1002 column=info1:name, timestamp=1616821926859, value=lisi
1002 column=info1:phone1, timestamp=1616821930949, value=123456
1003 column=info2:addr, timestamp=1616821970138, value=beijing //但是此时数据并没有被真正的删除,VERSIONS => 10表示查看10个版本内的数据
hbase(main):046:0> scan 'stu', {RAW => true, VERSIONS => 10}
ROW COLUMN+CELL
1001 column=info1:name, timestamp=1616823351586, value=zhangsansan
1001 column=info1:name, timestamp=1616821229741, value=\xE5\xBC\xA0\xE4\xB8\x89
1001 column=info1:sex, timestamp=1616821744141, value=male
1001 column=info2:addr1, timestamp=1616821799187, value=shanghai
10010 column=info1:name, timestamp=1616822799179, value=banzhang
1002 column=info1:name, timestamp=1616821926859, value=lisi
1002 column=info1:name, timestamp=1616821919699, value=lisi
1002 column=info1:phone1, timestamp=1616821930949, value=123456
1002 column=info1:phone1, timestamp=1616821919738, value=123456
1003 column=info2:addr, timestamp=1616821970138, value=beijing
4 row(s) in 0.0320 seconds
//但是使用get查询的话只能查到最新的数据
//修改时间戳插入一条数据
hbase(main):048:0> put 'stu','1001','info1:name','lisansan' ,1616823351587
0 row(s) in 0.0330 seconds
//查询数据
hbase(main):050:0> get 'stu','1001'
COLUMN CELL
info1:name timestamp=1616823351587, value=lisansan
info1:sex timestamp=1616821744141, value=male
info2:addr1 timestamp=1616821799187, value=shanghai
//可以看到,返回的是最新时间戳的数据,也就是我们修改数据的时候,时间戳一定要比之前的时间戳新,因为get每一次返回的是最新时间戳的数据- 删除数据
delete 'ns1:t1', 'r1', 'c1', ts1
ns1:t1:某一个命名空间下的一张表
r1:表示row_key信息
c1:表示列名
ts1:表示时间戳,可以没有
//删除row_key为1001的sex信息
hbase(main):052:0> delete 'stu','1001','info1:sex'
0 row(s) in 0.0600 seconds
hbase(main):053:0> scan 'stu'
ROW COLUMN+CELL
1001 column=info1:name, timestamp=1616823351587, value=lisansan
1001 column=info2:addr1, timestamp=1616821799187, value=shanghai
10010 column=info1:name, timestamp=1616822799179, value=banzhang
1002 column=info1:name, timestamp=1616821926859, value=lisi
1002 column=info1:phone1, timestamp=1616821930949, value=123456
1003 column=info2:addr, timestamp=1616821970138, value=beijing
//现在name属性有三个版本,删除name后发现三个版本全部删除,因为插入的时候是覆盖操作,所以如果删除那么前面的版本数据也会全部删除
hbase(main):054:0> delete 'stu','1001','info1:name'
0 row(s) in 0.0190 seconds
hbase(main):055:0> scan 'stu'
ROW COLUMN+CELL
1001 column=info2:addr1, timestamp=1616821799187, value=shanghai
10010 column=info1:name, timestamp=1616822799179, value=banzhang
1002 column=info1:name, timestamp=1616821926859, value=lisi
1002 column=info1:phone1, timestamp=1616821930949, value=123456
1003 column=info2:addr, timestamp=1616821970138, value=beijing在查询name列的时候,发现已经打上Delete标记,所以就不会返回结果信息
deleteall可以根据指定的row_key删除全部记录信息
hbase> deleteall 'ns1:t1', 'r1'
ns1:t1:表示某一个命名空间下的表
r1:表示row_key
hbase(main):069:0> deleteall 'stu','1001'
0 row(s) in 0.0160 seconds
hbase(main):070:0> scan 'stu'
ROW COLUMN+CELL
1002 column=info1:name, timestamp=1616821926859, value=lisi
1002 column=info1:phone1, timestamp=1616821930949, value=123456
1003 column=info2:addr, timestamp=1616821970138, value=beijing所有的增删改查都是根据时间戳进行的
- 查询多个版本数据信息
//创建表
hbase(main):071:0> create 'stu2','info'
//插入数据
hbase(main):073:0> put 'stu2','1005','info:name','zhangsan'
//修改表的信息,版本修改为2
hbase(main):076:0> alter 'stu2',{NAME=>'info',version=>2}
//重新插入数据,只不过是两个版本
hbase(main):077:0> put 'stu2','1001','info:name','zhangsan'
0 row(s) in 0.0430 seconds
hbase(main):078:0> put 'stu2','1001','info:name','lisi'
0 row(s) in 0.0200 seconds
//指定查询多少个版本的数据
hbase(main):084:0> get 'stu2','1001',{COLUMN=>'info:name',VERSIONS=>3}版本说明:修改后列族的版本后,就是表示将来hbase为我们存储几个版本,查询时候指定的版本数量要和设定的版本数量一致,否则无法查询,比如设置的是5个版本,那么将来hbase就为我们存储5个版本的数据,如果我们put进去的数据版本数大于5的话,其他的版本hbase认为是将来会删除的,不会为我们存储,我们设定多少个版本,hbase为我们存储多少个版本。
一句话说明:就是如果你put了10个版本的数据,但是设定的版本数是5,那么hbase只为我们保存5个版本的数据,其他5个版本最终会删除,保存的版本一定是时间戳最新的。
第4章 HBase数据结构
4.1 RowKey
与nosql数据库们一样,RowKey是用来检索记录的主键。访问HBASE table中的行,只有三种方式:
1.通过单个RowKey访问
2.通过RowKey的range(正则)
3.全表扫描
RowKey行键 (RowKey)可以是任意字符串(最大长度是64KB,实际应用中长度一般为 10-100bytes),在HBASE内部,RowKey保存为字节数组。存储时,数据按照RowKey的字典序(byte order)排序存储。设计RowKey时,要充分排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)
4.2 Column Family
列族:HBASE表中的每个列,都归属于某个列族。列族是表的schema的一部分(而列不是),必须在使用表之前定义。列名都以列族作为前缀。例如 courses:history,courses:math都属于courses 这个列族。
4.3 Cell
由{rowkey, column Family:columu, version} 唯一确定的单元。cell中的数据是没有类型的,全部是字节码形式存贮。
关键字:无类型、字节码
4.4 Time Stamp
HBASE 中通过rowkey和columns确定的为一个存贮单元称为cell。每个 cell都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是64位整型。时间戳可以由HBASE(在数据写入时自动 )赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版 本冲突,就必须自己生成具有唯一性的时间戳。每个 cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,HBASE提供 了两种数据版本回收方式。
- 一是保存数据的最后n个版本
- 二是保存最近一段时间内的版本(比如最近七天)。
用户可以针对每个列族进行设置。
4.5 命名空间
命名空间的结构:
1) Table:表,所有的表都是命名空间的成员,即表必属于某个命名空间,如果没有指定,则在default默认的命名空间中。
**2) RegionServer group:**一个命名空间包含了默认的RegionServer Group。
**3) Permission:**权限,命名8空间能够让我们来定义访问控制列表ACL(Access Control List)。例如,创建表,读取表,删除,更新等等操作。
**4) Quota:**限额,可以强制一个命名空间可包含的region的数量。
第5章 HBase原理
5.1、Hbase架构原理
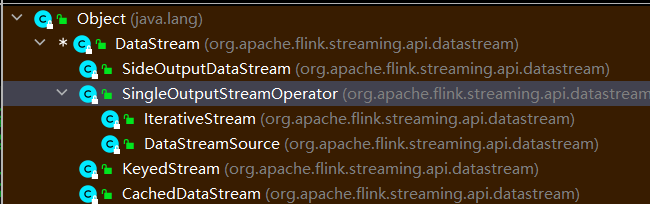
- HBase两个核心的组件,HMaster,HRegionServer两个进程,HBase依赖于zookeeper和hdfs。
- Hmaster管理ddl操作,master决定region给哪一个RegionServer进行维护。
- RegionServer管理DML操作。
- HLogs(write ahead log)相当于hdfs中的Edits文件,叫做预写入文件,目的是防止内存挂掉,所以专门用来记录操作,进行数据的恢复,他会记录每一步操作,写入hdfs中。
- 一个RegionServer中可以有很多Regions
- HRegion和表有对应关系,一张表有一个或者多个Regions,按照行进行切分出来的
- Store就相当于表中的列族,Store在hdfs上对应的是文件夹,可以类比hive中分区的划分,可以加速查询,查询数据可以扫描对应的文件夹即可,不需要全表扫描,一个Region下面可以有多个列族,也就是Store,存储结构是以文件夹的形式存在.
- 列族下面存储的是数据,对于HBase来说,列族下面的列就相当于数据,因为列是在插入数据时候进行指定的。
- 存储数据在内存或者磁盘,从内存到磁盘的过程叫做Flush操作,刷写一次会形成一个文件,所以会产生很多小文件,小文件会自动进行合并操作,如果文件过大,还会进行再一次的切分操作。
- 最后存储到磁盘,文件会以HFile格式进行存储,是以键值对形式存储,HFile是一种文件格式。
- 刷写过程中会调用hdfs的客户端把数据存储在hdfs上面,这一些列的操作都是由RegionServer进行完成的,HLog会一直进行落盘操作.
- 如果做的是DML操作,那么即使master挂掉也没问题,因为DML操作是和zookeeper进行交互的,这就是zookeeper帮助master分担的工作。但是DDL操作的话,master挂掉之后就无法操作。
- 所有的操作会首先连接zookeeper,
- StoreFile
保存实际数据的物理文件,StoreFile 以 HFile 的形式存储在 HDFS 上。每个 Store 会有一个或多个 StoreFile(HFile),数据在每个 StoreFile 中都是有序的。 - MemStore
写缓存,由于 HFile 中的数据要求是有序的,所以数据是先存储在 MemStore 中,排好序后,等到达刷写时机才会刷写到 HFile,每次刷写都会形成一个新的 HFile。 - WAL
由于数据要经 MemStore 排序后才能刷写到 HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写在一个叫做 Write-Ahead logfile(Hlog) 的文件中,然后再写入 MemStore 中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
5.2 读流程
- Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。也就是先获取命名空间找到元数据表的存储位置,所有表的元数据信息都存储在meta表中。
- 访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey,查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。
- 与目标 Region Server 进行通讯;
- 分别在 Block Cache(读缓存),MemStore 和 Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的(Put/Delete)。
- 将从文件中查询到的数据块(Block,HFile 数据存储单元,默认大小为 64KB)缓存到Block Cache。
- 将合并后的最终结果返回给客户端。
注意:读取的数据的时候是根据时间戳来的,不管是读取内存,还是读取磁盘,永远读取的是最新的数据,也就是时间戳最大的数据,会把内存中的数据和磁盘中的数据拿出来进行比较操作,返回时间戳最大的数据,也就是最新的数据。每一次都进行磁盘的扫描,时间很慢,所以就添加block cache缓存空间。block cache仅仅对磁盘中的文件有效,新写入的数据一定会写入洗盘,然后下一次读取数据的时候,会首先看block cache中是否有数据,如果有的话直接就返回,否则就从磁盘中读取,然后再把从磁盘中读取的数据添加到block cache文件中,供下次读取使用。
读比写慢的原因是无论如何都要进行读磁盘操作。
5.3 写流程
HBase是一个读比写入慢的框架
- Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。客户端访问数据首先和zookeeper进行交互操作。
- 访问对应的 Region Server,获取 hbase:meta 表,也就是获取命名空间的位置,根据读请求的 namespace:table/rowkey,查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。
- 与目标 Region Server 进行通讯;也就是访问目标RegionServer
- 将数据顺序写入(追加)到 WAL;首先写入日志文件中,然后在预写到内存中。但是实际上写入复杂的多
- 将数据写入对应的 MemStore,数据会在 MemStore 进行排序;
- 向客户端发送 ack;
- 等达到 MemStore 的刷写时机后,将数据刷写到 HFile。
5.4 数据Flush过程(MemStore Flush)
1)当MemStore数据达到阈值(默认是128M,老版本是64M),将数据刷到硬盘,将内存中的数据删除,同时删除HLog中的历史数据;若Region中有多个Store,只要有其中一个达到默认值128M)值,就会触发flush。
a、刷写阈值
hbase.hregion.memstore.flush.size(默认值128M)当memstore的大小超过以下条件,会阻止继续往该memstore写数据。
hbase.hregion.memstore.flush.size(默认值128M)
hbase.hregion.memstore.block.multiplier(默认值4)b、当region server中memstore的总大小达到下面配置时,会阻止继续往所有的memstore写数据。
hbase.regionserver.global.memstore.size(默认值0.4)当region server中memstore的总大小低于数值时候,才取消阻塞(允许写入数据)。
hbase.regionserver.global.memstore.size(默认值0.4)
hbase.regionserver.global.memstore.size.lower.limit(默认值0.95)如果 HBase 堆内存总共是 5G,按照默认的比例,那么触发 RegionServer级别的flush ,是 RegionServer 中所有的 MemStore 占用内存为:5 * 0.4 * 0.95 = 1.9G时触发flush,此时是允许写入操作的,若写入操作大于flush的速度,当占用内存达到 5 * 0.4 = 2G 时,阻止所有写入操作,直到占用内存低于 1.9G ,才取消阻塞,允许写入。
c、如果自动刷写的时间,也会触发memstore flush。自动刷新的时间间隔由该属性进行配置。
hbase.regionserver.optionalcacheflushinterval(默认1小时)c、当WAL文件的数量超过hbase.regionserver.max.logs(最大值为32),region会按照时间顺序依次进行刷写。
d、手动刷写
2)并将数据存储到HDFS中;
3)在HLog中做标记点。
每一次进行刷写操作都会形成一个文件,同一个Region写的不同store是不同的列族,不同的列族刷写到hdfs上面是不同的文件夹。最后合并文件的时候只会在相同的列族下面合并文件。
MemStore 刷写时机:
- 当某个 memstroe 的大小达到了 hbase.hregion.memstore.flush.size(默认值 128M),其所在 region 的所有 memstore 都会刷写。
- 当 memstore 的大小达到了hbase.hregion.memstore.flush.size(默认值 128M)hbase.hregion.memstore.block.multiplier(默认值 4)时,会阻止继续往该 memstore 写数据。这个时候往往是因为写入的速度太快,所以要阻止写入操作。
- 当 region server 中 memstore 的总大小达到java_heapsize,hbase.regionserver.global.memstore.size(默认值 0.4)hbase.regionserver.global.memstore.size.lower.limit(默认值 0.95),region 会按照其所有memstore 的大小顺序(由大到小)依次进行刷写。直到 region server中所有 memstore 的总大小减小到上述值以下。
- 当 region server 中 memstore 的总大小达java_heapsize*hbase.regionserver.global.memstore.size(默认值 0.4)时,会阻止继续往所有的 memstore 写数据。
- 到达自动刷写的时间,也会触发 memstore flush。自动刷新的时间间隔由该属性进行
配置 hbase.regionserver.optionalcacheflushinterval(默认 1 小时)。 - 当 WAL 文件的数量超过 hbase.regionserver.max.logs,region 会按照时间顺序依次进行刷写,直到 WAL 文件数量减小到 hbase.regionserver.max.log 以下(该属性名已经废弃,现无需手动设置,最大值为 32)。
从内存将数据刷写到htfs:
flush 'stu'5.5 数据合并过程
1)当数据块达到4块,Hmaster触发合并操作,Region将数据块加载到本地,进行合并;
2)当合并的数据超过256M,进行拆分,将拆分后的Region分配给不同的HregionServer管理;
3)当HregionServer宕机后,将HregionServer上的hlog拆分,然后分配给不同的HregionServer加载,修改.META.;
4)注意:HLog会同步到HDFS。
5.6、StoreFile Compaction
- 由于memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能会分布在不同的 HFile 中,因此查询时需要遍历所有的 HFile。为了减少 HFile 的个数,以及清理掉过期和删除的数据,会进行 StoreFile Compaction。
- Compaction 分为两种,分别是 Minor Compaction 和 Major Compaction。
- Minor Compaction会将临近的若干个较小的 HFile 合并成一个较大的 HFile,但不会清理过期和删除的数据。
- Major Compaction 会将一个 Store 下的所有的 HFile 合并成一个大 HFile,并且会清理掉过期和删除的数据。但是不会立即清理掉所有合并过的文件,因为需要保证数据的一致性问题,所以还会等待一会,然后才会删除合并过的文件。
从上面可以发现,数据的读写全程没有master的参与,所以如果仅仅进行dml的操作,那么就不需要master参与也是可以完成的,但是长期这样做很不安全,因为当数据量大的情况下,一个表会切分为很多的Region,这样,如果master不可以工作,那么所有的Region会分布在一台机器上,所以不是很安全,因为所有的Region需要被master调度到其他的节点上面存储。
删除数据:
在大合并的时候,会删除数据,小合并不会删除数据
Flush或者major大合并的时候会删除数据
- flush删除数据只有数据在内存中的话才会删除,不能删除跨越多个文件的数据,flush仅仅会操作内存,不会操作磁盘。
- 合并操作会把所有的数据加载到内存当中,然后重写的时候,会把过时的数据删除,也就是删除时间戳小的数据。
- 删除标记是在大合并的时候删除
5.7、Region Split
默认情况下,每个 Table 起初只有一个 Region,随着数据的不断写入,Region 会自动进行拆分。刚拆分时,两个子 Region 都位于当前的 Region Server,但处于负载均衡的考虑,HMaster 有可能会将某个 Region 转移给其他的 Region Server。
Region Split 时机:
- 当1个region中的某个Store下所有StoreFile的总大小超过hbase.hregion.max.filesize,该 Region 就会进行拆分(0.94 版本之前)。
- 当 1 个 region 中 的 某 个 Store 下所有 StoreFile 的 总 大 小 超 过 Min(R^2"hbase.hregion.memstore.flush.size",hbase.hregion.max.filesize"),该 Region 就会进行拆分,其中 R 为当前 Region Server 中属于该 Table 的个数(0.94 版本之后)。
Min(initialSize*R^3 ,hbase.hregion.max.filesize")
其中initialSize的默认值为2*hbase.hregion.memstore.flush.size
R为当前Region Server中属于该Table的Region个数)
具体的切分策略为:
第一次split:1^3 * 256 = 256MB
第二次split:2^3 * 256 = 2048MB
第三次split:3^3 * 256 = 6912MB
第四次split:4^3 * 256 = 16384MB > 10GB,因此取较小的值10GB
后面每次split的size都是10GB了。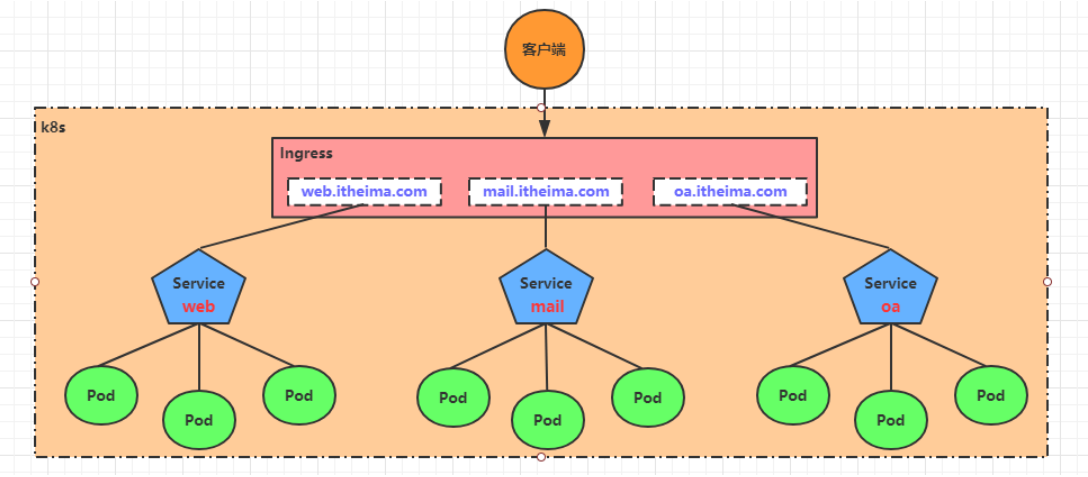
第6章 HBase API操作
6.1 环境准备
新建项目后在pom.xml中添加依赖:
<dependency>
<artifactId>hbase-server</artifactId>
</dependency>
<dependency>
<artifactId>hbase-client</artifactId>
</dependency>
<dependency>
<artifactId>jdk.tools</artifactId>
<scope>system</scope>
</dependency>6.2 HBaseAPI
6.2.1 获取Configuration对象
public static Configuration conf;
//使用HBaseConfiguration的单例方法实例化
conf.set("hbase.zookeeper.quorum", "192.168.9.102");
}6.2.2 判断表是否存在
public static boolean isTableExist(String tableName) throws MasterNotRunningException,
//在HBase中管理、访问表需要先创建HBaseAdmin对象
//HBaseAdmin admin = (HBaseAdmin) connection.getAdmin();
return admin.tableExists(tableName);6.2.3 创建表
public static void createTable(String tableName, String... columnFamily) throws
HBaseAdmin admin = new HBaseAdmin(conf);
if(isTableExist(tableName)){
//System.exit(0);
//创建表属性对象,表名需要转字节
//创建多个列族
descriptor.addFamily(new HColumnDescriptor(cf));
//根据对表的配置,创建表
System.out.println("表" + tableName + "创建成功!");
}6.2.4 删除表
public static void dropTable(String tableName) throws MasterNotRunningException,
HBaseAdmin admin = new HBaseAdmin(conf);
admin.disableTable(tableName);
System.out.println("表" + tableName + "删除成功!");
System.out.println("表" + tableName + "不存在!");
}6.2.5 向表中插入数据
public static void addRowData(String tableName, String rowKey, String columnFamily, String
//创建HTable对象
//向表中插入数据
//向Put对象中组装数据
hTable.put(put);
System.out.println("插入数据成功");6.2.6 删除多行数据
public static void deleteMultiRow(String tableName, String... rows) throws IOException{
List<Delete> deleteList = new ArrayList<Delete>();
Delete delete = new Delete(Bytes.toBytes(row));
}
hTable.close();6.2.7 获取所有数据
public static void getAllRows(String tableName) throws IOException{
//得到用于扫描region的对象
//使用HTable得到resultcanner实现类的对象
for(Result result : resultScanner){
for(Cell cell : cells){
System.out.println("行键:" + Bytes.toString(CellUtil.cloneRow(cell)));
System.out.println("列族" + Bytes.toString(CellUtil.cloneFamily(cell)));
System.out.println("值:" + Bytes.toString(CellUtil.cloneValue(cell)));
}6.2.8 获取某一行数据
public static void getRow(String tableName, String rowKey) throws IOException{
Get get = new Get(Bytes.toBytes(rowKey));
//get.setTimeStamp();显示指定时间戳的版本
for(Cell cell : result.rawCells()){
System.out.println("列族" + Bytes.toString(CellUtil.cloneFamily(cell)));
System.out.println("值:" + Bytes.toString(CellUtil.cloneValue(cell)));
}6.2.9 获取某一行指定“列族:列”的数据
public static void getRowQualifier(String tableName, String rowKey, String family, String
HTable table = new HTable(conf, tableName);
get.addColumn(Bytes.toBytes(family), Bytes.toBytes(qualifier));
for(Cell cell : result.rawCells()){
System.out.println("列族" + Bytes.toString(CellUtil.cloneFamily(cell)));
System.out.println("值:" + Bytes.toString(CellUtil.cloneValue(cell)));
}6.3 MapReduce
通过HBase的相关JavaAPI,我们可以实现伴随HBase操作的MapReduce过程,比如使用MapReduce将数据从本地文件系统导入到HBase的表中,比如我们从HBase中读取一些原始数据后使用MapReduce做数据分析。
6.3.1 官方HBase-MapReduce
1.查看HBase的MapReduce任务的执行
$ bin/hbase mapredcp2.环境变量的导入
(1)执行环境变量的导入(临时生效,在命令行执行下述操作)
$ export HBASE_HOME=/opt/module/hbase-1.3.1
$ export HADOOP_HOME=/opt/module/hadoop-2.7.2
$ export HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`(2)永久生效:在/etc/profile配置
export HBASE_HOME=/opt/module/hbase-1.3.1
export HADOOP_HOME=/opt/module/hadoop-2.7.2
并在hadoop-env.sh中配置:(注意:在for循环之后配)
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/module/hbase/lib/*3.运行官方的MapReduce任务
- 案例一:统计Student表中有多少行数据
$ /opt/module/hadoop-2.7.2/bin/yarn jar lib/hbase-server-1.3.1.jar rowcounter student- 案例二:使用MapReduce将本地数据导入到HBase
1)在本地创建一个tsv格式的文件:fruit.tsv
1001 Apple Red
1003 Pineapple Yellow2)创建HBase表
hbase(main):001:0> create 'fruit','info'3)在HDFS中创建input_fruit文件夹并上传fruit.tsv文件
$ /opt/module/hadoop-2.7.2/bin/hdfs dfs -mkdir /input_fruit/
$ /opt/module/hadoop-2.7.2/bin/hdfs dfs -put fruit.tsv /input_fruit/- 执行MapReduce到HBase的fruit表中
$ /opt/module/hadoop-2.7.2/bin/yarn jar lib/hbase-server-1.3.1.jar importtsv \- Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:color fruit \
hdfs://hadoop102:9000/input_fruit
- 使用scan命令查看导入后的结果
hbase(main):001:0> scan ‘fruit’6.3.2 自定义HBase-MapReduce1
目标:将fruit表中的一部分数据,通过MR迁入到fruit_mr表中。
分步实现:
1.构建ReadFruitMapper类,用于读取fruit表中的数据
package com.atguigu;
import java.io.IOException;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
protected void map(ImmutableBytesWritable key, Result value, Context context)
//将fruit的name和color提取出来,相当于将每一行数据读取出来放入到Put对象中。
//遍历添加column行
//添加/克隆列族:info
//添加/克隆列:name
//将该列cell加入到put对象中
//添加/克隆列:color
//向该列cell加入到put对象中
}
}
context.write(key, put);
}2. 构建WriteFruitMRReducer类,用于将读取到的fruit表中的数据写入到fruit_mr表中
package com.atguigu.hbase_mr;
import java.io.IOException;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.io.NullWritable;
public class WriteFruitMRReducer extends TableReducer<ImmutableBytesWritable, Put, NullWritable> {
protected void reduce(ImmutableBytesWritable key, Iterable<Put> values, Context context)
//读出来的每一行数据写入到fruit_mr表中
context.write(NullWritable.get(), put);
}3.构建Fruit2FruitMRRunner extends Configured implements Tool用于组装运行Job任务
//组装Job
//得到Configuration
//创建Job任务
job.setJarByClass(Fruit2FruitMRRunner.class);
//配置Job
scan.setCacheBlocks(false);
TableMapReduceUtil.initTableMapperJob(
scan, //scan扫描控制器
ImmutableBytesWritable.class,//设置Mapper输出key类型
job//设置给哪个JOB
//设置Reducer
//设置Reduce数量,最少1个
if(!isSuccess){
}
}4.主函数中调用运行该Job任务
public static void main( String[] args ) throws Exception{
int status = ToolRunner.run(conf, new Fruit2FruitMRRunner(), args);
}5.打包运行任务
$ /opt/module/hadoop-2.7.2/bin/yarn jar ~/softwares/jars/hbase-0.0.1-SNAPSHOT.jar
com.z.hbase.mr1.Fruit2FruitMRRunner提示:运行任务前,如果待数据导入的表不存在,则需要提前创建。
提示:maven打包命令:-P local clean package或-P dev clean package install(将第三方jar包一同打包,需要插件:maven-shade-plugin)
6.3.3 自定义HBase-MapReduce2
目标:实现将HDFS中的数据写入到HBase表中。
分步实现:
1.构建ReadFruitFromHDFSMapper于读取HDFS中的文件数据
package com.atguigu;
import java.io.IOException;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.Text;
@Override
//从HDFS中读取的数据
//读取出来的每行数据使用\t进行分割,存于String数组
String rowKey = values[0];
String color = values[2];
//初始化rowKey
Put put = new Put(Bytes.toBytes(rowKey));
//参数分别:列族、列、值
put.add(Bytes.toBytes("info"), Bytes.toBytes("color"), Bytes.toBytes(color));
context.write(rowKeyWritable, put);
}2.构建WriteFruitMRFromTxtReducer类
package com.z.hbase.mr2;
import java.io.IOException;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.io.NullWritable;
public class WriteFruitMRFromTxtReducer extends TableReducer<ImmutableBytesWritable, Put, NullWritable> {
protected void reduce(ImmutableBytesWritable key, Iterable<Put> values, Context context) throws IOException, InterruptedException {
for(Put put: values){
}
}3.创建Txt2FruitRunner组装Job
public int run(String[] args) throws Exception {
Configuration conf = this.getConf();
//创建Job任务
job.setJarByClass(Txt2FruitRunner.class);
FileInputFormat.addInputPath(job, inPath);
//设置Mapper
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
TableMapReduceUtil.initTableReducerJob("fruit_mr", WriteFruitMRFromTxtReducer.class, job);
//设置Reduce数量,最少1个
if(!isSuccess){
}
return isSuccess ? 0 : 1;4.调用执行Job
public static void main(String[] args) throws Exception {
int status = ToolRunner.run(conf, new Txt2FruitRunner(), args);
}5.打包运行
$ /opt/module/hadoop-2.7.2/bin/yarn jar hbase-0.0.1-SNAPSHOT.jar com.atguigu.hbase.mr2.Txt2FruitRunner提示:运行任务前,如果待数据导入的表不存在,则需要提前创建之。
提示:maven打包命令:-P local clean package或-P dev clean package install(将第三方jar包一同打包,需要插件:maven-shade-plugin)
6.4 与Hive的集成
6.4.1 HBase与Hive的对比
1.Hive
(1) 数据仓库
Hive的本质其实就相当于将HDFS中已经存储的文件在Mysql中做了一个双射关系,以方便使用HQL去管理查询。
(2) 用于数据分析、清洗
Hive适用于离线的数据分析和清洗,延迟较高。
(3) 基于HDFS、MapReduce
Hive存储的数据依旧在DataNode上,编写的HQL语句终将是转换为MapReduce代码执行。
2.HBase
(1) 数据库
是一种面向列存储的非关系型数据库。
(2) 用于存储结构化和非结构化的数据
适用于单表非关系型数据的存储,不适合做关联查询,类似JOIN等操作。
(3) 基于HDFS
数据持久化存储的体现形式是Hfile,存放于DataNode中,被ResionServer以region的形式进行管理。
(4) 延迟较低,接入在线业务使用
面对大量的企业数据,HBase可以直线单表大量数据的存储,同时提供了高效的数据访问速度。
6.4.2 HBase与Hive集成使用
尖叫提示:HBase与Hive的集成在最新的两个版本中无法兼容。所以,我们只能含着泪勇敢的重新编译:hive-hbase-handler-1.2.2.jar!!好气!!
环境准备
因为我们后续可能会在操作Hive的同时对HBase也会产生影响,所以Hive需要持有操作HBase的Jar,那么接下来拷贝Hive所依赖的Jar包(或者使用软连接的形式)。
export HBASE_HOME=/opt/module/hbase
ln -s $HBASE_HOME/lib/hbase-server-1.3.1.jar $HIVE_HOME/lib/hbase-server-1.3.1.jar
ln -s $HBASE_HOME/lib/hbase-protocol-1.3.1.jar $HIVE_HOME/lib/hbase-protocol-1.3.1.jar
ln -s $HBASE_HOME/lib/htrace-core-3.1.0-incubating.jar $HIVE_HOME/lib/htrace-core-3.1.0-incubating.jar
ln -s $HBASE_HOME/lib/hbase-hadoop-compat-1.3.1.jar $HIVE_HOME/lib/hbase-hadoop-compat-1.3.1.jar同时在hive-site.xml中修改zookeeper的属性,如下:
<property>
<value>hadoop102,hadoop103,hadoop104</value>
</property>
<name>hive.zookeeper.client.port</name>
<description>The port of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>1.案例一
**目标:**建立Hive表,关联HBase表,插入数据到Hive表的同时能够影响HBase表。
分步实现:
(1) 在Hive中创建表同时关联HBase
CREATE TABLE hive_hbase_emp_table(
ename string,
mgr int,
sal double,
deptno int)
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")提示:完成之后,可以分别进入Hive和HBase查看,都生成了对应的表
(2) 在Hive中创建临时中间表,用于load文件中的数据
提示:不能将数据直接load进Hive所关联HBase的那张表中
CREATE TABLE emp(
ename string,
mgr int,
sal double,
deptno int)(3) 向Hive中间表中load数据
hive> load data local inpath '/home/admin/softwares/data/emp.txt' into table emp;
(4) 通过insert命令将中间表中的数据导入到Hive关联HBase的那张表中
hive> insert into table hive_hbase_emp_table select * from emp;(5) 查看Hive以及关联的HBase表中是否已经成功的同步插入了数据
Hive:
hive> select * from hive_hbase_emp_table;
HBase:
hbase> scan ‘hbase_emp_table’2.案例二
**目标:**在HBase中已经存储了某一张表hbase_emp_table,然后在Hive中创建一个外部表来关联HBase中的hbase_emp_table这张表,使之可以借助Hive来分析HBase这张表中的数据。
**注:**该案例2紧跟案例1的脚步,所以完成此案例前,请先完成案例1。
分步实现:
(1) 在Hive中创建外部表
CREATE EXTERNAL TABLE relevance_hbase_emp(
ename string,
mgr int,
sal double,
deptno int)
'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")(2) 关联后就可以使用Hive函数进行一些分析操作了
hive (default)> select * from relevance_hbase_emp;第7章 HBase优化
7.1 高可用
在HBase中Hmaster负责监控RegionServer的生命周期,均衡RegionServer的负载,如果Hmaster挂掉了,那么整个HBase集群将陷入不健康的状态,并且此时的工作状态并不会维持太久。所以HBase支持对Hmaster的高可用配置。
1.关闭HBase集群(如果没有开启则跳过此步)
[rzf@hadoop102 hbase]$ bin/stop-hbase.sh2.在conf目录下创建backup-masters文件
[rzf@hadoop102 hbase]$ touch conf/backup-masters3.在backup-masters文件中配置高可用HMaster节点
[rzf@hadoop102 hbase]$ echo hadoop103 > conf/backup-masters4.将整个conf目录scp到其他节点
[rzf@hadoop102 hbase]$ scp -r conf/ hadoop103:/opt/module/hbase/
[rzf@hadoop102 hbase]$ scp -r conf/ hadoop104:/opt/module/hbase/5.打开页面测试查看
7.2 预分区
每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维护的rowKey范围,则该数据交给这个region维护。那么依照这个原则,我们可以将数据所要投放的分区提前大致的规划好,以提高HBase性能。
1.手动设定预分区
hbase> create 'staff1','info','partition1',SPLITS => ['1000','2000','3000','4000']2.生成16进制序列预分区
create 'staff2','info','partition2',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}3.按照文件中设置的规则预分区
创建splits.txt文件内容如下:
aaaa
cccc然后执行:
create 'staff3','partition3',SPLITS_FILE => 'splits.txt'4.使用JavaAPI创建预分区
- 自定义算法,产生一系列Hash散列值存储在二维数组中
- 创建HBaseAdmin实例
- 创建HTableDescriptor实例
- 通过HTableDescriptor实例和散列值二维数组创建带有预分区的HBase表
7.3 RowKey设计
7.3.1、设计原则
(1)rowkey长度原则
Rowkey是一个二进制数据流,Rowkey的长度建议设计在10-100个字节,不过建议是越短越好,不要超过16个字节。如果设置过长,会极大影响Hfile的存储效率。
MemStore将缓存部分数据到内存,如果Rowkey字段过长内存的有效利用率降低,系统将无法缓存更多的数据,这会降低检索效率。
(2)rowkey散列原则
如果Rowkey是按时间戳的方式递增,不要将时间放在二进制码的前面,建议将Rowkey的高位作为散列字段,由程序循环生成,低位放时间字段,这样将提高数据均衡分布在每个Regionserver实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息将产生所有新数据都在一个 RegionServer上堆积的热点现象,这样在做数据检索的时候负载将会集中在个别RegionServer,降低查询效率。
(3)rowkey唯一原则
7.3.2、如何设计
一条数据的唯一标识就是rowkey,那么这条数据存储于哪个分区,取决于rowkey处于哪个一个预分区的区间内,设计rowkey的主要目的 ,就是让数据均匀的分布于所有的region中,在一定程度上防止数据倾斜。接下来我们就谈一谈rowkey常用的设计方案。
1.生成随机数、hash、散列值,比如:
原本rowKey为3001的,SHA1后变成:49042c54de64a1e9bf0b33e00245660ef92dc7bd
在做此操作之前,一般我们会选择从数据集中抽取样本,来决定什么样的rowKey来Hash后作为每个分区的临界值。
2.字符串反转
20170524000001转成10000042507102这样也可以在一定程度上散列逐步put进来的数据。
3.字符串拼接
20170524000001_a12e7.4 内存优化
HBase操作过程中需要大量的内存开销,毕竟Table是可以缓存在内存中的,一般会分配整个可用内存的70%给HBase的Java堆。但是不建议分配非常大的堆内存,因为GC过程持续太久会导致RegionServer处于长期不可用状态,一般16~48G内存就可以了,如果因为框架占用内存过高导致系统内存不足,框架一样会被系统服务拖死。
7.5 基础优化
1.开启HDFS追加同步,可以优秀的配合HBase的数据同步和持久化。默认值为true。
hdfs-site.xml、hbase-site.xml
属性:dfs.support.append2.**HBase一般都会同一时间操作大量的文件,根据集群的数量和规模以及数据动作,设置为4096或者更高。默认值:4096。**优化DataNode允许的最大文件打开数
hdfs-site.xml
属性:dfs.datanode.max.transfer.threads3.优化延迟高的数据操作的等待时间
如果对于某一次数据操作来讲,延迟非常高,socket需要等待更长的时间,建议把该值设置为更大的值(默认60000毫秒),以确保socket不会被timeout掉。
hdfs-site.xml
属性:dfs.image.transfer.timeout4.优化数据的写入效率
开启这两个数据可以大大提高文件的写入效率,减少写入时间。第一个属性值修改为true,第二个属性值修改为:org.apache.bigdata.io.compress.GzipCodec或者其他压缩方式。
mapred-site.xml
属性:
mapreduce.map.output.compress.codec
mapreduce.map.output.compress5.设置RPC监听数量
hbase-site.xml
属性:hbase.regionserver.handler.count6.优化HStore文件大小
默认值10GB,如果需要运行HBase的MR任务,可以减小此值,因为一个region对应一个map任务,如果单个region过大,会导致map任务执行时间过长。该值的意思就是,如果HFile的大小达到这个数值,则这个region会被切分为两个Hfile。
hbase-site.xml
属性:hbase.hregion.max.filesize7.优化hbase客户端缓存
用于指定HBase客户端缓存,增大该值可以减少RPC调用次数,但是会消耗更多内存,反之则反之。一般我们需要设定一定的缓存大小,以达到减少RPC次数的目的。
hbase-site.xml
属性:hbase.client.write.buffer8.指定scan.next扫描HBase所获取的行数
用于指定scan.next方法获取的默认行数,值越大,消耗内存越大。
hbase-site.xml
属性:hbase.client.scanner.caching9.flush、compact、split机制
当MemStore达到阈值,将Memstore中的数据Flush进Storefile;compact机制则是把flush出来的小文件合并成大的Storefile文件。split则是当Region达到阈值,会把过大的Region一分为二。
**涉及属性:**
即:128M就是Memstore的默认阈值
hbase.hregion.memstore.flush.size:134217728即:这个参数的作用是当单个HRegion内所有的Memstore大小总和超过指定值时,flush该HRegion的所有memstore。RegionServer的flush是通过将请求添加一个队列,模拟生产消费模型来异步处理的。那这里就有一个问题,当队列来不及消费,产生大量积压请求时,可能会导致内存陡增,最坏的情况是触发OOM。
hbase.regionserver.global.memstore.upperLimit:0.4即:当MemStore使用内存总量达到hbase.regionserver.global.memstore.upperLimit指定值时,将会有多个MemStores flush到文件中,MemStore flush 顺序是按照大小降序执行的,直到刷新到MemStore使用内存略小于lowerLimit
7.6、Phoenix二级索引
在Hbase中,按字典顺序排序的rowkey是一级索引。不通过rowkey来查询数据时需要过滤器来扫描整张表。通过二级索引,这样的场景也可以轻松定位到数据。
二级索引的原理通常是在写入时针对某个字段和rowkey进行绑定,查询时先根据这个字段查询到rowkey,然后根据rowkey查询数据,二级索引也可以理解为查询数据时多次使用索引的情况。
7.7、索引
7.7.1、全局索引
全局索引适用于多读少写的场景,在写操作上会给性能带来极大的开销,因为所有的更新和写操作(DELETE,UPSERT VALUES和UPSERT SELECT)都会引起索引的更新,在读数据时,Phoenix将通过索引表来达到快速查询的目的。
7.7.2、本地索引
本地索引适用于写多读少的场景,当使用本地索引的时候即使查询的所有字段都不在索引字段中时也会用到索引进行查询,Phoneix在查询时会自动选择是否使用本地索引。
7.7.3、覆盖索引
只需要通过索引就能返回所要查询的数据,所以索引的列必须包含所需查询的列。
7.7.4、函数索引
索引不局限于列,可以合适任意的表达式来创建索引,当在查询时用到了这些表达式时就直接返回表达式结果
7.7.5、索引优化
(1)根据主表的更新来确定更新索引表的线程数
index.builder.threads.max:(默认值:10)(2)builder线程池中线程的存活时间
index.builder.threads.keepalivetime:(默认值:60)(3)更新索引表时所能使用的线程数(即同时能更新多少张索引表),其数量最好与索引表的数量一致
index.write.threads.max:(默认值:10)(4) 更新索引表的线程所能存活的时间
index.write.threads.keepalivetime(默认值:60)(5) 每张索引表所能使用的线程(即在一张索引表中同时可以有多少线程对其进行写入更新),增加此值可以提高更新索引的并发量
hbase.htable.threads.max(默认值:2147483647)(6) 索引表上更新索引的线程的存活时间
hbase.htable.threads.keepalivetime(默认值:60)(7) 允许缓存的索引表的数量 增加此值,可以在更新索引表时不用每次都去重复的创建htable,由于是缓存在内存中,所以其值越大,其需要的内存越多
index.tablefactoy.cache.size(默认值:10)第8章 HBase实战之微博
8.1 需求分析
微博内容的浏览,数据库表设计
用户社交体现:关注用户,取关用户
拉取关注的人的微博内容
8.2 代码实现
8.2.1 代码设计总览:
创建命名空间以及表名的定义
创建微博内容表
创建用户关系表
创建用户微博内容接收邮件表
发布微博内容
添加关注用户
移除(取关)用户
获取关注的人的微博内容
测试
8.2.2 创建命名空间以及表名的定义
//获取配置conf
private Configuration conf = HBaseConfiguration.create();
//微博内容表的表名
private static final byte[] TABLE_CONTENT = Bytes.toBytes("weibo:content");
//用户关系表的表名
private static final byte[] TABLE_RELATIONS = Bytes.toBytes("weibo:relations");
//微博收件箱表的表名
private static final byte[] TABLE_RECEIVE_CONTENT_EMAIL = Bytes.toBytes("weibo:receive_content_email");
public void initNamespace() {
HBaseAdmin admin = null;
try {
admin = new HBaseAdmin(conf);
//命名空间类似于关系型数据库中的schema,可以想象成文件夹
NamespaceDescriptor weibo = NamespaceDescriptor
.create("weibo")
.addConfiguration("creator", "Jinji")
.addConfiguration("create_time", System.currentTimeMillis() + "")
.build();
admin.createNamespace(weibo);
} catch (MasterNotRunningException e) {
e.printStackTrace();
} catch (ZooKeeperConnectionException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (null != admin) {
try {
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}8.2.3 创建微博内容表
表结构:
| 方法名 | creatTableeContent |
|---|---|
| Table Name | weibo:content |
| RowKey | 用户ID_时间戳 |
| ColumnFamily | info |
| ColumnLabel | 标题,内容,图片 |
| Version | 1个版本 |
代码
/**
* 创建微博内容表
* Table Name:weibo:content
* RowKey:用户ID_时间戳
* ColumnFamily:info
* ColumnLabel:标题 内容 图片URL
* Version:1个版本
*/
public void createTableContent() {
HBaseAdmin admin = null;
try {
admin = new HBaseAdmin(conf);
//创建表表述
HTableDescriptor content = new HTableDescriptor(TableName.valueOf(TABLE_CONTENT));
//创建列族描述
HColumnDescriptor info = new HColumnDescriptor(Bytes.toBytes("info"));
//设置块缓存
info.setBlockCacheEnabled(true);
//设置块缓存大小
info.setBlocksize(2097152);
//设置压缩方式
// info.setCompressionType(Algorithm.SNAPPY);
//设置版本确界
info.setMaxVersions(1);
info.setMinVersions(1);
content.addFamily(info);
admin.createTable(content);
} catch (MasterNotRunningException e) {
e.printStackTrace();
} catch (ZooKeeperConnectionException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (null != admin) {
try {
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}8.2.4 创建用户关系表
表结构:
| 方法名 | createTableRelations |
|---|---|
| Table Name | weibo:relations |
| RowKey | 用户ID |
| ColumnFamily | attends、fans |
| ColumnLabel | 关注用户ID,粉丝用户ID |
| ColumnValue | 用户ID |
| Version | 1个版本 |
代码:
/**
* 用户关系表
* <p>
* Table Name:weibo:relations
* <p>
* RowKey:用户ID
* <p>
* ColumnFamily:attends,fans
* <p>
* ColumnLabel:关注用户ID,粉丝用户ID
* <p>
* ColumnValue:用户ID
* <p>
* Version:1个版本
*/
public void createTableRelations() {
HBaseAdmin admin = null;
try {
admin = new HBaseAdmin(conf);
HTableDescriptor relations = new HTableDescriptor(TableName.valueOf(TABLE_RELATIONS));
//关注的人的列族
HColumnDescriptor attends = new HColumnDescriptor(Bytes.toBytes("attends"));
//设置块缓存
attends.setBlockCacheEnabled(true);
//设置块缓存大小
attends.setBlocksize(2097152);
//设置压缩方式
// info.setCompressionType(Algorithm.SNAPPY);
//设置版本确界
attends.setMaxVersions(1);
attends.setMinVersions(1);
//粉丝列族
HColumnDescriptor fans = new HColumnDescriptor(Bytes.toBytes("fans"));
fans.setBlockCacheEnabled(true);
fans.setBlocksize(2097152);
fans.setMaxVersions(1);
fans.setMinVersions(1);
relations.addFamily(attends);
relations.addFamily(fans);
admin.createTable(relations);
} catch (MasterNotRunningException e) {
e.printStackTrace();
} catch (ZooKeeperConnectionException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (null != admin) {
try {
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}8.2.5 创建微博收件箱表
表结构:
| 方法名 | createTableReceiveContentEmails |
|---|---|
| Table Name | weibo:receive_content_email |
| RowKey | 用户ID |
| ColumnFamily | info |
| ColumnLabel | 用户ID |
| ColumnValue | 取微博内容的RowKey |
| Version | 1000 |
代码:
/**
* 创建微博收件箱表
* Table Name: weibo:receive_content_email
* RowKey:用户ID
* ColumnFamily:info
* ColumnLabel:用户ID-发布微博的人的用户ID
* ColumnValue:关注的人的微博的RowKey
* Version:1000
*/
public void createTableReceiveContentEmail(){
HBaseAdmin admin = null;
try {
admin = new HBaseAdmin(conf);
HTableDescriptor receive_content_email = new HTableDescriptor(TableName.valueOf(TABLE_RECEIVE_CONTENT_EMAIL));
HColumnDescriptor info = new HColumnDescriptor(Bytes.toBytes("info"));
info.setBlockCacheEnabled(true);
info.setBlocksize(2097152);
info.setMaxVersions(1000);
info.setMinVersions(1000);
receive_content_email.addFamily(info);;
admin.createTable(receive_content_email);
} catch (MasterNotRunningException e) {
e.printStackTrace();
} catch (ZooKeeperConnectionException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
if(null != admin){
try {
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}8.2.6 发布微博内容
a、微博内容表中添加1条数据
b、微博收件箱表对所有粉丝用户添加数据
**代码:Message.java**
package com.atguigu.weibo;
public class Message {
private String uid;
private String timestamp;
private String content;
public String getUid() {
return uid;
}
public void setUid(String uid) {
this.uid = uid;
}
public String getTimestamp() {
return timestamp;
}
public void setTimestamp(String timestamp) {
this.timestamp = timestamp;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
@Override
public String toString() {
return "Message [uid=" + uid + ", timestamp=" + timestamp + ", content=" + content + "]";
}
}
**代码:public void publishContent(String uid, String content)**
/**
* 发布微博
* a、微博内容表中数据+1
* b、向微博收件箱表中加入微博的Rowkey
*/
public void publishContent(String uid, String content){
HConnection connection = null;
try {
connection = HConnectionManager.createConnection(conf);
//a、微博内容表中添加1条数据,首先获取微博内容表描述
HTableInterface contentTBL = connection.getTable(TableName.valueOf(TABLE_CONTENT));
//组装Rowkey
long timestamp = System.currentTimeMillis();
String rowKey = uid + "_" + timestamp;
Put put = new Put(Bytes.toBytes(rowKey));
put.add(Bytes.toBytes("info"), Bytes.toBytes("content"), timestamp, Bytes.toBytes(content));
contentTBL.put(put);
//b、向微博收件箱表中加入发布的Rowkey
//b.1、查询用户关系表,得到当前用户有哪些粉丝
HTableInterface relationsTBL = connection.getTable(TableName.valueOf(TABLE_RELATIONS));
//b.2、取出目标数据
Get get = new Get(Bytes.toBytes(uid));
get.addFamily(Bytes.toBytes("fans"));
Result result = relationsTBL.get(get);
List<byte[]> fans = new ArrayList<byte[]>();
//遍历取出当前发布微博的用户的所有粉丝数据
for(Cell cell : result.rawCells()){
fans.add(CellUtil.cloneQualifier(cell));
}
//如果该用户没有粉丝,则直接return
if(fans.size() <= 0) return;
//开始操作收件箱表
HTableInterface recTBL = connection.getTable(TableName.valueOf(TABLE_RECEIVE_CONTENT_EMAIL));
List<Put> puts = new ArrayList<Put>();
for(byte[] fan : fans){
Put fanPut = new Put(fan);
fanPut.add(Bytes.toBytes("info"), Bytes.toBytes(uid), timestamp, Bytes.toBytes(rowKey));
puts.add(fanPut);
}
recTBL.put(puts);
} catch (IOException e) {
e.printStackTrace();
}finally{
if(null != connection){
try {
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}8.2.7 添加关注用户
a、在微博用户关系表中,对当前主动操作的用户添加新关注的好友
b、在微博用户关系表中,对被关注的用户添加新的粉丝
c、微博收件箱表中添加所关注的用户发布的微博
**代码实现:public void addAttends(String uid, String... attends)**
/**
* 关注用户逻辑
* a、在微博用户关系表中,对当前主动操作的用户添加新的关注的好友
* b、在微博用户关系表中,对被关注的用户添加粉丝(当前操作的用户)
* c、当前操作用户的微博收件箱添加所关注的用户发布的微博rowkey
*/
public void addAttends(String uid, String... attends){
//参数过滤
if(attends == null || attends.length <= 0 || uid == null || uid.length() <= 0){
return;
}
HConnection connection = null;
try {
connection = HConnectionManager.createConnection(conf);
//用户关系表操作对象(连接到用户关系表)
HTableInterface relationsTBL = connection.getTable(TableName.valueOf(TABLE_RELATIONS));
List<Put> puts = new ArrayList<Put>();
//a、在微博用户关系表中,添加新关注的好友
Put attendPut = new Put(Bytes.toBytes(uid));
for(String attend : attends){
//为当前用户添加关注的人
attendPut.add(Bytes.toBytes("attends"), Bytes.toBytes(attend), Bytes.toBytes(attend));
//b、为被关注的人,添加粉丝
Put fansPut = new Put(Bytes.toBytes(attend));
fansPut.add(Bytes.toBytes("fans"), Bytes.toBytes(uid), Bytes.toBytes(uid));
//将所有关注的人一个一个的添加到puts(List)集合中
puts.add(fansPut);
}
puts.add(attendPut);
relationsTBL.put(puts);
//c.1、微博收件箱添加关注的用户发布的微博内容(content)的rowkey
HTableInterface contentTBL = connection.getTable(TableName.valueOf(TABLE_CONTENT));
Scan scan = new Scan();
//用于存放取出来的关注的人所发布的微博的rowkey
List<byte[]> rowkeys = new ArrayList<byte[]>();
for(String attend : attends){
//过滤扫描rowkey,即:前置位匹配被关注的人的uid_
RowFilter filter = new RowFilter(CompareFilter.CompareOp.EQUAL, new SubstringComparator(attend + "_"));
//为扫描对象指定过滤规则
scan.setFilter(filter);
//通过扫描对象得到scanner
ResultScanner result = contentTBL.getScanner(scan);
//迭代器遍历扫描出来的结果集
Iterator<Result> iterator = result.iterator();
while(iterator.hasNext()){
//取出每一个符合扫描结果的那一行数据
Result r = iterator.next();
for(Cell cell : r.rawCells()){
//将得到的rowkey放置于集合容器中
rowkeys.add(CellUtil.cloneRow(cell));
}
}
}
//c.2、将取出的微博rowkey放置于当前操作用户的收件箱中
if(rowkeys.size() <= 0) return;
//得到微博收件箱表的操作对象
HTableInterface recTBL = connection.getTable(TableName.valueOf(TABLE_RECEIVE_CONTENT_EMAIL));
//用于存放多个关注的用户的发布的多条微博rowkey信息
List<Put> recPuts = new ArrayList<Put>();
for(byte[] rk : rowkeys){
Put put = new Put(Bytes.toBytes(uid));
//uid_timestamp
String rowKey = Bytes.toString(rk);
//借取uid
String attendUID = rowKey.substring(0, rowKey.indexOf("_"));
long timestamp = Long.parseLong(rowKey.substring(rowKey.indexOf("_") + 1));
//将微博rowkey添加到指定单元格中
put.add(Bytes.toBytes("info"), Bytes.toBytes(attendUID), timestamp, rk);
recPuts.add(put);
}
recTBL.put(recPuts);
} catch (IOException e) {
e.printStackTrace();
}finally{
if(null != connection){
try {
connection.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}8.2.8 移除(取关)用户
a、在微博用户关系表中,对当前主动操作的用户移除取关的好友(attends)
b、在微博用户关系表中,对被取关的用户移除粉丝
c、微博收件箱中删除取关的用户发布的微博
**代码:public void removeAttends(String uid, String... attends)**
/**
* 取消关注(remove)
* a、在微博用户关系表中,对当前主动操作的用户删除对应取关的好友
* b、在微博用户关系表中,对被取消关注的人删除粉丝(当前操作人)
* c、从收件箱中,删除取关的人的微博的rowkey
*/
public void removeAttends(String uid, String... attends){
//过滤数据
if(uid == null || uid.length() <= 0 || attends == null || attends.length <= 0) return;
HConnection connection = null;
try {
connection = HConnectionManager.createConnection(conf);
//a、在微博用户关系表中,删除已关注的好友
HTableInterface relationsTBL = connection.getTable(TableName.valueOf(TABLE_RELATIONS));
//待删除的用户关系表中的所有数据
List<Delete> deletes = new ArrayList<Delete>();
//当前取关操作者的uid对应的Delete对象
Delete attendDelete = new Delete(Bytes.toBytes(uid));
//遍历取关,同时每次取关都要将被取关的人的粉丝-1
for(String attend : attends){
attendDelete.deleteColumn(Bytes.toBytes("attends"), Bytes.toBytes(attend));
//b
Delete fansDelete = new Delete(Bytes.toBytes(attend));
fansDelete.deleteColumn(Bytes.toBytes("fans"), Bytes.toBytes(uid));
deletes.add(fansDelete);
}
deletes.add(attendDelete);
relationsTBL.delete(deletes);
//c、删除取关的人的微博rowkey 从 收件箱表中
HTableInterface recTBL = connection.getTable(TableName.valueOf(TABLE_RECEIVE_CONTENT_EMAIL));
Delete recDelete = new Delete(Bytes.toBytes(uid));
for(String attend : attends){
recDelete.deleteColumn(Bytes.toBytes("info"), Bytes.toBytes(attend));
}
recTBL.delete(recDelete);
} catch (IOException e) {
e.printStackTrace();
}
}8.2.9 获取关注的人的微博内容
a、从微博收件箱中获取所关注的用户的微博RowKey
b、根据获取的RowKey,得到微博内容
**代码实现:public List<Message> getAttendsContent(String uid)**
/**
* 获取微博实际内容
* a、从微博收件箱中获取所有关注的人的发布的微博的rowkey
* b、根据得到的rowkey去微博内容表中得到数据
* c、将得到的数据封装到Message对象中
*/
public List<Message> getAttendsContent(String uid){
HConnection connection = null;
try {
connection = HConnectionManager.createConnection(conf);
HTableInterface recTBL = connection.getTable(TableName.valueOf(TABLE_RECEIVE_CONTENT_EMAIL));
//a、从收件箱中取得微博rowKey
Get get = new Get(Bytes.toBytes(uid));
//设置最大版本号
get.setMaxVersions(5);
List<byte[]> rowkeys = new ArrayList<byte[]>();
Result result = recTBL.get(get);
for(Cell cell : result.rawCells()){
rowkeys.add(CellUtil.cloneValue(cell));
}
//b、根据取出的所有rowkey去微博内容表中检索数据
HTableInterface contentTBL = connection.getTable(TableName.valueOf(TABLE_CONTENT));
List<Get> gets = new ArrayList<Get>();
//根据rowkey取出对应微博的具体内容
for(byte[] rk : rowkeys){
Get g = new Get(rk);
gets.add(g);
}
//得到所有的微博内容的result对象
Result[] results = contentTBL.get(gets);
List<Message> messages = new ArrayList<Message>();
for(Result res : results){
for(Cell cell : res.rawCells()){
Message message = new Message();
String rowKey = Bytes.toString(CellUtil.cloneRow(cell));
String userid = rowKey.substring(0, rowKey.indexOf("_"));
String timestamp = rowKey.substring(rowKey.indexOf("_") + 1);
String content = Bytes.toString(CellUtil.cloneValue(cell));
message.setContent(content);
message.setTimestamp(timestamp);
message.setUid(userid);
messages.add(message);
}
}
return messages;
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return null;
}8.2.10 测试
- - 测试发布微博内容
public void testPublishContent(WeiBo wb)
- - 测试添加关注
public void testAddAttend(WeiBo wb)
- - 测试取消关注
public void testRemoveAttend(WeiBo wb)
- - 测试展示内容
public void testShowMessage(WeiBo wb)
代码:
/**
* 发布微博内容
* 添加关注
* 取消关注
* 展示内容
*/
public void testPublishContent(WeiBo wb){
wb.publishContent("0001", "今天买了一包空气,送了点薯片,非常开心!!");
wb.publishContent("0001", "今天天气不错。");
}
public void testAddAttend(WeiBo wb){
wb.publishContent("0008", "准备下课!");
wb.publishContent("0009", "准备关机!");
wb.addAttends("0001", "0008", "0009");
}
public void testRemoveAttend(WeiBo wb){
wb.removeAttends("0001", "0008");
}
public void testShowMessage(WeiBo wb){
List<Message> messages = wb.getAttendsContent("0001");
for(Message message : messages){
System.out.println(message);
}
}
public static void main(String[] args) {
WeiBo weibo = new WeiBo();
weibo.initTable();
weibo.testPublishContent(weibo);
weibo.testAddAttend(weibo);
weibo.testShowMessage(weibo);
weibo.testRemoveAttend(weibo);
weibo.testShowMessage(weibo);
}第9章 扩展
9.1 HBase在商业项目中的能力
每天:
消息量:发送和接收的消息数超过60亿
将近1000亿条数据的读写
高峰期每秒150万左右操作
整体读取数据占有约55%,写入占有45%
超过2PB的数据,涉及冗余共6PB数据
数据每月大概增长300千兆字节。
9.2 布隆过滤器
在日常生活中,包括在设计计算机软件时,我们经常要判断一个元素是否在一个集合中。比如在字处理软件中,需要检查一个英语单词是否拼写正确(也就是要判断它是否在已知的字典中);在 FBI,一个嫌疑人的名字是否已经在嫌疑名单上;在网络爬虫里,一个网址是否被访问过等等。最直接的方法就是将集合中全部的元素存在计算机中,遇到一个新元素时,将它和集合中的元素直接比较即可。一般来讲,计算机中的集合是用哈希表(hash table)来存储的。它的好处是快速准确,缺点是费存储空间。当集合比较小时,这个问题不显著,但是当集合巨大时,哈希表存储效率低的问题就显现出来了。比如说,一个像 Yahoo,Hotmail 和 Gmai 那样的公众电子邮件(email)提供商,总是需要过滤来自发送垃圾邮件的人(spamer)的垃圾邮件。一个办法就是记录下那些发垃圾邮件的 email 地址。由于那些发送者不停地在注册新的地址,全世界少说也有几十亿个发垃圾邮件的地址,将他们都存起来则需要大量的网络服务器。如果用哈希表,每存储一亿个 email 地址, 就需要 1.6GB 的内存(用哈希表实现的具体办法是将每一个 email 地址对应成一个八字节的信息指纹googlechinablog.com/2006/08/blog-post.html,然后将这些信息指纹存入哈希表,由于哈希表的存储效率一般只有 50%,因此一个 email 地址需要占用十六个字节。一亿个地址大约要 1.6GB, 即十六亿字节的内存)。因此存贮几十亿个邮件地址可能需要上百 GB 的内存。除非是超级计算机,一般服务器是无法存储的。
布隆过滤器只需要哈希表 1/8 到 1/4 的大小就能解决同样的问题。
Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
下面我们具体来看Bloom Filter是如何用位数组表示集合的。初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0,如图所示.

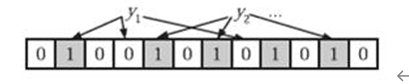
为了表达S={x1, x2,…,xn}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,m}的范围中。对任意一个元素x,第i个哈希函数映射的位置hi(x)就会被置为1(1≤i≤k)。注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。k=3,且有两个哈希函数选中同一个位置(从左边数第五位)。
在判断y是否属于这个集合时,我们对y应用k次哈希函数,如果所有hi(y)的位置都是1(1≤i≤k),那么我们就认为y是集合中的元素,否则就认为y不是集合中的元素。如图y1就不是集合中的元素。y2或者属于这个集合,或者刚好是一个false positive。
- 为了add一个元素,用k个hash function将它hash得到bloom filter中k个bit位,将这k个bit位置1。
- 为了query一个元素,即判断它是否在集合中,用k个hash function将它hash得到k个bit位。若这k bits全为1,则此元素在集合中;若其中任一位不为1,则此元素比不在集合中(因为如果在,则在add时已经把对应的k个bits位置为1)。
- 不允许remove元素,因为那样的话会把相应的k个bits位置为0,而其中很有可能有其他元素对应的位。因此remove会引入false negative,这是绝对不被允许的。
布隆过滤器决不会漏掉任何一个在黑名单中的可疑地址。但是,它有一条不足之处,也就是它有极小的可能将一个不在黑名单中的电子邮件地址判定为在黑名单中,因为有可能某个好的邮件地址正巧对应一个八个都被设置成一的二进制位。好在这种可能性很小,我们把它称为误识概率。
布隆过滤器的好处在于快速,省空间,但是有一定的误识别率,常见的补救办法是在建立一个小的白名单,存储那些可能个别误判的邮件地址。
布隆过滤器具体算法高级内容,如错误率估计,最优哈希函数个数计算,位数组大小计算,请参见http://blog.csdn.net/jiaomeng/article/details/1495500。
9.2 HBase2.0新特性
2017年8月22日凌晨2点左右,HBase发布了2.0.0 alpha-2,相比于上一个版本,修复了500个补丁,我们来了解一下2.0版本的HBase新特性。
最新文档:
http://hbase.apache.org/book.html#ttl
官方发布主页:
举例:
1) region进行了多份冗余
主region负责读写,从region维护在其他HregionServer中,负责读以及同步主region中的信息,如果同步不及时,是有可能出现client在从region中读到了脏数据(主region还没来得及把memstore中的变动的内容flush)。
2) 更多变动
mapreduce.map.output.compress
mapreduce.map.output.compress.codec
mapreduce.map.output.compress
mapreduce.map.output.compress.codec