
六、DDD建模
六、DDD建模
DDD领域建模理解
导读
在 DDD 领域建模和系统建设过程中,有很多的参与者,包括领域专家、产品经理、项目经理、架构师、开发经理和测试经理等。对同样的领域知识,不同的参与角色可能会有不同的理解,那大家交流起来就会有障碍,怎么办呢?
因此,在 DDD 中就出现了“通用语言”和“限界上下文”这两个重要的概念。
这两者相辅相成,通用语言定义上下文含义,限界上下文则定义领域边界,以确保每个上下文含义在它特定的边界内都具有唯一的含义,领域模型则存在于这个边界之内。
所以为了更好地理解限界上下文,我们先从通用语言讲起。
什么是通用语言
在事件风暴过程中,通过团队交流达成共识的,能够简单、清晰、准确描述业务涵义和规则的语言就是通用语言。也就是说,通用语言是团队统一的语言,不管你在团队中承担什么角色,在同一个领域的软件生命周期里都使用统一的语言进行交流。
那么,通用语言的价值也就很明了了,它可以解决交流障碍这个问题,使领域专家和开发人员能够协同合作,从而确保业务需求的正确表达。
通用语言包含术语和用例场景,并且能够直接反映在代码中。
通用语言中的名词可以给领域对象命名,如商品、订单等,对应实体对象;而动词则表示一个动作或事件,如商品已下单、订单已付款等,对应领域事件或者命令。
通用语言贯穿 DDD 的整个设计过程。作为项目团队沟通和协商形成的统一语言,基于它,你就能够开发出可读性更好的代码,将业务需求准确转化为代码设计。
什么是界限上下文
我们知道语言都有它的语义环境,同样,通用语言也有它的上下文环境。为了避免同样的概念或语义在不同的上下文环境中产生歧义,DDD 在战略设计上提出了“限界上下文”这个概念,用来确定语义所在的领域边界。
我们可以将限界上下文拆解为两个词:限界和上下文。限界就是领域的边界,而上下文则是语义环境。通过领域的限界上下文,我们就可以在统一的领域边界内用统一的语言进行交流。
综合一下,我认为限界上下文的定义就是:用来封装通用语言和领域对象,提供上下文环境,保证在领域之内的一些术语、业务相关对象等(通用语言)有一个确切的含义,没有二义性。这个边界定义了模型的适用范围,使团队所有成员能够明确地知道什么应该在模型中实现,什么不应该在模型中实现。
举个例子帮助你来理解什么限界上下文:
正如电商领域的商品一样,商品在不同的阶段有不同的术语,在销售阶段是商品,而在运输阶段则变成了货物。同样的一个东西,由于业务领域的不同,赋予了这些术语不同的涵义和职责边界,这个边界就可能会成为未来微服务设计的边界。看到这,我想你应该非常清楚了,领域边界就是通过限界上下文来定义的。
上下文和微服务的关系
在DDD战略设计阶段识别出来的“限界上下文”,会作为战术设计阶段微服务设计和拆分的主要依据,理论上“限界上下文”的边界是就微服务的物理部署边界。
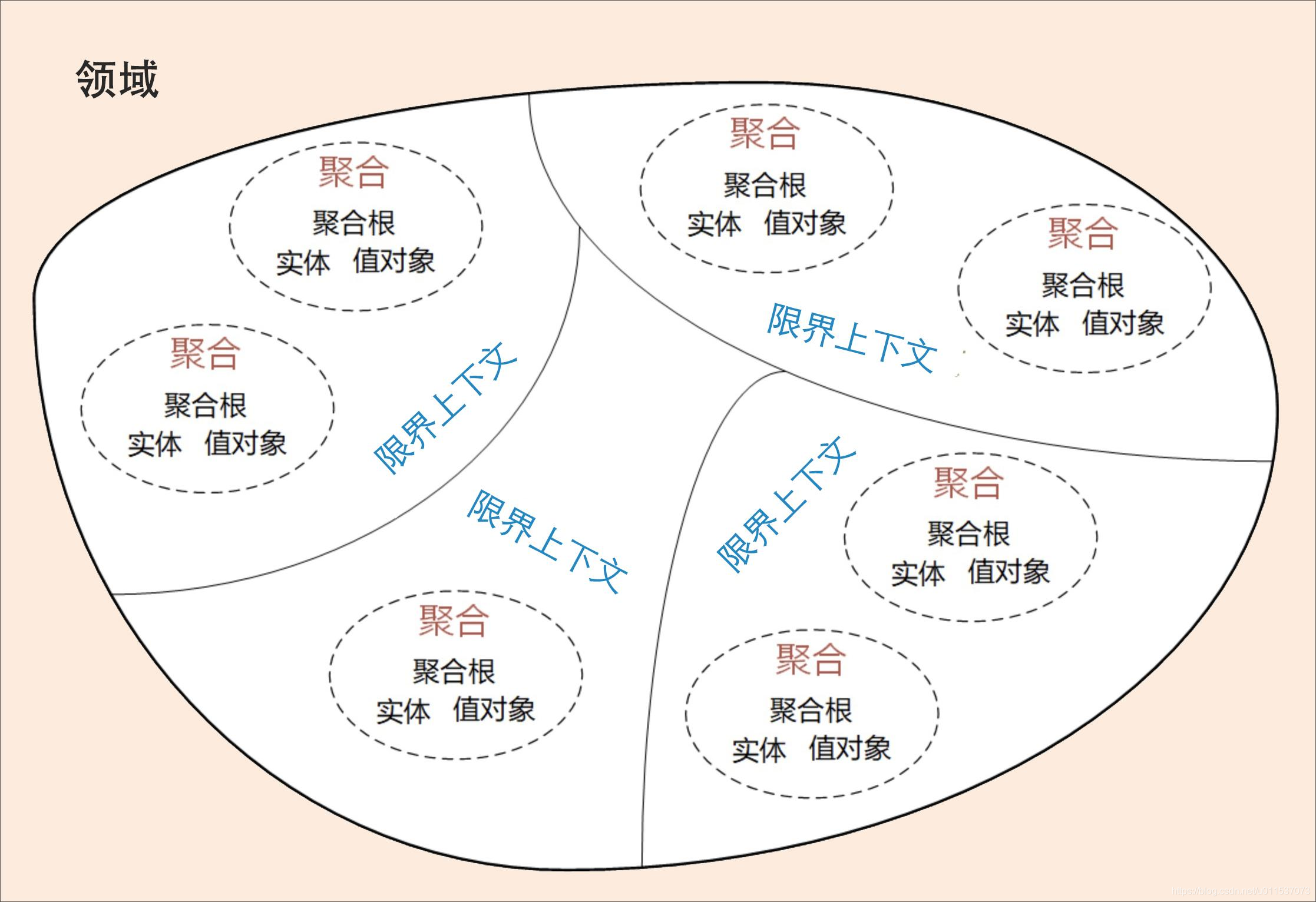
下面的图说明了“限界上下文”和“聚合”之间的关系,一个“限界上下文”可以包含一个或多个“聚合”。
下面使用保险模型描述界限上下文和微服务的关系
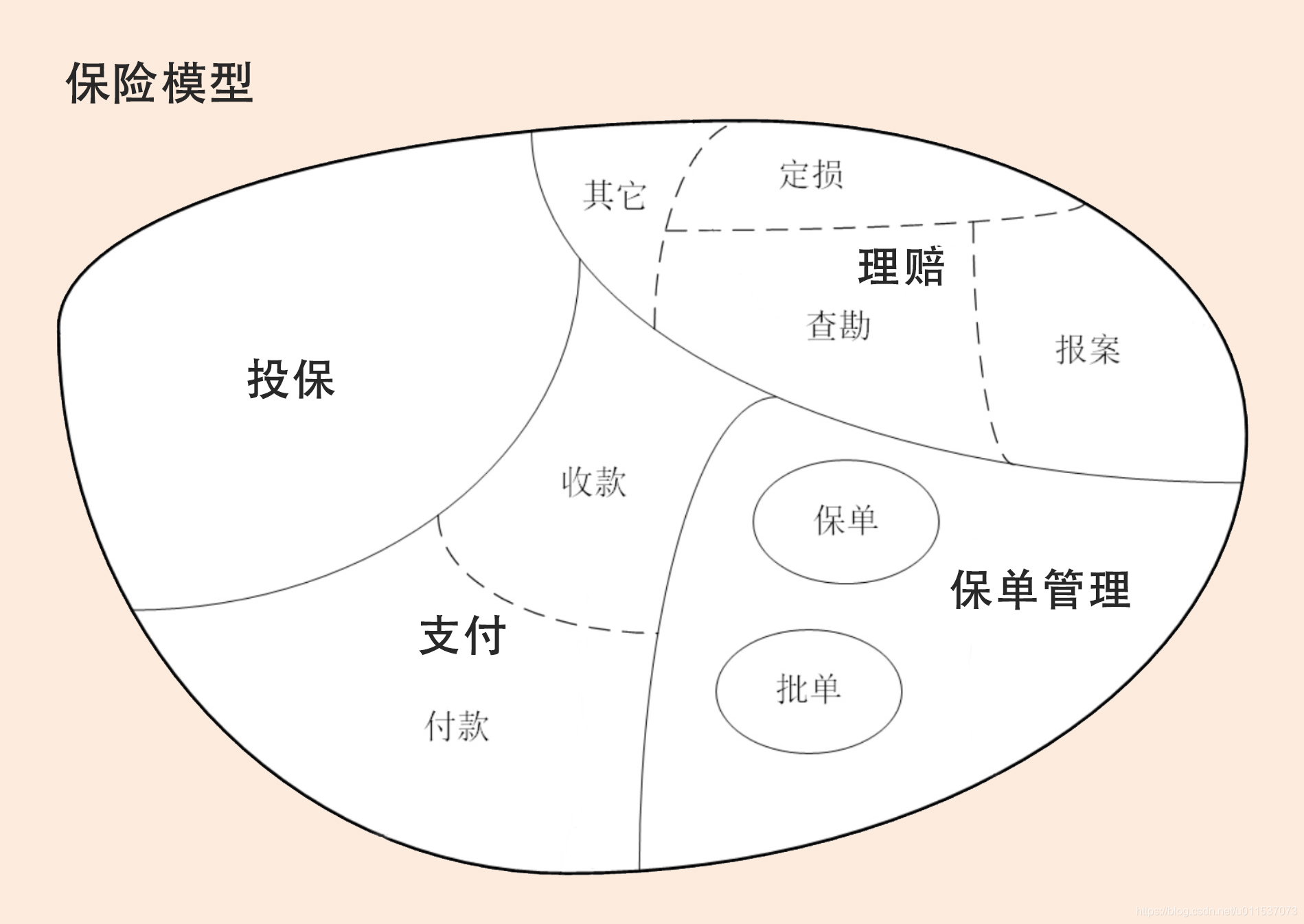
首先,领域可以拆分为多个子领域。一个领域相当于一个问题域,领域拆分为子域的过程就是大问题拆分为小问题的过程。在这个图里面保险领域被拆分为:投保、支付、保单管理和理赔四个子域。
子域还可根据需要进一步拆分为子子域,比如,支付子域可继续拆分为收款和付款子子域。拆到一定程度后,有些子子域的领域边界就可能变成限界上下文的边界了。
子域可能会包含多个限界上下文,如理赔子域就包括报案、查勘和定损等多个限界上下文(限界上下文与理赔的子子域领域边界重合)。也有可能子域本身的边界就是限界上下文边界,如投保子域。
每个领域模型都有它对应的限界上下文,团队在限界上下文内用通用语言交流。领域内所有限界上下文的领域模型构成整个领域的领域模型。
理论上限界上下文就是微服务的边界。我们将限界上下文内的领域模型映射到微服务,就完成了从问题域到软件的解决方案。
可以说,限界上下文是微服务设计和拆分的主要依据。在领域模型中,如果不考虑技术异构、团队沟通等其它外部因素,一个限界上下文理论上就可以设计为一个微服务。
不过,这里还是要提示一下:除了理论,微服务的拆分还是有很多限制因素的,例如:技术异构,高性能要求,特定服务版本的高频发布等,所以在微服务设计中,要根据实际的业务场景进行合理设计并且不宜过度拆分。
本币系统DDD领域设计
领域理解为一个问题的集合,比如要开发本币交易系统,客户之间如何交易,订单如何产生,行情数据如何计算等所有与业务相关的内容都可以归结为领域,DDD就是说你得先把领域中涉及到的数据、流程、商业规则等都弄明白了,然后以面向对象的观点为其建立一个模型(领域模型),再选用合适的软件技术去实现这个模型”。
领域中存在问题空间和解决方案空间。问题空间是领域的一部分,对问题空间的评估应该同时考虑已有子域和额外所需的子域,因此,问题空间是核心域和其他子域的组合。解决方案空间包括一个或者多个限界上下文,即一组特定的软件模型。这是因为限界上下文本身就是一个特定的解决方案【一个微服务】。
新本比系统可以理解为一个问题域;
在本币系统大的域内,在可以将本币系统分为多个小的子域,比如NDW,ODM,QDM,TBS等不同的子域,这些子域可以分为【核心域,支撑域,通用域】。
QDM ODM NDM TBS等子域是核心交易,因此应该归类为核心域。
DDD中名词理解
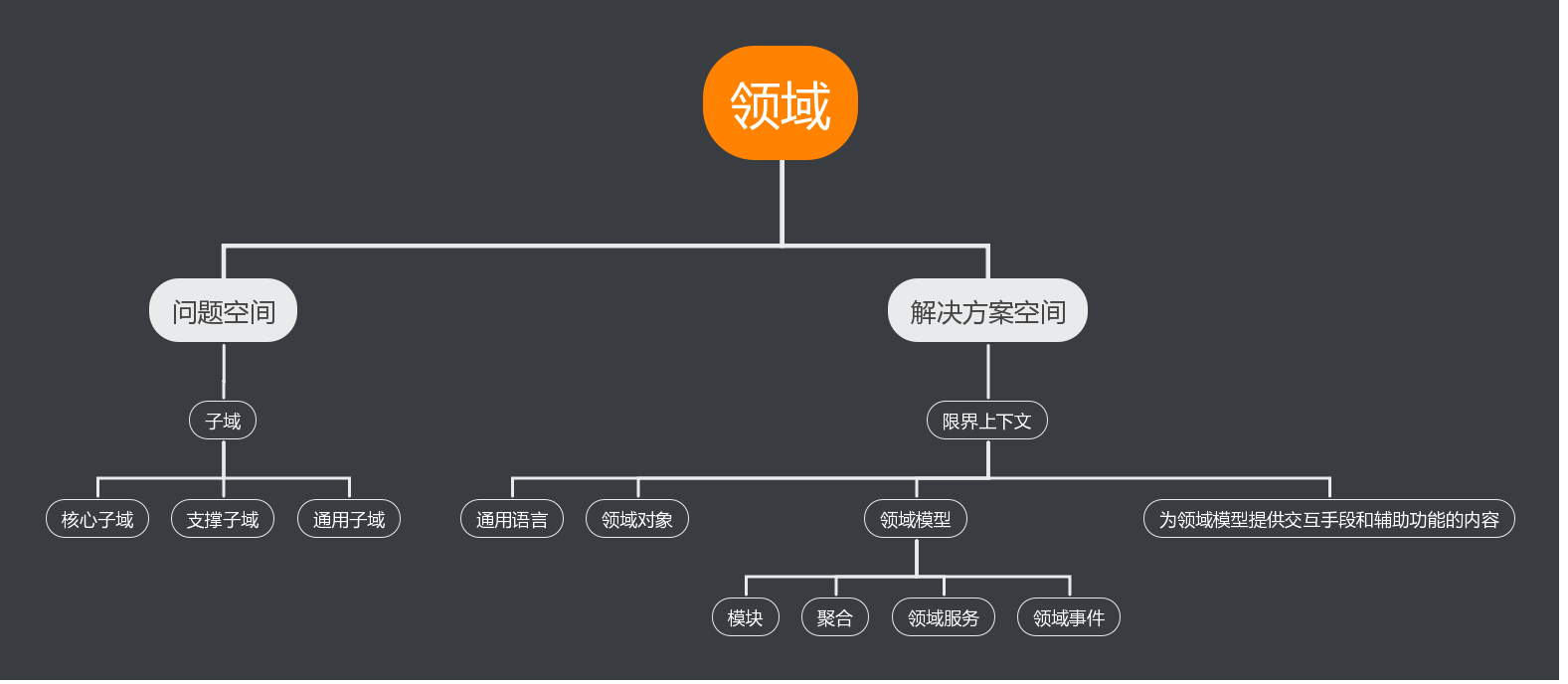
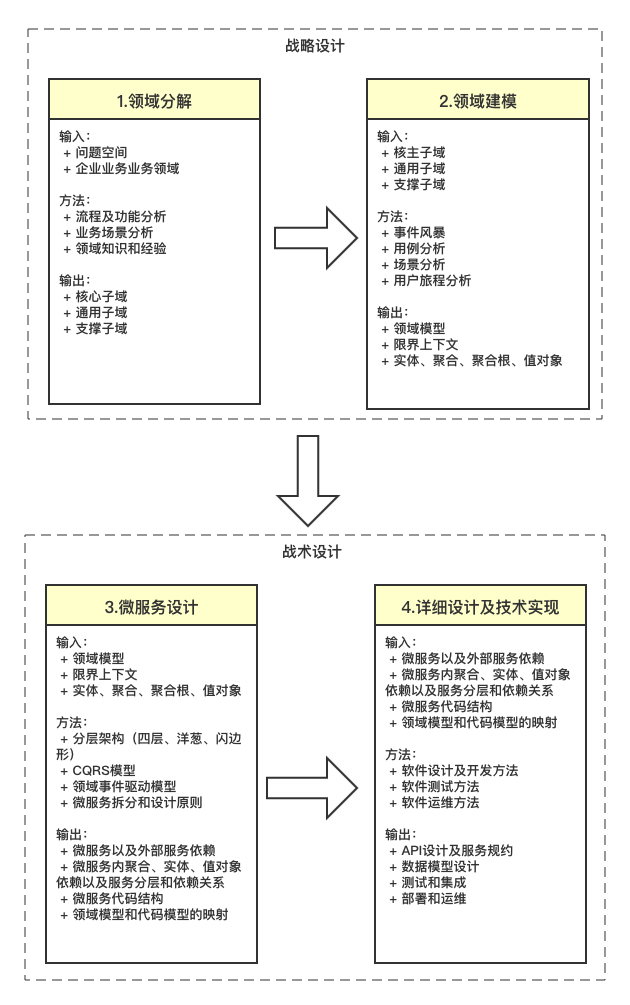
DDD包括战略设计和战术设计两部分,它们分别从不同的视角出发,完成领域建模和微服务的拆分设计。
战略设计是从业务视度出发,划分业务的领域边界,建立限界上下文,构建领域模型。而限界上下文就可以作为微服务拆分和设计的边界。
战术设计则是从技术的角度出发,侧重于对领域模型的技术实现,按照领域模型完成微服务的开发和落地。在战术设计的过程中会产生聚合、聚合根、实体、值对象、领域服务、领域事件、应用服务和仓储等领域对象,这些领域对象会以代码的形式映射到微服务中,完成设计和系统落地。
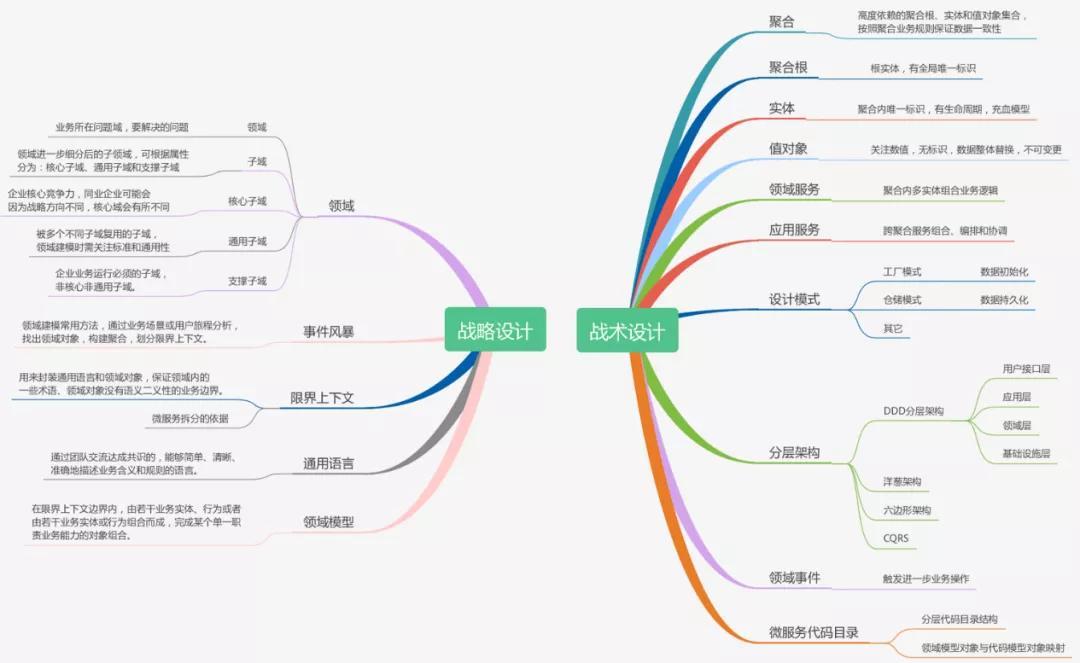
战略设计又包括2块:领域分解和领域建模;
战术设计也包括2块:微服务设计和详细设计及技术实现。
战略设计
限界上下文
限界上下文包含的是一个系统、一个应用、一种业务服务以及一系列实现业务的复杂组件。
限界上下文=限界+上下文
限界:其实说的就是一个子领域的边界,边界的内部都可以理解为上下文,在限界上下文中还有一个概念是“通用语言”
为什么会出现通用语言?
限界上下文中的每种领域术语、词组、或者句子都叫做通用语言,无论是领域专家和开发人员在对领域问题的沟通、需求的讨论,开发计划的制定、概念、还是代码中出现的类名与方法,都包括其中,而且要注意的一个规则是:只要是相同的意思,就应该使用相同的词汇。可以看出,这种通用语言不是一下子就可以形成,而是在一个各方人员的讨论中,不断发现、明确与提炼出来的。
因此,在技术实现中,因为不同的实体对象都是用同一种叫法,因此也就产生了上下文这个概念,我们在描述一个对象时,一定要+前提条件即上下文?
那为什么还要存在“限界”?
因为上下文本来就存在边界,交易和报价等不同的上下文,都限定在一个特定的子领域内,因此也就产生了限界。
一个界限上下文必须支持一个完整的业务流程,保证这个业务流程所涉及的领域都在一个限界上下文中。限界上下文是微服务拆分的依据,即每个限界上下文对应一个微服务。
领域模型
限界上下文是一个显示的边界,领域模型便存在于这个边界之内。领域模型其实就是把通用语言表达成软件模型,领域模型包括了模块、聚合、领域事件和领域服务等概念。
在确定了子域和限界上下文后,那么据可以对子领域范围内的事物进行抽象建模,抽象出实体,值对象和聚合对象用来表达子领域,当然,我们抽象出来的领域模型【名词】是一个静态的内容,因此,一个完整的建模还需要抽象出业务流程中的决策命令【动词】,领域服务等内容,组成一个完整的领域。
子领域
- 核心域
- 支撑域
- 通用域
战术设计
实体
值对象
聚合和聚合根
聚合是一种更大范围的封装,把一组有相同生命周期、在业务上不可分隔的实体和值对象放在一起考虑,只有根实体可以对外暴露引用,这个根实体就是聚合根,聚合也是一种内聚性的表现。
领域、子域、限界上下文、聚合都是用来表示一个业务范围,那他们的关系是怎样的呢?领域、子域、限界上下文属于战略设计,而聚合属于战术设计,聚合的范围是小于前三者的
限界上下文,域,聚合,实体,值对象的关系
领域包含限界上下文,限界上下文包含子域,子域包含聚合,聚合包含实体和值对象
DDD带来的价值:
- 统一语言
- 面向业务建模(mvc是面向数据建模)
- 边界清晰的设计方法(微服务)
- 业务领域知识的沉淀
一些概念:
统一语言
战略设计:
- 领域划分
- 限界上下文
- 子域划分
战术设计: - 实体
- 值对象
- 聚合
- 工厂:封装对象的创建过程
- 领域服务:有些领域中的动作看上去并不属于任何对象。它们代表了领域中的一个重要的行为,不能忽略它们或者简单地把它们合并到某个实体或者值对象中。当这样的行为从领域中被识别出来时,推荐的实践方式是将它声明成一个服务,这个服务就是领域服务。
- 领域事件:领域事件是发生在领域中且值得注意的事件。而领域事件通常意味着领域对象状态的改变。领域事件在系统中起到了传递消息、触发其他动作的作用,是解耦领域模型的重要手段之一。我们往往利用消息队列来传递领域事件。
- 存储服务:资源库(Repository)是一种模式,用于封装数据访问逻辑,提供对数据的持久化和查询。它旨在将数据访问细节与领域模型分离,使领域模型更加独立和可测试。资源库提供了一种统一的接口,使得领域模型可以与不同的数据存储方式(如关系数据库、文档数据库、内存数据库等)进行交互,同时也提供了一些查询操作,以便在领域层中进行数据查询。如果我们使用MyBatis的话,Mapper就是对资源库的一种实现。
领域建模
领域建模的主要目的是捕捉业务知识,形成统一语言,沉淀领域模型。好的领域建模就意味着对业务要有深刻的理解,能够洞察问题本质。领域建模的产出物一般有以下内容:
- 领域模型:包含领域对象、属性、关系、行为、边界范围等各个方面,用于描述业务的本质,这也是最重要的产出物。
- 用例图:用于明确系统的功能。
- 数据模型:描述系统的数据结构和关系,包括实体关系模型、关系数据库模型等。
- 状态图:用于描述系统各个状态及其转移条件。
- 活动图:用于描述系统流程中的各个活动及其关系。
- 序列图:描述系统中各个对象之间的交互过程和消息传递序列。
- 架构模型:包含系统的物理和逻辑结构,包括组件、模块、接口等。
事件风暴建模
简介
我们可以把事件看做行为的印记。比如支付这个行为。我们不需要直接描述支付这个行为,而是通过捕捉这个行为前后的事件:支付发起(Payment Started)和支付完成(Paid)。要知道,事件自身能表达的含义有限,但是将一系列事件按照发生顺序排列起来,就能还原发生过的行为。
通过寻找事件,以及事件背后的领域概念,就能完成对领域概念的挖掘和建模,这就是事件建模的底层逻辑。事件建模法是一种元方法,事件风暴建模就是事件建模的一种。
事件风暴法
概念
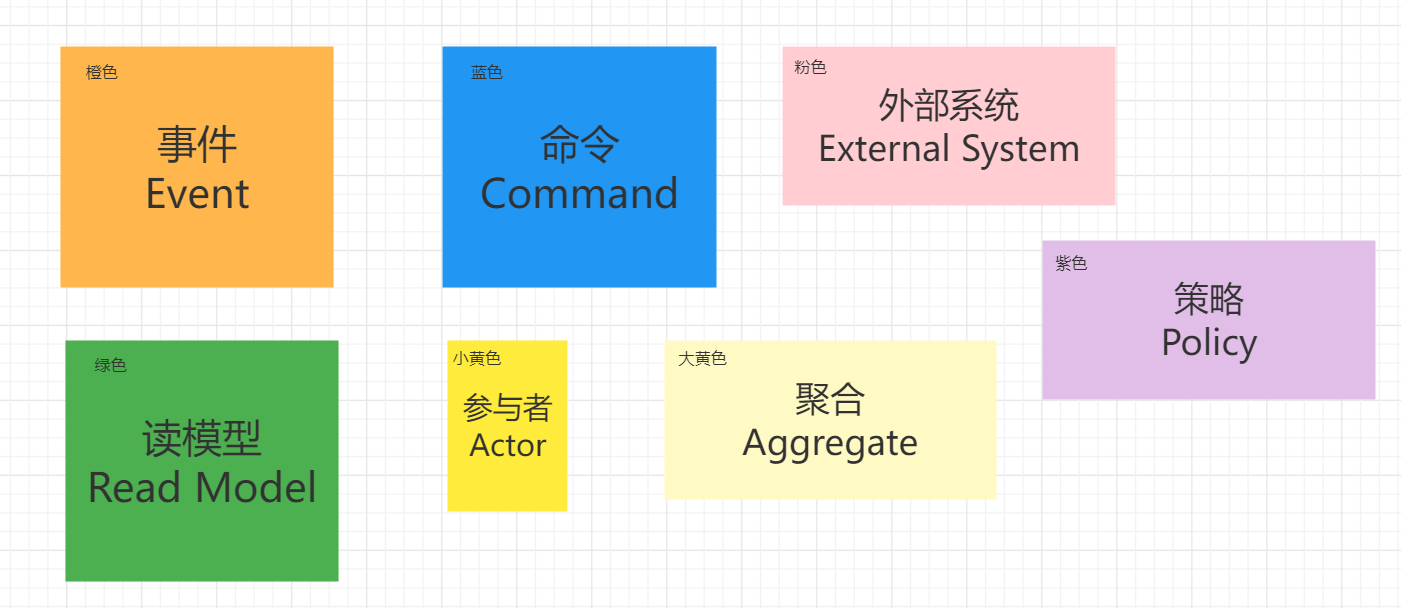
事件风暴通过事件、命令与策略之间的响应关系来组织逻辑。它定义了一套彩色贴纸的”语法”: 不同颜色的贴纸都有定义。浅黄色代表角色(Actor)、蓝色表示命令(Command)、粉色代表业务规则(Policy)、紫色代表系统(System)、橙色代表事件(Event), 绿色表示阅读模型(Read Model)、红色代表热点问题(HotSpot)。
在领域建模的过程中,我们需要重点关注这类业务的语言和行为。比如某些业务动作或行为(事件)是否会触发下一个业务动作,这个动作(事件)的输入和输出是什么?是谁(实体)发出的什么动作(命令),触发了这个动作(事件)… 我们可以从这些暗藏的词汇中,分析出领域模型中的事件、命令和实体等领域对象。
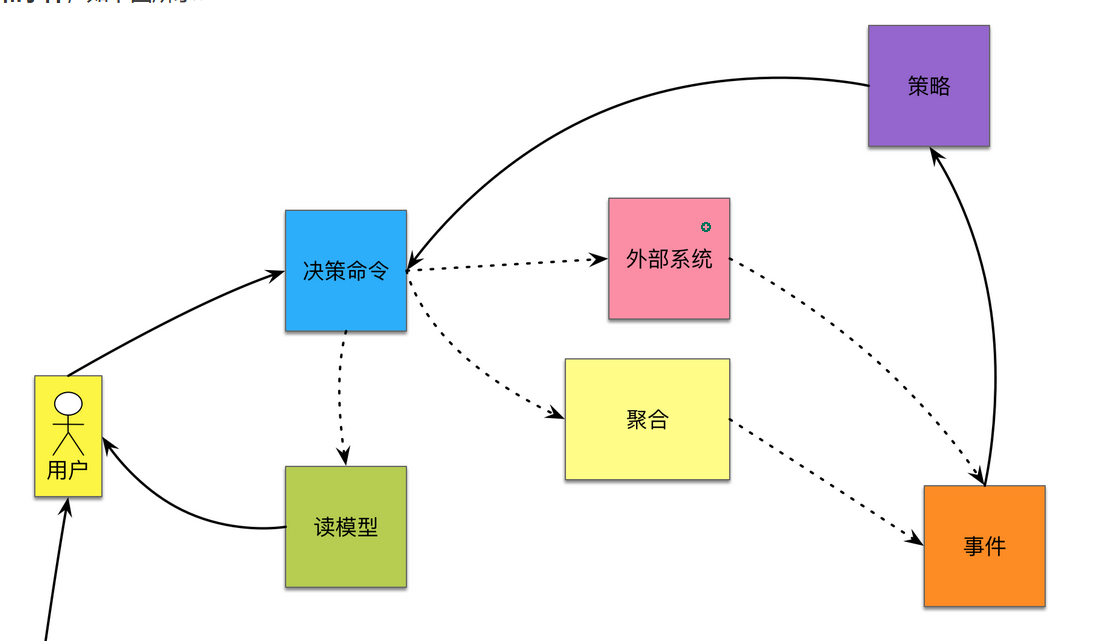
一个 Actor 根据看到的 Query Model/Information,决定对External System 或者 Aggregate 执行一个 Command/Action,进而产生了某种 Domain Event。此 Domain Event 可能触发了某种 Policy,此 Policy 可能又对 External System 或者 Aggregate 执行一个 Command/Action。此 Domain Event 也可能会导致 Query Model/Information 发生变化,从而给 Actor 提供更多信息以进行其他操作。
事件风暴的核心流程就是由用户执行了命令,从而产生了事件。基于这个事件的结果,与之前相同或是其他的用户会执行另一个命令,产生新类型的事件,以此类推。而顺序是按照业务逻辑而定的。
每种语法的具体含义如下:
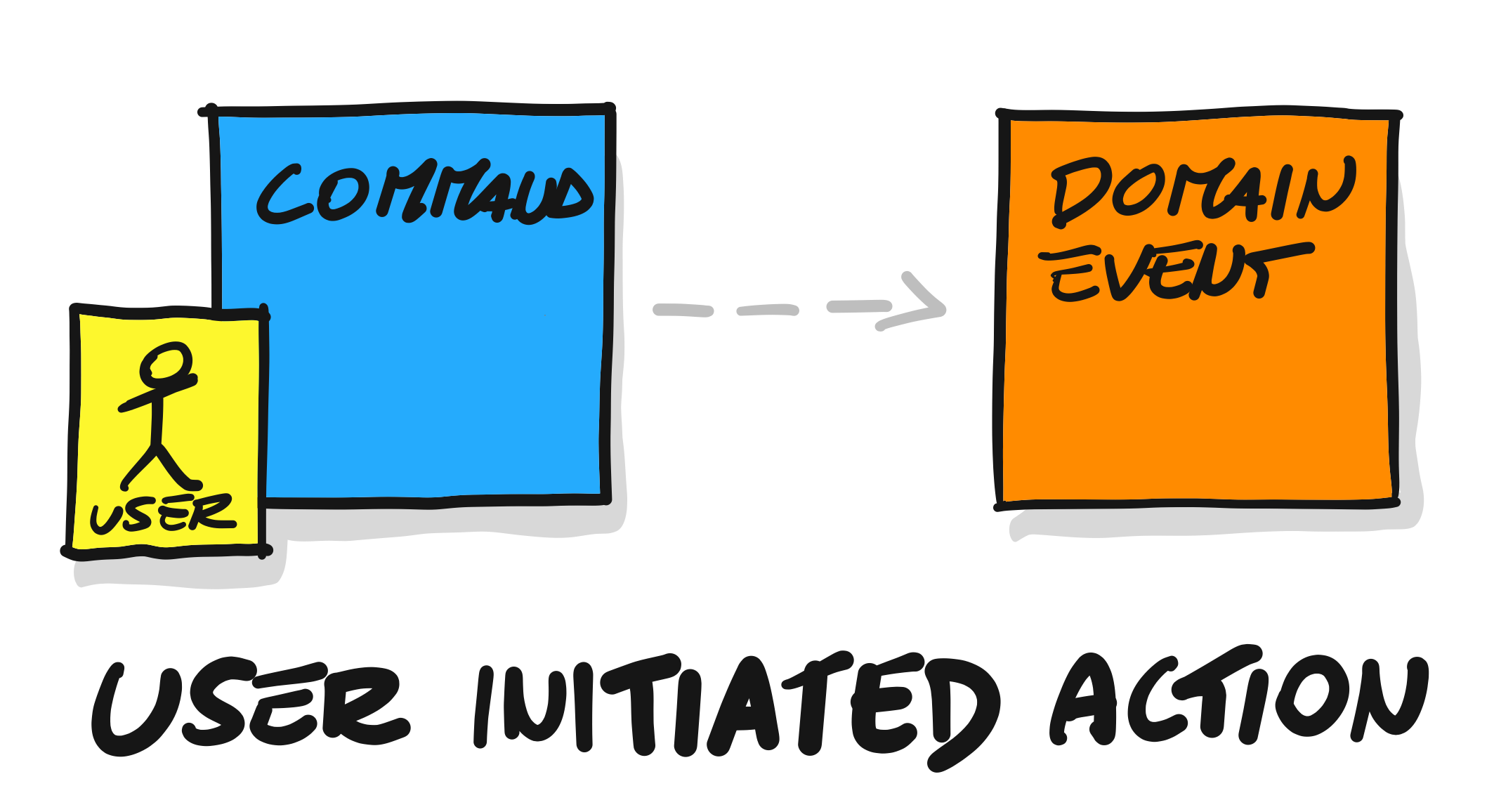
领域事件
正在探索的领域相关的事件。 领域事件的命名需要使用过去式,表示已经发生的事件。如:PatientFollowed 表示患者已随访。
因为领域事件表示与领域相关的事件,不能简单说随访居民已创建等。命名需要代表深刻的业务领域含义。
常见的影响有:
对内:产生了某种数据、触发了某种流程或事情状态发生了某种变化;
对外:发送了某些消息;
规则(Policy):是对分支条件或复杂业务规则的抽象,目的是通过降低分支复杂度聚焦主要业务流程,未来在技术实现时可能是一些分支条件,也可能应用适合的设计模式。
橙色便签表示,通常用过去式表示。

热点Hotspot(IDEAS, RISKS)
热点表示不确定的点、有风险的点或者需要特别注意的点,一般贴在事件旁边,代表这件事情值得特别关注。
使用紫色的贴纸表示。
发起命令的参与者User/Actor
决策命令一定是由某个人或系统来发起的。比如:前面的添加商品这个命令,是由运营人员这个Actor发起的,进而可以联想到可能整个系统中还会有客服、产品经理等。
使用小长方形亮黄色贴纸,结合Command和Event。
外部系统 External System
Event不一定由前面所说的某个Actor触发Command而产生,也可能是由外部系统或者某种规则自动触发Command而产生。
外部系统使用大长方形的粉红色的贴纸表示,处理规则Policy使用大长方形的紫色的贴纸表示。
粉色便签表示。

策略 Policy
根据业务约束和规则自动或手动触发。
紫色便签表示
命令 Command
代表行动、意图。命令在领域事件发生之前,表示事件的触发器。命令(Command)是由行动者发起的行为。它代表了某种决定,通常是事件的起因,如商品已创建(Goods created) 事件对应的决策命令就是添加商品(ADD Goods)。
蓝色便签表示。
读模型 Read Model
某个Actor做出决策Command的前提是需要看到某些信息,或者说,支撑Actor更容易做出决策命令Command的信息。读模型一般是通过Web页面(UI/UX)来展示更多的信息,以让用户更容易做出决策。
绿色便签表示
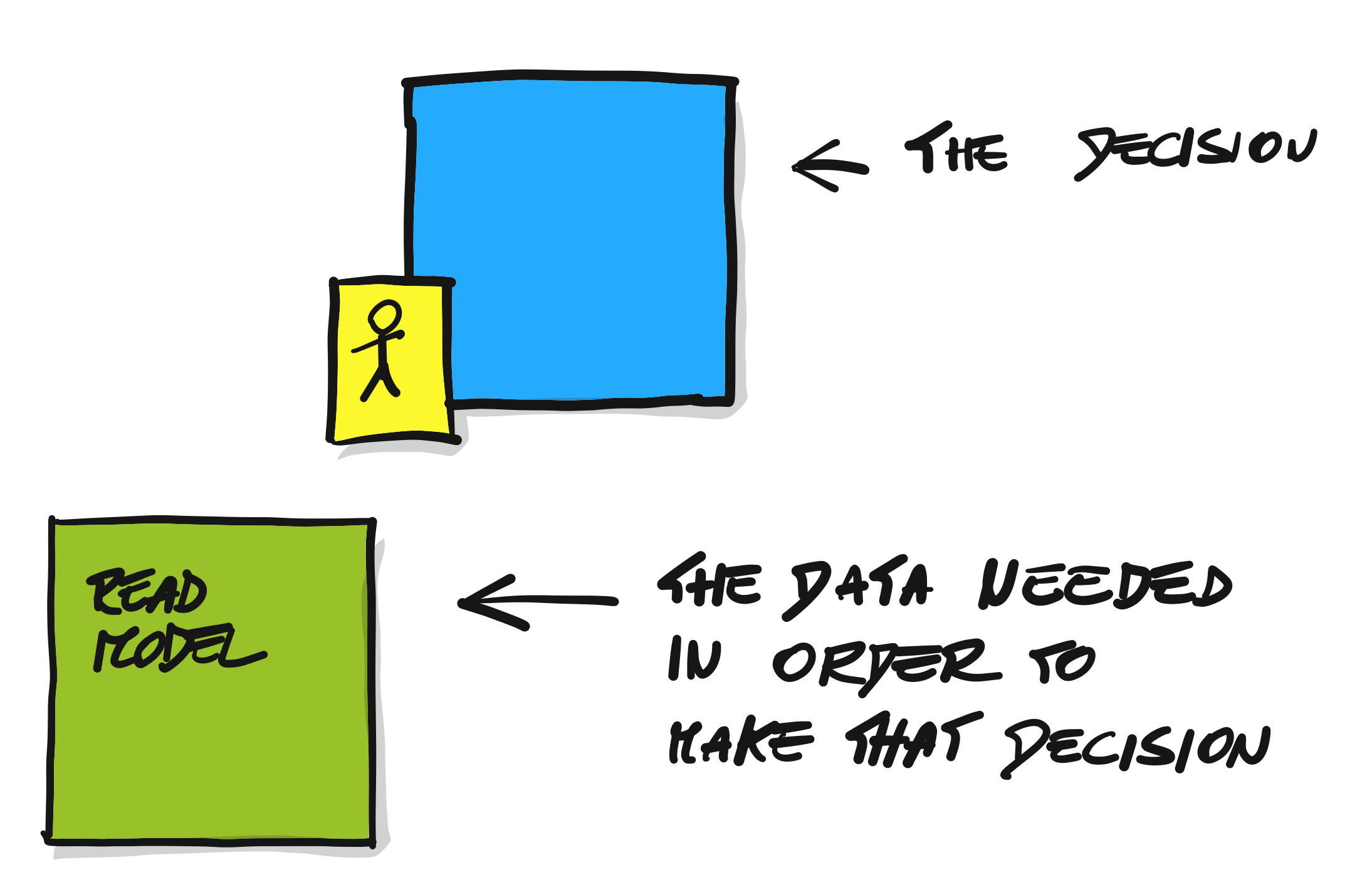
聚合 Aggregate
某个Actor在某个聚合调用某种Command产生了某个Event。比如前面的商品已创建事件,是由 运营人员 在 商品管理 上调用 添加商品 这个命令而产生。
大黄色便签表示
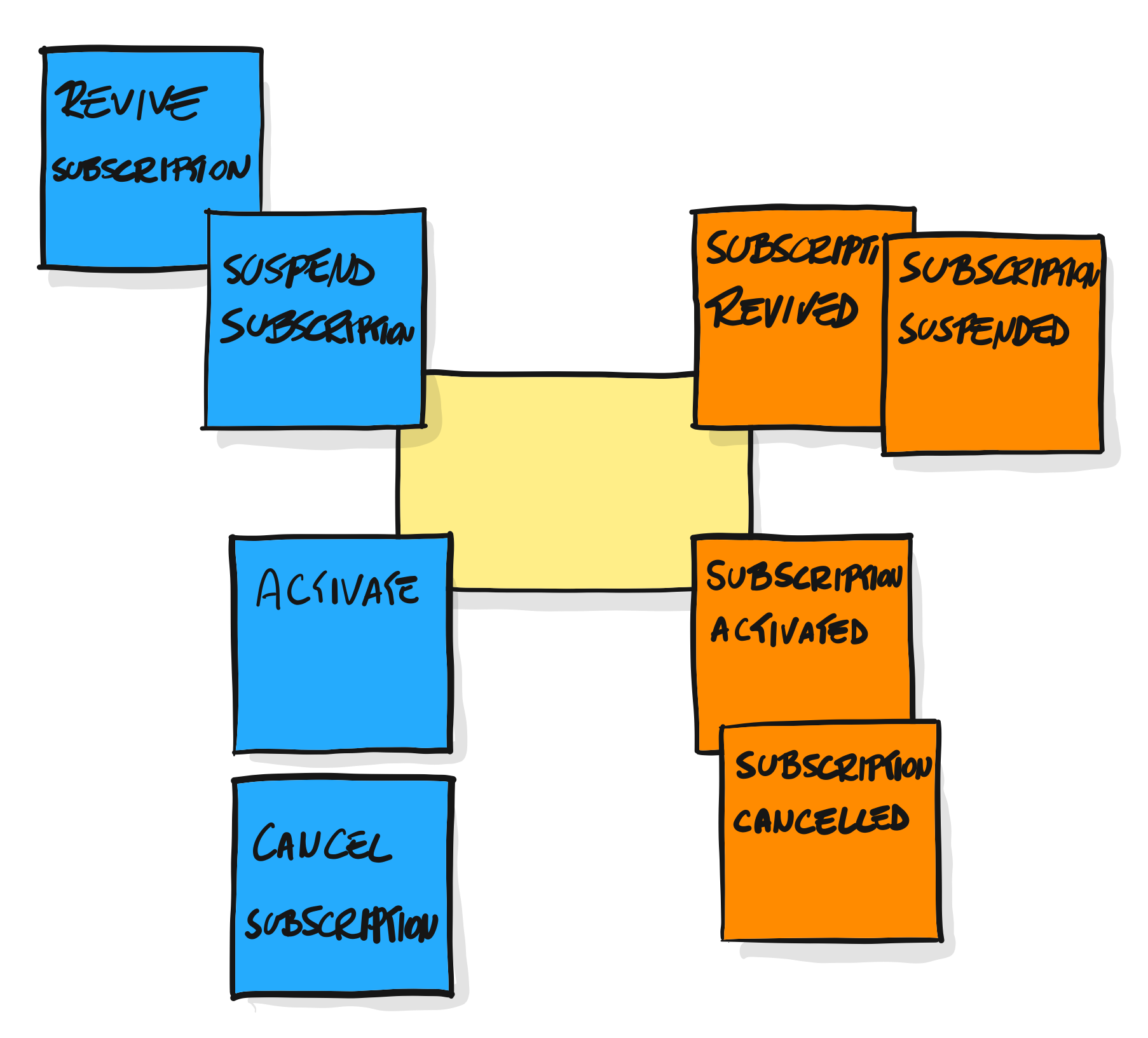
事件风暴的这一系列语法的制定目的,是为了寻找到合适的载体来描述清楚业务逻辑和关键流转过程,从而更方便地在不同角色间传递领域知识。
事件风暴操作流程
第一.准备物料:彩色贴纸、笔纸、一个足够大的房间等。房间里不要有椅子,因为在事件风暴过程中,我们希望大家都全神贯注的投入,而不是坐在椅子上开始放松。
第二.邀请正确的人:有问题的人和有答案的人。程序员、交互设计师、测试等都是有问题的人,需要通过事件风暴理解业务和产品;有答案的人通常是用户、业务或产品,他们通常能回答业务的背景,诉求和目标。
开场介绍
在事件风暴中,有一个特殊角色是主持人,一般也是事件风暴的组织者。主持人有几个重要职责,主持事件风暴、保持参与者的专注、通过提问驱动交流、总结提炼事件风暴建模成果。
在事件风暴正式开始前,由主持人介绍事件风暴是什么、有什么好处以及彩色贴纸的用法。然后介绍本次事件风暴讨论的范围和目标。
例如,此次事件风暴讨论“RabbitAdvisors”中用户订阅专栏的场景,目标是理清从用户发起订阅到用户查看订阅专栏的整个的业务流程。
事件风暴的方式沟通业务
第一步:梳理事件(橙色贴纸)
事件是已发生且重要的事情。事件必须是既成事实,且业务关注的事情。通常主持人会先准备第一个事件(可以是系统中任一事件),然后把它贴到墙上。
假设第一个事件是:专栏已订阅。接下来主持人通过提问引导大家找到更多的事件:
事件发生前有哪些事件?(“专栏已订阅”前须有“订单已支付”事件)
事件发生后下一个事件是什么?
提问会引导参与事件风暴的同学将新发现的事件不断补充到墙上。事件要保持整体的时间顺序:先发生的事情贴在左边,后发生的事情在右边。通常大家容易关注系统的正常流程,也就是Happy path。这时候主持人需要引导大家关注业务的非正常流程Unhappy path。边界条件,异常情况通常是业务复杂性的重要原因,也是非常容易被忽视的部分。
事件一定会发生吗?(订单一定可以创建成功吗?不是,贴上“订单创建失败”事件)
追问unhappy path梳理出业务的完整视图,当大家发现新事件的速度接近停滞的时候,就应进入梳理业务规则的阶段了。
第二步:业务规则(粉色贴纸)
业务规则或者业务逻辑,是业务中最重要的部分,主持人会提出以下问题:
事件是否一定成功?如果不是,那么成功的前提条件是什么?
该事件是否会导致其他事件的发生?
例如“订单已创建”事件的业务逻辑
订单已创建的前提条件是专栏可订阅,同时用户未订阅过该专栏。订单创建后,会导致发起支付。
第三步:行动者(浅黄色贴纸),命令(蓝色贴纸)、阅读模型(绿色贴纸)和系统(紫色贴纸)
主持人通过问题引导:
是什么触发了事件,是命令还是规则
是谁执行了动作,是人还是系统
做出动作前,用户需要获取到哪些信息
通过类似上面的问题,逐步引导大家找到Actor, Command, Read Model
第五步:故事串讲
邀请一名现场成员,按事件发生的时间顺序串讲业务,过程中,听众注意到不一致的地方,提出问题;大家一起讨论,调整相关的事件、逻辑来达成一致。
第六步:产出架构
通过事件风暴,业务流程和处理逻辑应该已经很清楚了,接下来就由架构师产出对应的架构。可以依据事件风暴产出领域模型、用例图、状态图、活动图、序列图等关键架构交付物。
用户下订单案例分析
识别领域事件
先找到发生的事实,将其标记为领域事件,才能发现这些事实涉及哪些对象,对象之间的结构边界才能得到划分,而划分了边界的对象才可能是DDD中的限界上下文。
针对每一个领域事件,项目组成员围绕它进行业务分析,增加各种命令与事件,进行思考与之相关的资源、外部系统与时间。
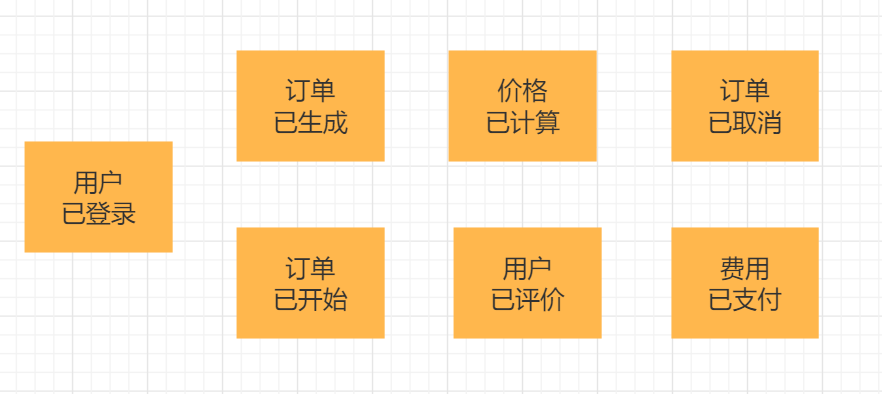
领域事件的设计实现
根据“事件风暴”中分析识别的领域事件,在每次完成相应工作以后增加一个对领域事件的发布。相关信息
事件名称
发布者
发布事件
相关的数据
按时间线组织这些事件,创建由这些事件组成的合理故事

加入界面和命令
事件由命令触发,也可能是外部系统触发,可加入进去。
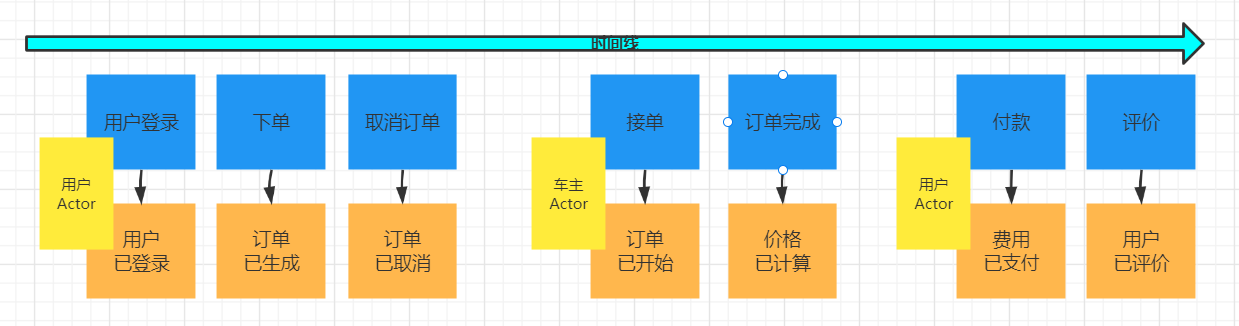
加入聚合,把命令和事件关联起来。
加入聚合后,这一步可继续完善事件,识别逻辑上漏掉的事件。如支付失败事件,接单失败事件等等。都可以添加上去。
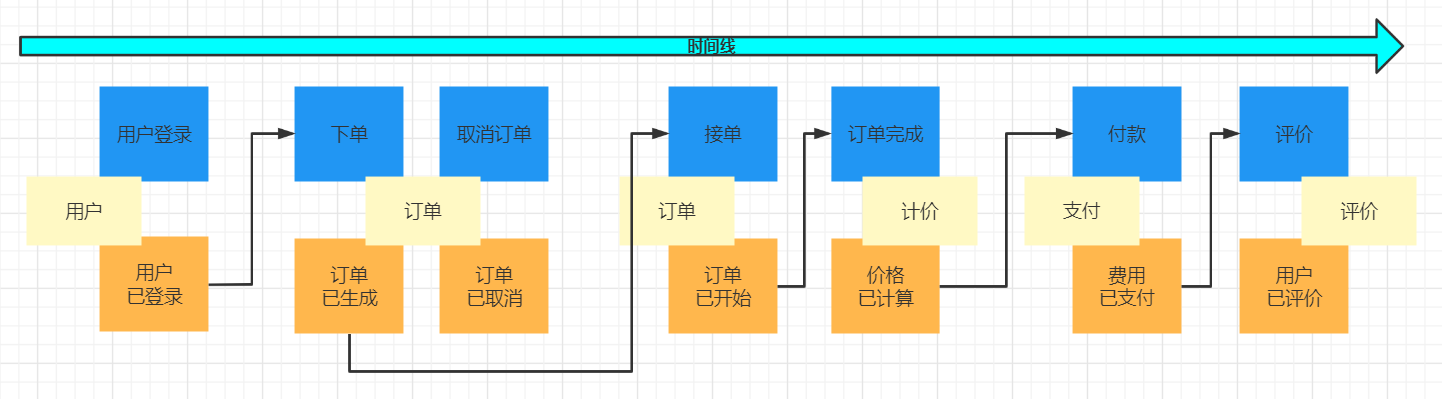
聚合其实就是完成一个完整的业务流程;
发现限界上下文。识别核心子域。
当识别这些聚合后,就可以根据聚合划分限界上下文(有界上下文)。
每个上下文可对应一个微服务。这个视情况而定,比如评价上下文,只是一个小功能,业务上没有其它扩展的话,可以放在用户上下文中,避免服务拆分过细。
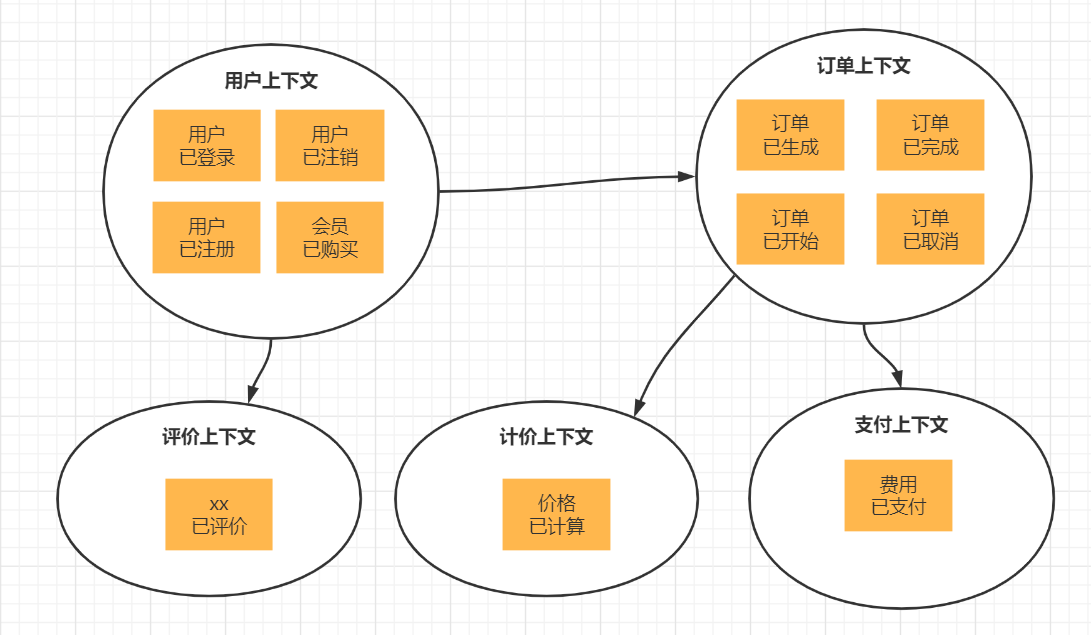
案例二
通过领域模型拆分子领域和限界上下文
通过建模分析,我们一般可以得到领域模型,即目标系统的业务流程图。途中包含了大量的业务对象以及之间的交互。
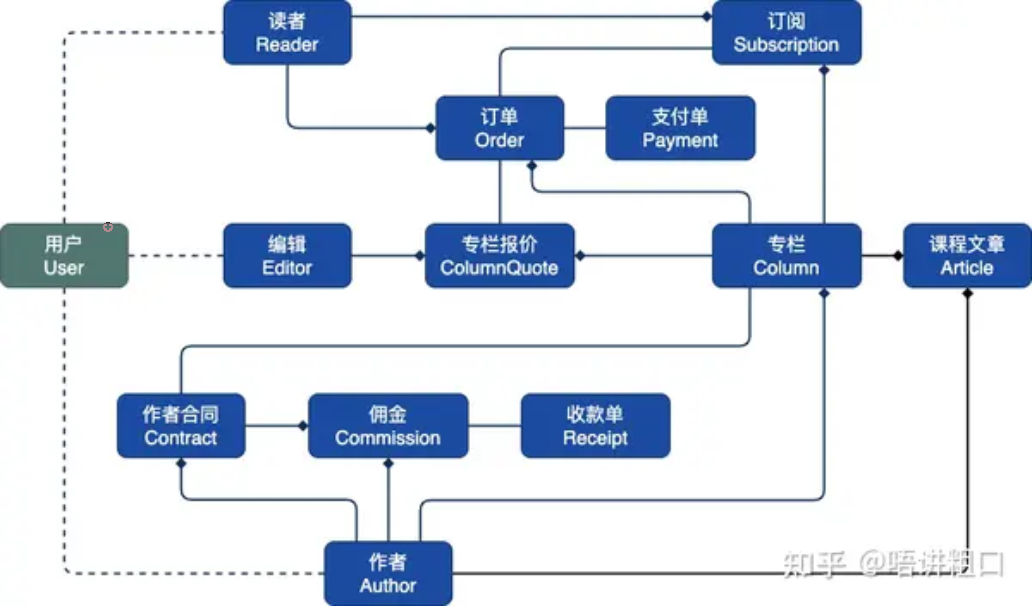
子域划分
领域模型进行子域划分,子域划分时尽量要体现出聚合根,因此子域往往只包含一到两个领域模型,子域中的实体会以值对象的方式聚合其他子域的实体。
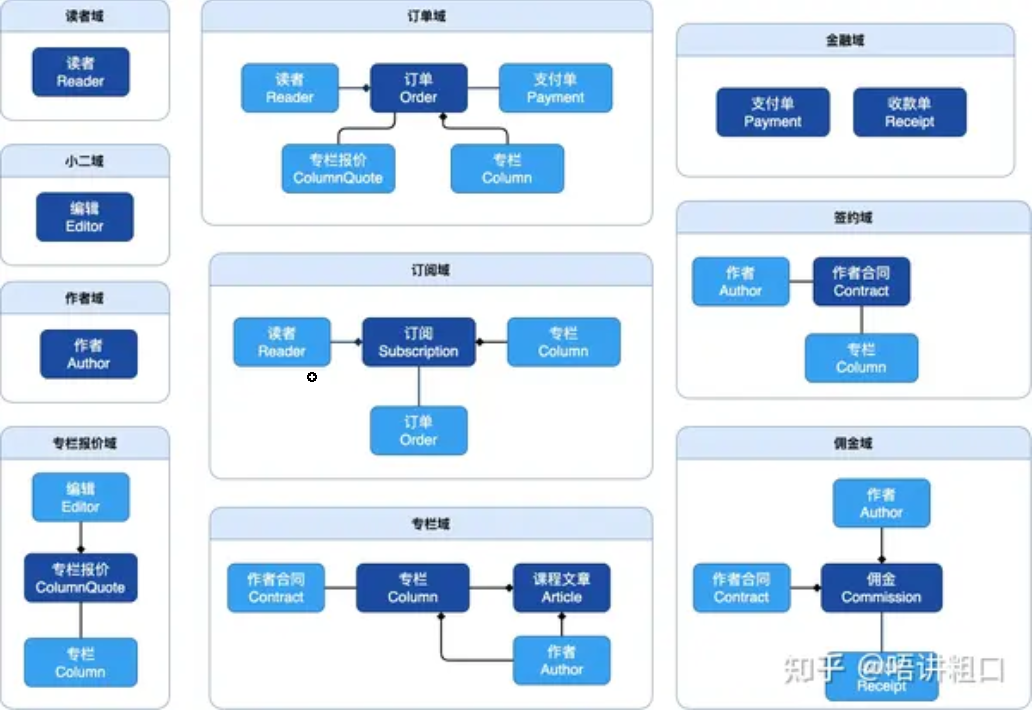
根据子域对于业务重要性的不同,可以分为核心域、支撑域和通用域:
- 核心域包括:订单域、订阅域
- 支撑域:专栏域、专栏报价域、金融域、签约域、佣金域
- 通用域:读者域、小二域、作者域
为了行文简洁,还有一些其他必须的支撑域和通用域没有画出来,比如消息通知域、公告域、评论域等。
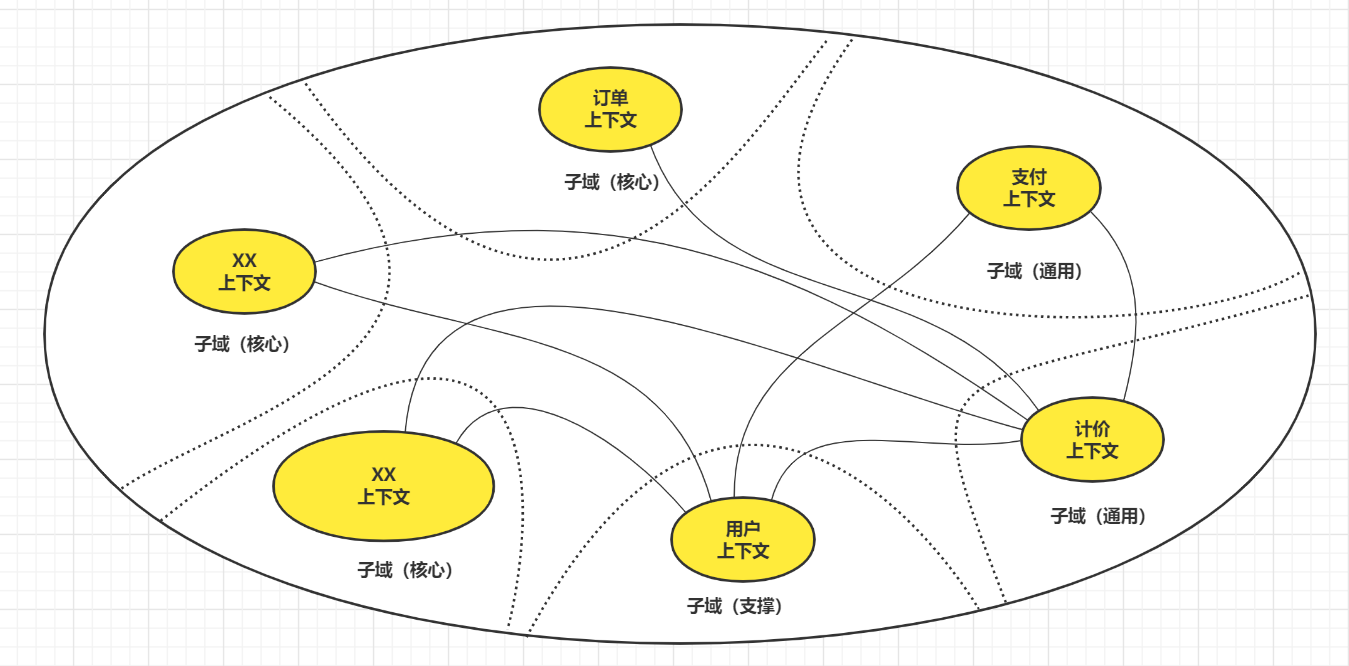
限界上下文划分
限界上下文中划分的一个技巧就是考虑一个完整的业务流程,保证这个业务流程所涉及的领域都在一个限界上下文中,例如“专栏订阅上下文”中包含了用户订阅这个业务流程的关键领域对象。
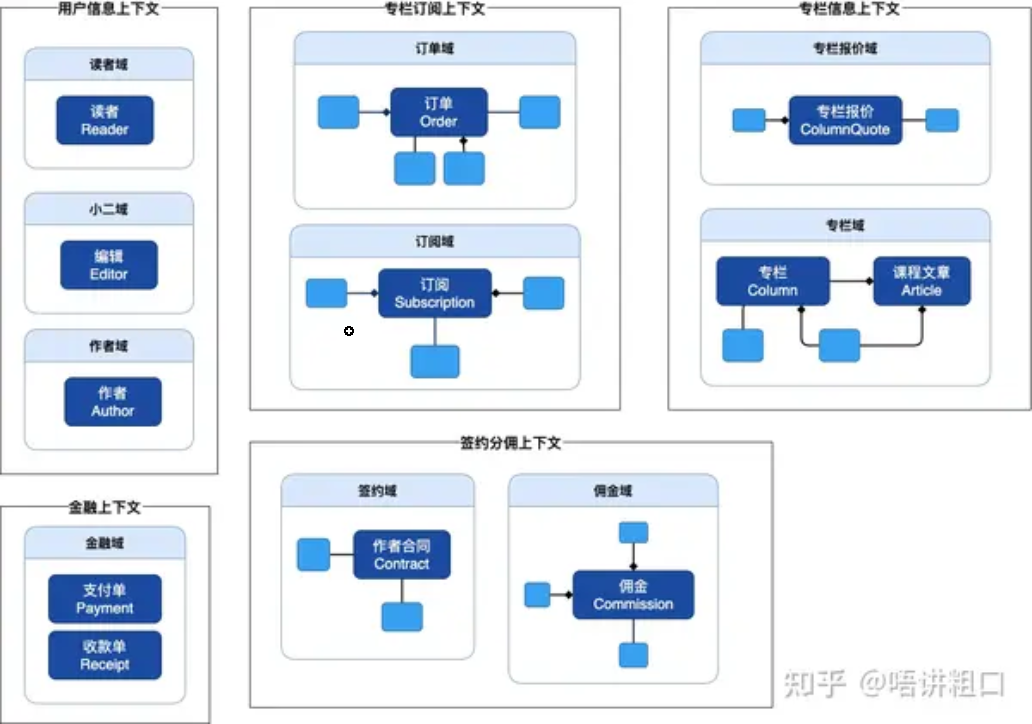
可以看到,限界上下文中可以包含多个子域
限界上下文是指导微服务系统拆分的依据,上图中根据限界上下文的划分,需要拆分成5个微服务系统,分别是 专栏订阅系统、专栏信息系统、签约分佣系统、金融系统以及用户信息系统。
到这里,顶层的架构设计已经完成了,也回答了文章开头的提问:
假如你是“RabbitTech”的CTO,你将会怎样来对“RabbitAdvisors”进行架构设计,又如何给团队分工呢?
关于架构设计,领域建模部分前面已经给出,应用架构将会在“代码实施”一节介绍。 给团队分工可以根据限界上下文,比如这里由五个小组分别负责每个限界上下文的内容。
案例三
识别领域事件
事件风暴是一项团队活动,首先:领域专家和项目成员都聚集在大会议室里,准备好贴纸和水笔,通过头脑风暴的形式把领域中的领域事件(业务行为)都贴到墙上,形成最终的领域事件集合。
以电商为例我们得到以下领域事件集合:
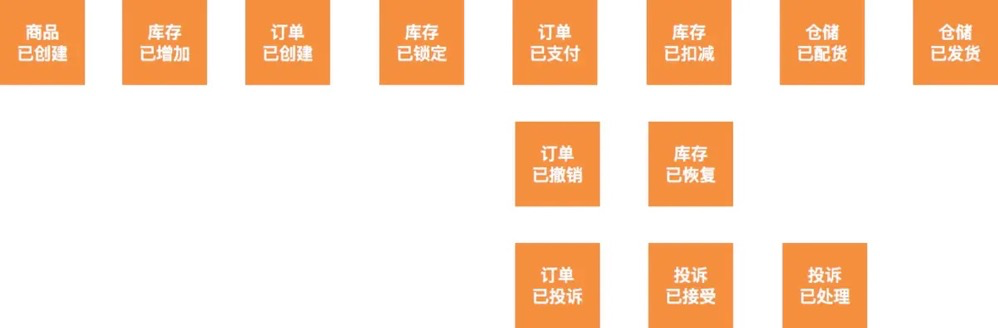
使用 主语+定语 的正方形橘黄色贴纸来描述领域事件,如“订单已创建”。
识别命令
我们已经识别出了部分领域事件,那么这些事件是谁触发的呢?触发的动作又是什么?这就是下一步动作:识别命令。
命令可以理解为不同角色用户在界面上面的操作,比如“添加商品”,“编辑库存”,“提交订单”等; 有些命令可能产生多个事件,可以将他们用箭头联系起来:
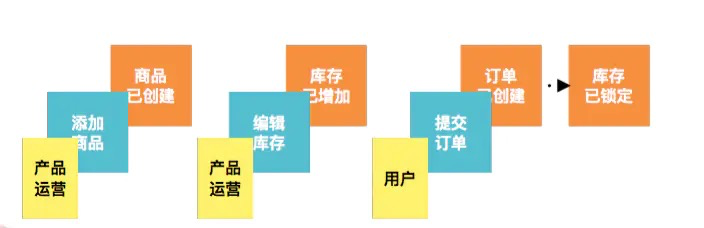
蓝色贴纸来标识命令,黄色贴纸来标识角色。
提取领域对象(实体)
从命令和领域事件中提取产生这些业务行为的业务对象,即实体。一个简单的做法是把领域事件中的名词都提取出来,如“商品已创建”中的“商品”、“订单已创建”中的“订单”、“库存已锁定”中的“库存”等都是领域对象:

黄色贴纸来标识这些实体。
实体(Entity)和值对象(Value Object)是DDD中非常重要的基础领域对象:
实体(Entity):拥有唯一标识符,并且它们的标识符在历经各种状态变更后仍能保持一致,对这些对象而言,重要的不是属性,而是其延续性和标识,这种对象的延续性和标识会跨越甚至超出软件的生命周期,这样的对象就是实体对象。例如:订单 - 有作为唯一标识的订单号。
值对象(Value Object):值对象是通过对象属性值来识别的对象,它将多个相关属性组合为一个概念整体,用于描述领域的某个特定方面,并且是一个没有标识符的对象。例如:订单中的收货地址 - 有姓名、电话、省市区、详细地址等属性字段,被订单这个实体引用。
构建聚合
实体和值对象都只是个体化的业务对象,它们所表现出来的是个体的行为和能力。在领域模型中我们需要一个这样的组织,将这些紧密关联的个体对象聚集在一起,按照组织内统一的业务规则共同完成特定的业务功能,因此就有了聚合的概念。
在DDD中,聚合是一组紧密相关的领域对象,其目的是要确保业务规则在边界内的不变性,保证数据的一致性,聚合根具有全局标识,所有对聚合内对象的修改,都只能通过聚合根进行,聚合帮助我们简化了复杂的对象网络,逐步做到微服务的“高内聚,低耦合”。
从技术的角度可以这么理解,聚合是由业务和逻辑紧密关联的实体和值对象组合而成的。聚合内数据的修改必须由聚合根统一组织,以确保每次数据修改都是按照聚合内统一的业务规则来完成,聚合是数据修改和持久化的基本单元,每一个聚合对应一个仓储,实现 数据的持久化 。
比如订单是个聚合,它是由订单基本信息、商品信息、地址信息、发票信息等多个实体组成的,在订单聚合内每次修改商品数据时,它们都必须符合订单聚合的业务规则:“订单总金额等于所有商品明细金额之和”,违反了这个规则就会出现聚合数据不一致等诸多问题。
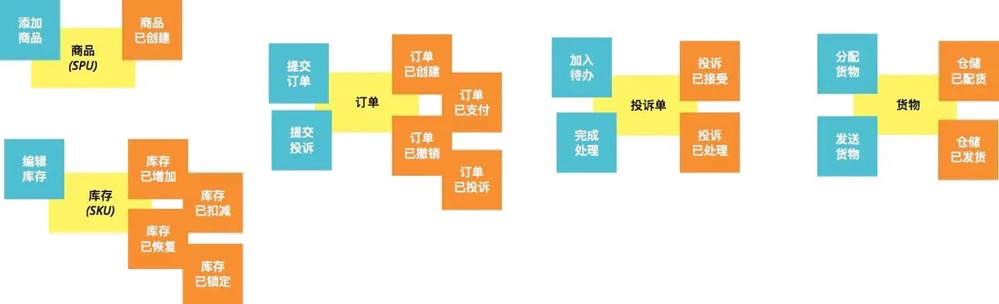
在做聚合的时候,是以实体对象为中心进行分析
划定边界上下文
限界上下文(Boundary Context),是业务上下文的边界,在该边界内,当我们去交流某个业务概念时,不会产生理解和认知上的歧义(二义性),限界上下文是统一语言的重要保证。
一个聚合可能是最小颗粒度的界限上下文,同时,我们常合并业务相关性很高的聚合。
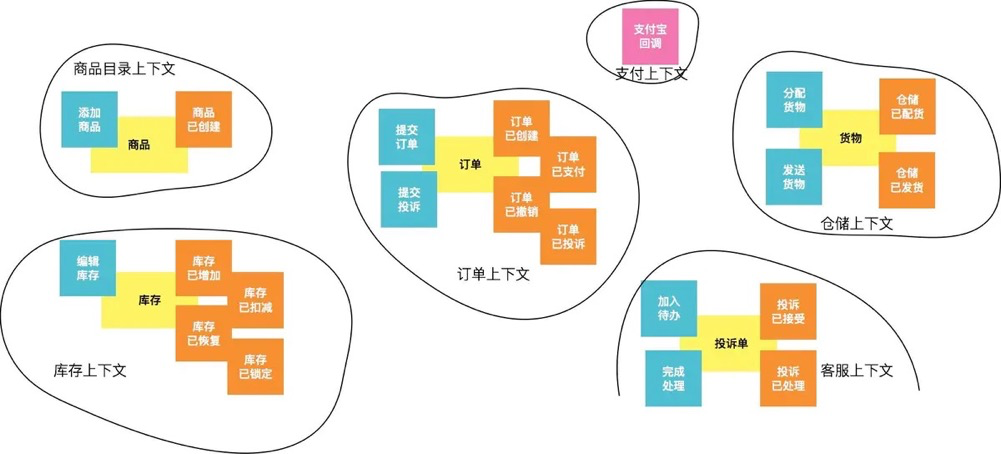
应当尽可能避免两个在概念上容易混淆的限界上下文内的业务需求,被同一个团队开发和维护。
梳理限界上下文依赖关系
通过分析依赖关系,提前识别依赖矛盾,减少低级设计错误的手段。每一个限界上下文都不会带有全量信息,那么补充信息的来源方向就是依赖方向,或者叫“知道(known)”的方向(我需要知道它的存在)。
操作步骤:
集体分析和讨论,并利用带箭头的实线,以依赖方向为箭头方向,绘制不同限界上下文间的依赖关系。
若出现以下依赖关系,需要思考是否存在未澄清的问题:
- (1)双向依赖:上下文之间缺少一层未被澄清的上下文,或者两个上下文其实可被合为一个;
- (2)循环依赖:任何一个上下文发生变更,依赖链条上的上下文均需要改变;
- (3)过长的依赖:自身依赖的信息不能直接从依赖者获取到,需要通过依赖者从其依赖的上下文获取并传递,依赖链路过长,依赖链条上的任何一个上下文发生变更,其链条后的任何一个上下文均可能需要改变。
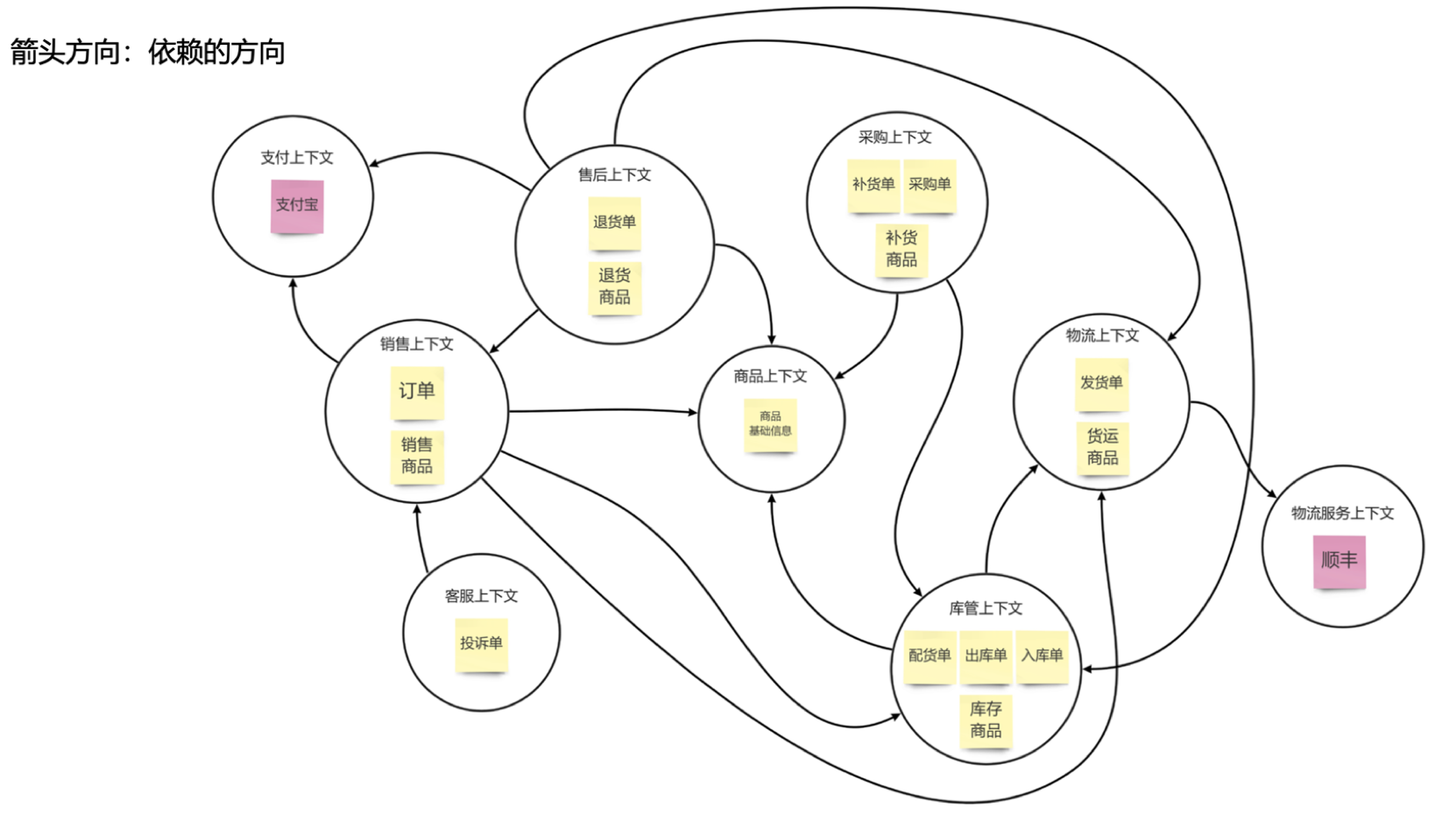
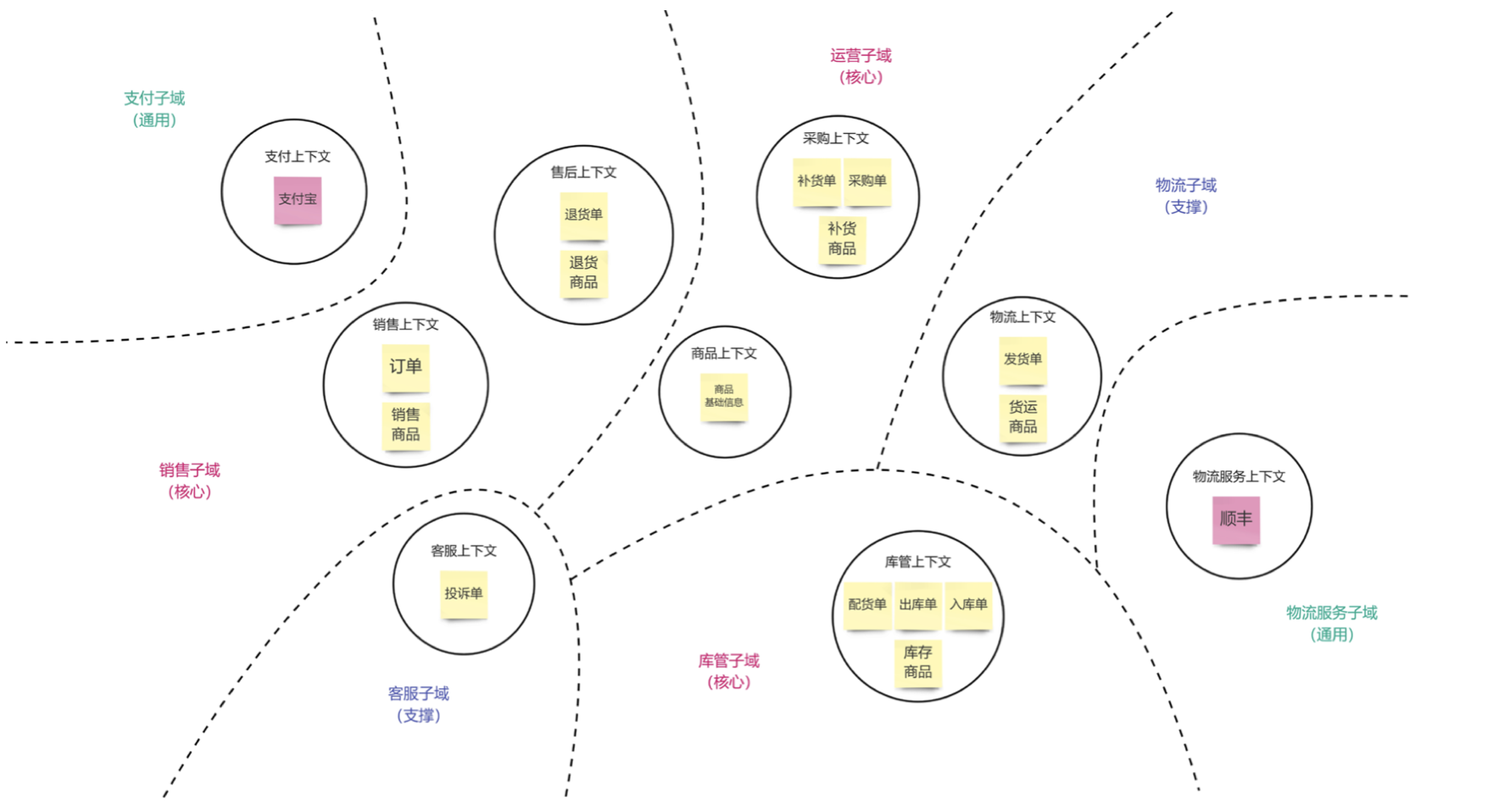
划分问题子域建立服务地图
步骤:
根据 “每一个问题子域负责解决一个有独立业务价值的业务问题” 的视角出发,可以通过疑问句的方式来澄清和分析子域需要解决的业务问题,例如“如何进行库存管理?(英文描述类似 How to…?)”。
利用虚线,将解决同一个业务问题的限界上下文以切割图像的方式划在一起,并以 “XXX子域” 的形式对每个子域进行命名。
根据三种类型的子域定义,共同结合业务实际(或者参考设计思维中的电梯演讲),确定每个子域的子域类型。
PS:
问题子域和限界上下文是完全不同的两个维度,问题子域解决的是问题澄清和优先级排序问题,限界上下文解决的是业务边界识别和统一语言的问题,所以在概念上其实不存在先后关系和包含关系,将两张图放在一起,是为了能够方便设和分析,可以理解为两张图的“叠加”或“映射”。
对于问题子域和限界上下文的映射关系,业内存在争论(是一对多关系还是多对多关系),经过大量的实践,结合可操作性和理解上的便易性,我们刻意地选择和约定以下的映射关系:
- (1)一个子域可以包含多个限界上下文
- (2)一个限界上下文不应跨越多个子域 对于子域类型的判断,会随着视角的切换而有所变化,例如从全局视角识别的支撑域,从该支撑域所负责开发的团队视 角来看,该域则属于这个团队的核心域。
可以先识别核心域,再识别通用域,这样的话最后剩下的就全都是支撑域。
事件风暴小结
事件风暴法通过头脑风暴发现领域事件,以“对于事件的响应”为主要维度寻找事件间的关联,它是一种简单明快的事件建模方法。
但是事件风暴也有一些不足之处,一方面是事件风暴的模式偏重,需要不同角色的成员集体参与,涉及的人员多、流程长。另一方面,也是最关键的一点,事件风暴的成功关键在于收敛逻辑。
在发散阶段,所有参与者可以天马行空。不过这样的方法在产生有效信息的同时,也会产生大量的噪音。但是在收敛阶段,则会按照某一逻辑主线,合并相似概念,过滤无用信息。那么我们可以很容易地想到,如果主持人采用不同的逻辑去收敛事件,最后获得的结果也可能不尽相同。
因此事件风暴法极度依赖主持人的经验与判断,最终结果自然就会存在一定的随意性。这也使得事件风暴法变成了那种“一学就会,一用就废”的方法。有经验的老手越用越顺手,而初学者往往不得要领。
既然最终事件流的质量取决于收敛逻辑,那么我们为什么不直接从收敛逻辑出发,通过引导 - 分析直接获取事件流呢?的确可以这么做,而四色建模法也正是这样一种从收敛逻辑出发的强分析法。
微服务拆分原则
基于业务逻辑拆分
这是最常见的一种拆分方式,将系统中的业务模块按照职责范围识别出来,每个单独的业务模块拆分为一个独立的服务。基于业务逻辑拆分虽然看起来很直观,但在实践过程中最常见的一个问题就是团队成员对于“职责范围”的理解差异很大,经常会出现争论,难以达成一致意见。例如:假设我们做一个电商系统,第一种方式是将服务划分为“商品”“交易”“用户”3 个服务,第二种方式是划分为“商品”“订单”“支付”“发货”“买家”“卖家”6 个服务,哪种方式更合理,是不是划分越细越正确?导致这种困惑的主要根因在于从业务的角度来拆分的话,规模粗和规模细都没有问题,因为拆分基础都是业务逻辑,要判断拆分粒度,不能从业务逻辑角度,而要根据前面介绍的“三个火枪手”的原则,计算一下大概的服务数量范围,然后再确定合适的“职责范围”,否则就可能出现划分过粗或者过细的情况,而且大部分情况下会出现过细的情况。例如:如果团队规模是 10 个人支撑业务,按照“三个火枪手”规则计算,大约需要划分为 4 个服务,那么“登录、注册、用户信息管理”都可以划到“用户服务”职责范围内;如果团队规模是 100 人支撑业务,服务数量可以达到 40 个,那么“用户登录“就是一个服务了;如果团队规模达到 1000 人支撑业务,那“用户连接管理”可能就是一个独立的服务了。
基于可扩展拆分
将系统中的业务模块按照稳定性排序,将已经成熟和改动不大的服务拆分为稳定服务,将经常变化和迭代的服务拆分为变动服务。稳定的服务粒度可以粗一些,即使逻辑上没有强关联的服务,也可以放在同一个子系统中,例如将“日志服务”和“升级服务”放在同一个子系统中;不稳定的服务粒度可以细一些,但也不要太细,始终记住要控制服务的总数量。这样拆分主要是为了提升项目快速迭代的效率,避免在开发的时候,不小心影响了已有的成熟功能导致线上问题。
基于可靠性拆分
将系统中的业务模块按照优先级排序,将可靠性要求高的核心服务和可靠性要求低的非核心服务拆分开来,然后重点保证核心服务的高可用。具体拆分的时候,核心服务可以是一个也可以是多个,只要最终的服务数量满足“三个火枪手”的原则就可以。
这样拆分带来下面几个好处:
1).避免非核心服务故障影响核心服务
例如,日志上报一般都属于非核心服务,但是在某些场景下可能有大量的日志上报,如果系统没有拆分,那么日志上报可能导致核心服务故障;拆分后即使日志上报有问题,也不会影响核心服务。
2).核心服务高可用方案可以更简单
核心服务的功能逻辑更加简单,存储的数据可能更少,用到的组件也会更少,设计高可用方案大部分情况下要比不拆分简单很多。
3).能够降低高可用成本
将核心服务拆分出来后,核心服务占用的机器、带宽等资源比不拆分要少很多。因此,只针对核心服务做高可用方案,机器、带宽等成本比不拆分要节省较多。
基于性能拆分
基于性能拆分和基于可靠性拆分类似,将性能要求高或者性能压力大的模块拆分出来,避免性能压力大的服务影响其他服务。常见的拆分方式和具体的性能瓶颈有关,可以拆分 Web 服务、数据库、缓存等。例如电商的抢购,性能压力最大的是入口的排队功能,可以将排队功能独立为一个服务。
以上几种拆分方式不是多选一,而是可以根据实际情况自由排列组合,例如可以基于可靠性拆分出服务 A,基于性能拆分出服务 B,基于可扩展拆分出 C/D/F 三个服务,加上原有的服务 X,最后总共拆分出 6 个服务(A/B/C/D/F/X)。
DDD应用架构框架
阿里的张健飞开源了一个DDD应用架构框架——Cola,github地址:
https://github.com/alibaba/cola,他综合了六边形和洋葱架构的思想,将业务复杂度和技术复杂度分离,各层之间通过防腐层进行通讯,尽最大可能的解耦,是一个不错的学习DDD的框架。