
1、K8S部署应用
1、理论部分
1.1、那些服务适合部署在k8s上?
1、进程间高度耦合的应用:此类应用具有高度耦合特点,不利于横向拓展。例如:应用间通信使用非API设计;单个进程启动依赖其他进程启停。此类应用建议改造,使用接口通信,利于横向拓展。例如使用共享内存,管道,信号、信号量等做进程间通信,就不适合部署在容器云上。
2、单个进程启动依赖其他进程启停,容器云是一种不可变的基础设施,POD在云上可以进行漂移,扩缩容,所以通过容器云建设的应用系统启停次数会比通过虚拟机建设的应用系统更加频繁一些。
3、此类应用具有大量存储IO读写的特点,不利于数据快速落盘和读取。例如:数据库。集中式的网络存储要求非常高,并且不可以随时进行横向扩展。典型的例如高吞吐的集中式数据库,高吞吐的有状态应用需要落地数据。
4、安全敏感的服务:例如,某些服务需要严格的安全控制,可能不适合部署在公共云或不受保护的环境中。
5、资源密集型应用程序:某些应用程序可能会消耗大量资源,如果部署在k8s上,可能会影响集群中其他服务的性能。(内存,cpu,网络,存储)
1.2、容器运行原理
项目(project):
项目是容器云中的一级租户,即最大的租户。项目包含容器云内的部分资源(CPU、内存、存储,网络,命名空间),在项目内可继续划分命名空间,将项目包含的资源池分配至命名空间。通常,在同一环境中项目与应用系统一一对应。
命名空间(namespace):
命名空间是容器云中的二级租户,包含于项目,从项目中分配资源,命名空间之间相互隔离。在交易中心容器云建设过程中,一个项目通常包含2个命名空间,分别对应发布层和应用层应用的部署。开发测试环境可新增其他命名空间,基于命名空间的隔离性快速搭建多套开发测试环境。
容器(container):
镜像是一个包含程序运行代码和必要环境的只读文件,而容器container是镜像的一个运行态。(程序和进程);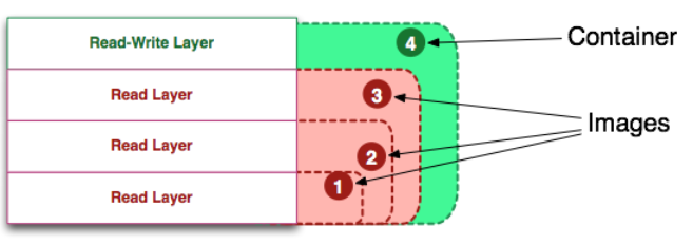
运行状态的容器「Running Container」是由一个可读写的文件系统「静态容器」+ 隔离的进程空间和其中的进程构成的。如下图所示。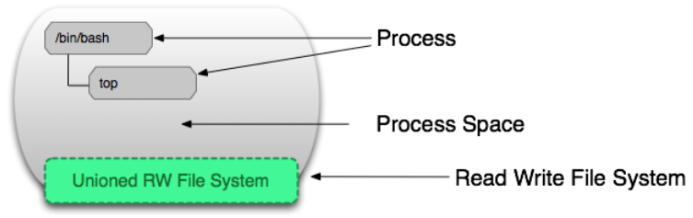
容器组(pod):
pod是一组(一个或多个)容器;这些容器共享存储、网络、以及怎样运行这些容器的声明。Pod 中的内容总是并置(colocated)的并且一同调度,在共享的上下文中运行。Pod所建模的是特定于应用的“逻辑主机”,其中包含一个或多个应用容器,这些容器是相对紧密的耦合在一起的。在非云环境中,在相同的物理机或虚拟机上运行的应用类似于在同一逻辑主机上运行的云应用。
一个pod内部可以通常部署多个容器,但是一般不建议这样做,会导致一个pod很重,重启一次很慢,一般会将服务拆开,部署在多个pod上,而不是在一个pod内部启多个容器。

资源申请:
注:通常以项目为单位申请资源,dev,st,uatc,new-uat,sijm,prod各个环境的总资源申请量建议保持一致,不需要做减半处理,方便跟踪各个环境的服务部署和测试。
1.3、项目部署理论
代码怎么交付,应用如何集成,服务如何部署
1.3.1、项目开发需要考虑什么维度
DEV:怎么开发?
OPS:怎么运维?
高并发:怎么承担高并发?
高可用:怎么做到高可用?
1.3.2、什么是DEVOPS?
1.3.3、什么是CICD
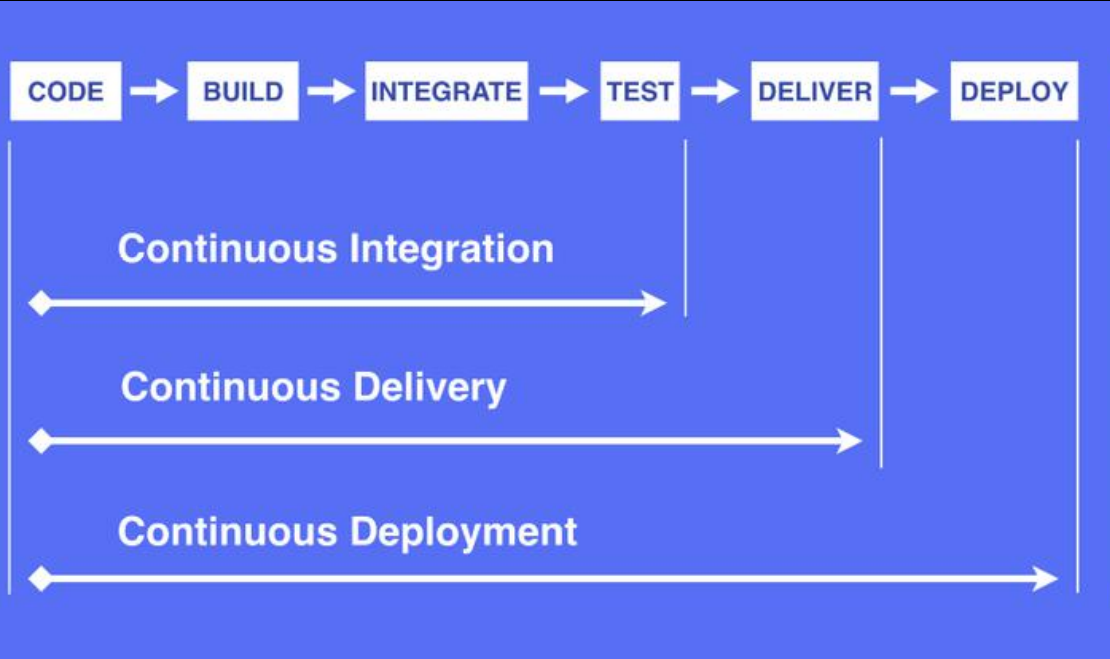
持续集成(Continuous Integration)
持续集成是指软件个人研发的部分向软件整体部分交付,频繁进行集成以便更快地发现 其中的错误。“持续集成”源自于极限编程(XP),是 XP 最初的 12 种实践之一。
CI 需要具备这些:
- 全面的自动化测试。这是实践持续集成&持续部署的基础,同时,选择合适的 自动化测试工具也极其重要;
- 灵活的基础设施。容器,虚拟机的存在让开发人员和 QA 人员不必再大费周折;
- 版本控制工具。如 Git,CVS,SVN 等;
- 自动化的构建和软件发布流程的工具,如 Jenkins,flow.ci;
- 反馈机制。如构建/测试的失败,可以快速地反馈到相关负责人,以尽快解决 达到一个更稳定的版本。
持续交付(Continuous Delivery)
持续交付在持续集成的基础上,将集成后的代码部署到更贴近真实运行环境的「类生产环境」(production-like environments)中。持续交付优先于整个产品生命周期的软件部署,建立 在高水平自动化持续集成之上。 灰度发布。
持续交付和持续集成的优点非常相似:
- 快速发布。能够应对业务需求,并更快地实现软件价值。
- 编码->测试->上线->交付的频繁迭代周期缩短,同时获得迅速反馈;
- 高质量的软件发布标准。整个交付过程标准化、可重复、可靠,
- 整个交付过程进度可视化,方便团队人员了解项目成熟度;
- 更先进的团队协作方式。从需求分析、产品的用户体验到交互 设计、开发、测试、运维等角色密切协作,相比于传统的瀑布式软件团队,更少浪费。
持续部署(Continuous Deployment)
持续部署是指当交付的代码通过评审之后,自动部署到生产环境中。持续部署是持续交付的 最高阶段。这意味着,所有通过了一系列的自动化测试的改动都将自动部署到生产环境。它 也可以被称为“Continuous Release”
“开发人员提交代码,持续集成服务器获取代码,执行单元测试,根据测 试结果决定是否部署到预演环境,如果成功部署到预演环境,进行整体 验收测试,如果测试通过,自动部署到产品环境,全程自动化高效运转。”
持续部署主要好处是,可以相对独立地部署新的功能,并能快速地收集真实用户的反馈。
持续交付工具链图:
1.3.4、落地方案
Maven+Gitlab+Jenkins(Hudson[现由甲骨文维护])+灵雀云(K8S)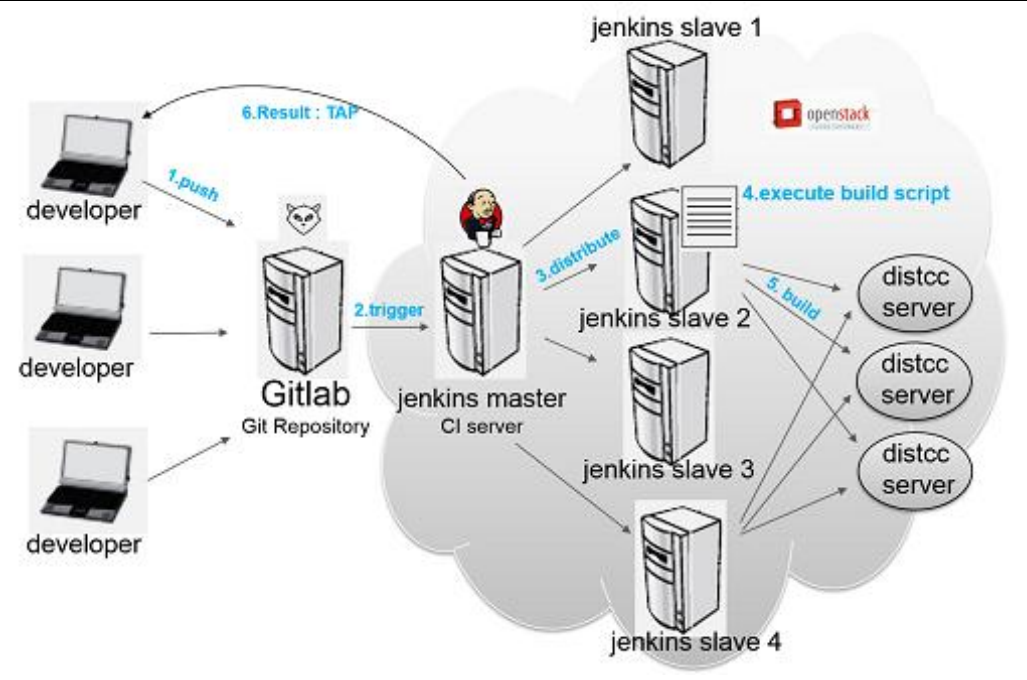
2、项目落地
2.1、镜像制作(原料)
2.1.1、分析关联的类库(镜像配置)
镜像是将应用程序放进去封装,应用需要的基础运行库及相关依赖需要一同打包进去。在制作镜像前,首先要分析目标打包应用的关联类库,有哪些,需要应用开发人员协助。镜像就可以理解为我们经过层层封装的一个文件系统,比如添加环境变量,配置一些应用运行需要的环境信息,安装软件运行工具包等。
2.1.2、分析资源
预估容器可能需要的资源,设定本容器所需各类资源的最小值和最大值,也即CPU、内存的request和limits,对应用在资源申请范围做一定的限制。requests申请范围是0到Node节点的最大配置,而limits申请范围是requests到无限,即0 <= requests <=Node Allocatable, requests <= limits <= Infinity。
对于CPU,如果pod中服务使用CPU超过设置的limits,pod不会被kill掉但会被限制。如果没有设置limits,pod可以使用全部空闲的cpu资源。
对于内存,当一个pod使用内存超过了设置的limits,pod中container的进程会被kernel因OOM kill掉。当container因为OOM被kill掉时,系统倾向于在其原所在的机器上重启该container或本机或其他重新创建一个pod。
2.1.3、编写Dockerfile文件。
Dockerfile 常用的指令如下:
| Dockerfile 指令 | 指令简介 |
|---|---|
| FROM | Dockerfile 除了注释第一行必须是 FROM ,FROM 后面跟镜像名称,代表我们要基于哪个基础镜像构建我们的容器。 |
| RUN | RUN 后面跟一个具体的命令,类似于 Linux 命令行执行命令。 |
| ADD | 拷贝本机文件或者远程文件到镜像内 |
| COPY | 拷贝本机文件到镜像内 |
| USER | 指定容器启动的用户 |
| ENTRYPOINT | 容器的启动命令 |
| CMD | CMD 为 ENTRYPOINT 指令提供默认参数,也可以单独使用 CMD 指定容器启动参数 |
| ENV | 指定容器运行时的环境变量,格式为 key=value |
| ARG | 定义外部变量,构建镜像时可以使用 build-arg = 的格式传递参数用于构建 |
| EXPOSE | 指定容器监听的端口,格式为 [port]/tcp 或者 [port]/udp |
| WORKDIR | 为 Dockerfile 中跟在其后的所有 RUN、CMD、ENTRYPOINT、COPY 和 ADD 命令设置工作目录。 |
DockerFile文件案例:
//DockerFile 案例
FROM 172.17.242.111:5001/dw2020/s2i-uos20-jdk8:1.0.0
add trace-ms-msg-1.1.27.0 /opt/trace-ms-msg-deploy/trace-ms-msg-1.1.27.0
RUN chmod +x /opt/trace-ms-msg-deploy/trace-ms-msg-1.1.27.0/imtapi-B172A.el7.x86_64P/lib/*
RUN ln -s /opt/trace-ms-msg-deploy/trace-ms-msg-1.1.27.0/imtapi-B172A.el7.x86_64/lib/libdspimtapijni.so /lib
RUN ln -s /opt/trace-ms-msg-deploy/trace-ms-msg-1.1.27.0/imtapi-B172A.el7.x86_64/lib/libucfutil.so /lib
WORKDIR /opt/trace-ms-msg-deploy/trace-ms-msg-1.1.27.0/bin
ENV LANG zh_CN.UTF-8
ENV TZ=Asia/Shanghai
ENV DOCKER_HOST_IP true
ENV TRACEMSMSG_HOME /opt/trace-ms-msg-deploy/trace-ms-msg-1.1.27.0
CMD sh startup.sh2.1.4、镜像打包&推送镜像
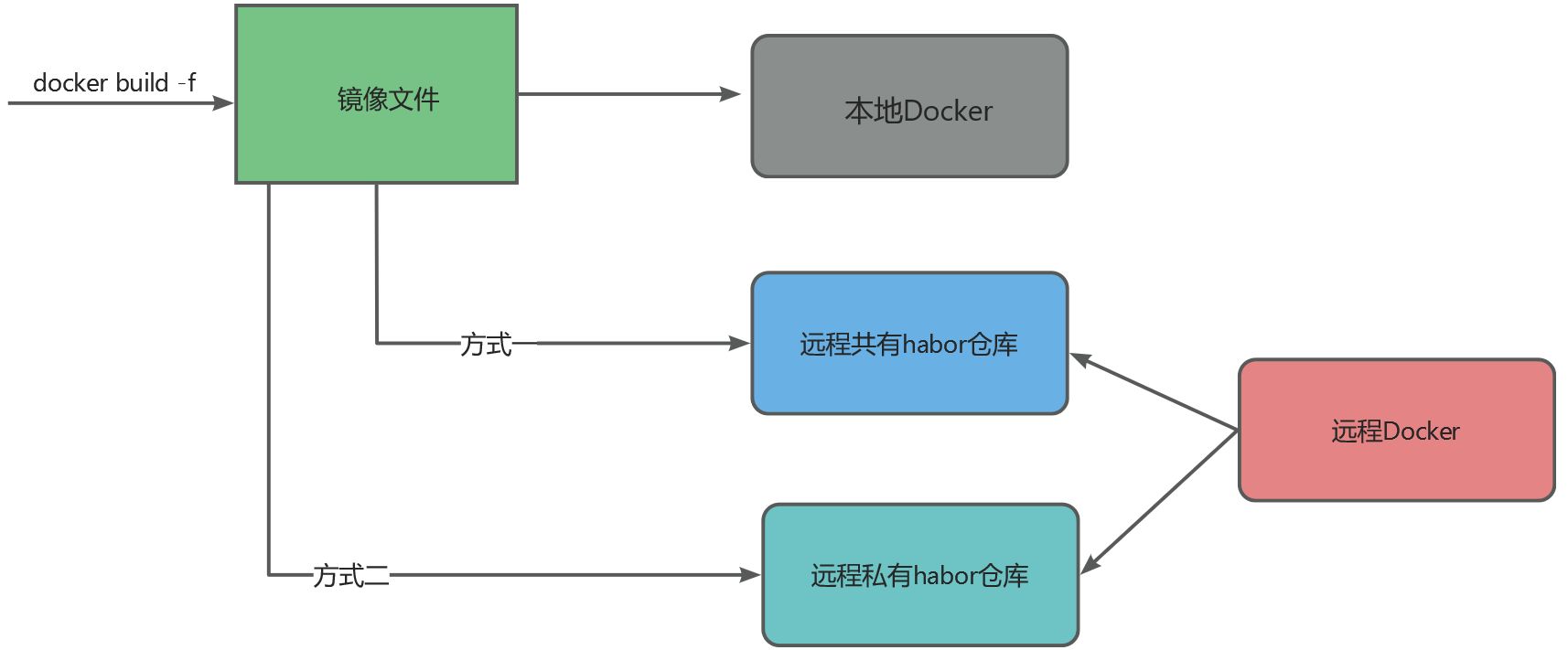
- 本地仓库,本地启动
- docker共有habor镜像仓库,不安全
- 公司私有镜像仓库
上一步中编写完成DockerFile文件,在微服务项目中,每一个微服务都是一个java进程,所以每一个java工程都应该有一个DockerFile与之对应,通过docker命令打镜像:
// docker打镜像指令
docker build --no-cache -f ./Dockerfile -7 172.17.242.111:5001/dw2020/dw-trace-ms-msg:1.1.27.0 .打好的镜像现在存放在本地仓库,生产中一般都是从远程共有仓库或者私有仓库中下载镜像启动服务,所以我们在本地打好的镜像还需要推送到远程的私有仓库中:
// 推送本地镜像到远程仓库
docker push 172.17.242.111:5001/dw2020/dw-trace-ms-msg:1.1.27.0
//查看镜像
docker images
//删除镜像
docker rmi 镜像id
//验证镜像是否正确
docker run -it 172.17.242.111:5001/dw2020/dw-trace-ms-msg:1.1.27.0 /bin/bash
//查看运行的镜像
docker ps -adocker一般都是从habor私有仓库下载镜像,所以将本地镜像推送到远程仓库后,还需要配置远程仓库的镜像同步到habor仓库的策略,这样在启动服务的时docker就可以在habor仓库拉取到镜像。
注意:docker在去habor仓库拉取镜像的时候一般需要先登录到habor仓库上,然后才有权限拉取,所以在部署服务的时候需要配置secret密码,配置启动登录habor仓库,否则会拉取镜像失败。
2.2、K8s资源对象(资源选择)
K8S是Kubernetes的全称,官方称其是:
Kubernetes is an open source system for managing containerized applications across multiple hosts. It provides basic mechanisms for deployment, maintenance, and scaling of applications.
用于自动部署、扩展和管理“容器化(containerized)应用程序”的开源系统。
翻译成大白话就是:“K8S是负责自动化运维管理多个Docker程序的集群”。那么问题来了:Docker运行可方便了,为什么要用K8S,它有什么优势?
2.2.1、为什么要有k8s
试想下传统的后端部署办法:把程序包(包括可执行二进制文件、配置文件等)放到服务器上,接着运行启动脚本把程序跑起来,同时启动守护脚本定期检查程序运行状态、必要的话重新拉起程序。
有问题吗?显然有!最大的一个问题在于:**如果服务的请求量上来,已部署的服务响应不过来怎么办?**传统的做法往往是,如果请求量、内存、CPU超过阈值做了告警,运维马上再加几台服务器,部署好服务之后,接入负载均衡来分担已有服务的压力。
问题出现了:从监控告警到部署服务,中间需要人力介入!那么,有没有办法自动完成服务的部署、更新、卸载和扩容、缩容呢?
这,就是K8S要做的事情:自动化运维管理Docker(容器化)程序。
2.2.2、有状态和无状态的区别
有状态应用(Stateful Application)和无状态应用(Stateless Application)是根据应用程序对数据处理方式以及实例间的关系来区分的两种类型:
无状态应用(Stateless Application):
- 数据处理:无状态应用不保存任何与客户端会话相关的持久化数据,每个请求的处理独立于其他请求,且不会依赖于应用上次运行时的状态,多个实例对一个请求的响应结果是一致的。
- 实例关系:无状态应用的所有实例都是可以互换的,它们对于同一服务请求能够提供相同的响应结果,无需知道先前交互的历史信息。
- 扩容缩容:无状态应用可以根据负载需求轻松地进行水平扩展或收缩,因为新创建或销毁的实例不需要继承任何特定状态。
- 调度:Kubernetes中的Deployment通常用于部署无状态应用,它能确保无论哪个Pod被分配到哪个节点上,都能提供相同的服务。
相关的k8s资源有:ReplicaSet、ReplicationController、Deployment等,由于是无状态服务,所以这些控制器创建的pod序号都是随机值。并且在缩容的时候并不会明确缩容某一个pod,而是随机的,因为所有实例得到的返回值都是一样,所以缩容任何一个pod都可以
有状态应用(Stateful Application):
- 数据处理:有状态应用需要维护其内部状态或者与外部存储系统(如数据库、分布式文件系统等)交互以保持数据一致性,这些数据跨越了多个客户端请求或服务实例生命周期, 需要数据存储功能的服务、或者指多线程类型的服务,队列等。(mysql数据库、kafka、zookeeper等)
- 实例关系:有状态应用的实例通常是不对等的,每个实例都有一个唯一的标识,并可能拥有持久化的存储卷。例如,每个实例可能对应数据库集群中的一个节点,具有固定的网络标识和持久数据。
- 扩容缩容:虽然有状态应用也能进行扩容或缩容,但这通常涉及到更为复杂的操作,比如在新增节点时需要初始化特定的数据副本或重新配置集群, 在 Statefulset缩容时删除这个声明将是灾难性的,特别是对于 Statefulset来说,缩容就像减少其 replicas 数值一样简单。基于这个原因,当你需要释放特定的持久卷时,需要手动删除对应的持久卷声明。
- 调度:在Kubernetes中,StatefulSet是用来管理有状态应用的主要资源对象,它保证了Pods具有稳定的持久化存储、有序的启动/终止过程、以及网络标识的一致性(如固定不变的DNS名称)。
相关的k8s资源为:statefulSet,由于是有状态的服务,所以每个pod都有特定的名称和网络标识。比如pod名是由statefulSet名+有序的数字组成(0、1、2..)
StatefulSet 缩容任何时候只会操作 一个 pod 实例,所以有状态应用的缩容不会很迅速。举例来说, 一个分布式存储应用若同时下线多个节点 ,则可能导致其数据丢失 。 比如说一个数据项副本数设置为 2 的数据存储应用, 若 同时有两个节点下线,一份数据记录就会丢失,如果它正好保存在这两个节点上 。 若缩容是线性的 ,则分布式存储应用就有时间把丢失的副本复制到其他节点 ,保证数据不会丢失。
2.2.3、资源对象
部署一个jar通常需要考虑高可用,负载均衡,存储,配置等等。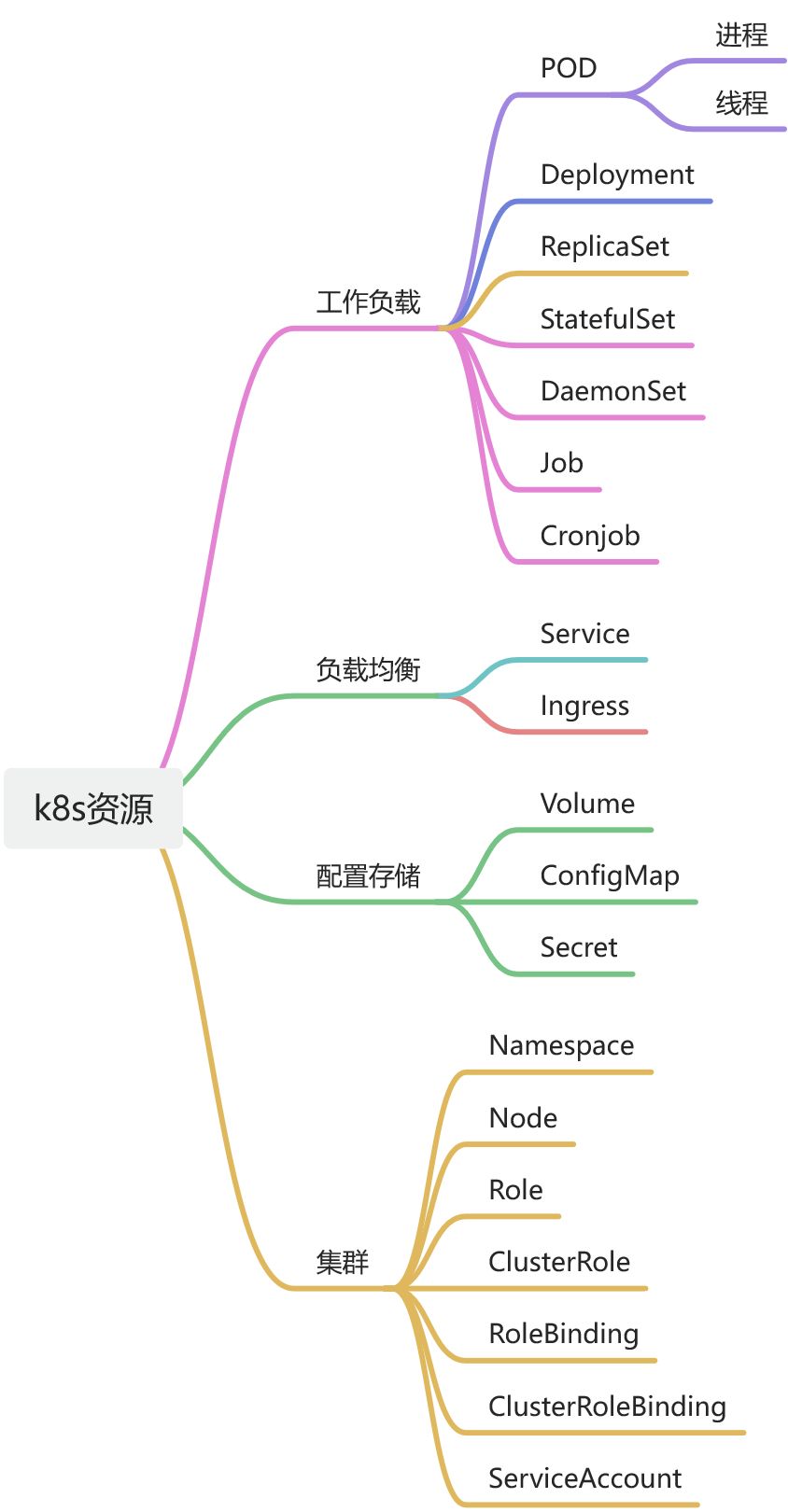
参考:
Pod
不同应用适用资源类型说明:
| 应用类型 | K8S资源类型 | 备注 |
|---|---|---|
| JOB、批处理 | Jobs CronJob | |
| 长时间运行的无状态应用 | Deployment DeploymentConfig | DeploymentConfig是OpenShift特有的 |
| 长时间运行的无状态应用- 高可用 | Deployment里加ReplicaSet字段 | |
| 需要在每个节点上运行的应用 | DaemonSet | |
| 有状态应用 | StatefulSet | |
| 复杂的应用, 或需要全生命周期管理的应用 | Operator | |
应用部署结构:
2.3、helm部署应用服务(部署升级)
helm是k8s中管理服务的工具,类似于服务器上的yum工具,可以快速的帮助我们部署应用和管理版本操作,helm官网;
Helm
2.3.1、编写helm应用配置
helm的目录结构:
- templates:存放资源,k8s中所有资源的定义都是以yaml文件的形式放在templates目录下面,可以定义pod,deployment,service,ingress等各种资源来配置服务。
- values:全局变量引用,定义在values中的变量,可以再helm中所有的地方进行引用,也可以动态的修改values中的变量,比如可以配置不同环境的数据库ip,kafka ip等。
- Chart:charts代表当前的一个helm,管理这服务的版本号,可以通过配置不同的版本号进行服务变更。
- files:文件存放区,可以存放应用需要加载的配置,比如yaml,properties,log4j等配置文件。
- bin:存放启动应用和卸载应用的脚本。
- charts:存放子项目,可以将多个项目放在一个helm中部署,charts中可以存放多个完整的helm目录。
2.3.2、helm部署案例
2.3.2.1、Deployment定义
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ include "dw-trace-ms-msg.fullname" . }} - 应用名字
labels:
{{- include "dw-trace-ms-msg.labels" . | nindent 4 }} -应用标签
spec:
replicas: {{ .Values.replicaCount }} -应用副本数
selector:
matchLabels:
{{- include "dw-trace-ms-msg.selectorLabels" . | nindent 6 }}
# serviceName: {{ .Values.service.name }}
template: - 容器模板定义
metadata:
{{- with .Values.podAnnotations }}
annotations:
{{- toYaml . | nindent 8 }}
{{- end }}
labels:
{{- include "dw-trace-ms-msg.selectorLabels" . | nindent 8 }}
spec:
{{- with .Values.imagePullSecrets }}
imagePullSecrets: -- 拉取镜像保密字典
{{- toYaml . | nindent 8 }}
{{- end }}
serviceAccountName: {{ include "dw-trace-ms-msg.serviceAccountName" . }}
securityContext:
{{- toYaml .Values.podSecurityContext | nindent 8 }}
containers: --声明容器
- name: {{ .Chart.Name }}
securityContext:
{{- toYaml .Values.securityContext | nindent 12 }}
image: "{{ tpl (printf "{{ .Values.%s.image.repository }}" .Values.global.releaseEnv) . }}/dw2020/{{ .Chart.Name }}:{{ .Values.image.tag | default .Chart.AppVersion }}"
imagePullPolicy: {{ .Values.image.pullPolicy }}
resources: -- 资源限制
limits:
cpu: {{ .Values.resources.limits.cpu }}
memory: {{ .Values.resources.limits.memory }}
requests:
cpu: {{ .Values.resources.requests.cpu }}
memory: {{ .Values.resources.requests.memory }}
volumeMounts: -- 持久全声明
- name: conf-files
mountPath: /opt/trace-ms-msg-deploy/trace-ms-msg-1.1.27.0/config/
readOnly: true
- name: dw-trace-log
mountPath: /opt/trace-ms-msg-deploy/trace-ms-msg-1.1.27.0/logs
ports:
- name: http
containerPort: 19191
protocol: TCP
livenessProbe: -- 存活探针
initialDelaySeconds: 10
periodSeconds: 30
timeoutSeconds: 30
tcpSocket:
port: 19191
readinessProbe: -- 就绪探针
initialDelaySeconds: 10
periodSeconds: 30
timeoutSeconds: 30
tcpSocket:
port: 19191
volumes: --持久全挂载
- name: conf-files
configMap:
name: {{ .Chart.Name }}-configmap
defaultMode: 0600
- name: dw-trace-log
persistentVolumeClaim:
claimName: {{ lower .Values.global.releaseEnv }}-ncdw-mdp-f-scheduler-log-pvc012.3.2.2、PVC(PersistentVolumeClaim)和PV(PersistentVolume)
apiVersion: v1
kind: PersistentVolumeClaim -- 持久全声明
metadata:
name: {{ lower .Values.global.releaseEnv }}-ncdw-mdp-f-scheduler-log-pvc01 -- 持久全名字
spec:
accessModes:
- ReadWriteMany
volumeMode: Filesystem
resources:
requests:
storage: {{ tpl (printf "{{ .Values.%s.scheduler.logpvc01 }}" .Values.global.releaseEnv) . }}PV(PersistentVolume )
- PV是对K8S存储资源的抽象,PV一般由运维人员创建和配置,供容器申请使用。
- 没有PV之前,服务器的磁盘没有分区的概念,有了PV之后,相当于通过PV对服务器的磁盘进行分区。
PVC(PersistentVolumeClaim)
- PVC 是Pod对存储资源的一个申请,主要包括存储空间申请、访问模式等。创建PV后,Pod就可以通过PVC向PV申请磁盘空间了。类似于某个应用程序向操作系统的D盘申请1G的使用空间。
- PVC 创建成功之后,Pod 就可以以存储卷(Volume)的方式使用 PVC 的存储资源了。Pod 在使用 PVC 时必须与PVC在同一个Namespace下。
PV / PVC的关系
- PV相当于对磁盘的分区,PVC相当于APP(应用程序)向某个分区申请多少空间。pv使得不同应用的持久化盘得到隔离,某一个pv存储满后并不会影响其他程序。
- 一旦 PV 与PVC绑定,Pod就可以使用这个 PVC 了。如果在系统中没有满足 PVC 要求的 PV,PVC则一直处于 Pending 状态,直到系统里产生了一个合适的 PV。
StorageClass概念
K8S有两种存储资源的供应模式:静态模式和动态模式,资源供应的最终目的就是将适合的PV与PVC绑定:
- 静态模式:管理员预先创建许多各种各样的PV,等待PVC申请使用,必须创建指定大小的pv,如果应用申请一块存储,但是没有满足的pv,应用会一直处于挂起状态。
- 动态模式:管理员无须预先创建PV,而是通过StorageClass自动完成PV的创建以及与PVC的绑定。
StorageClass就是动态模式,根据PVC的需求动态创建合适的PV资源,从而实现存储卷的按需创建,pv和pvc一般是一对一模式。
pv和pvc动态绑定关系图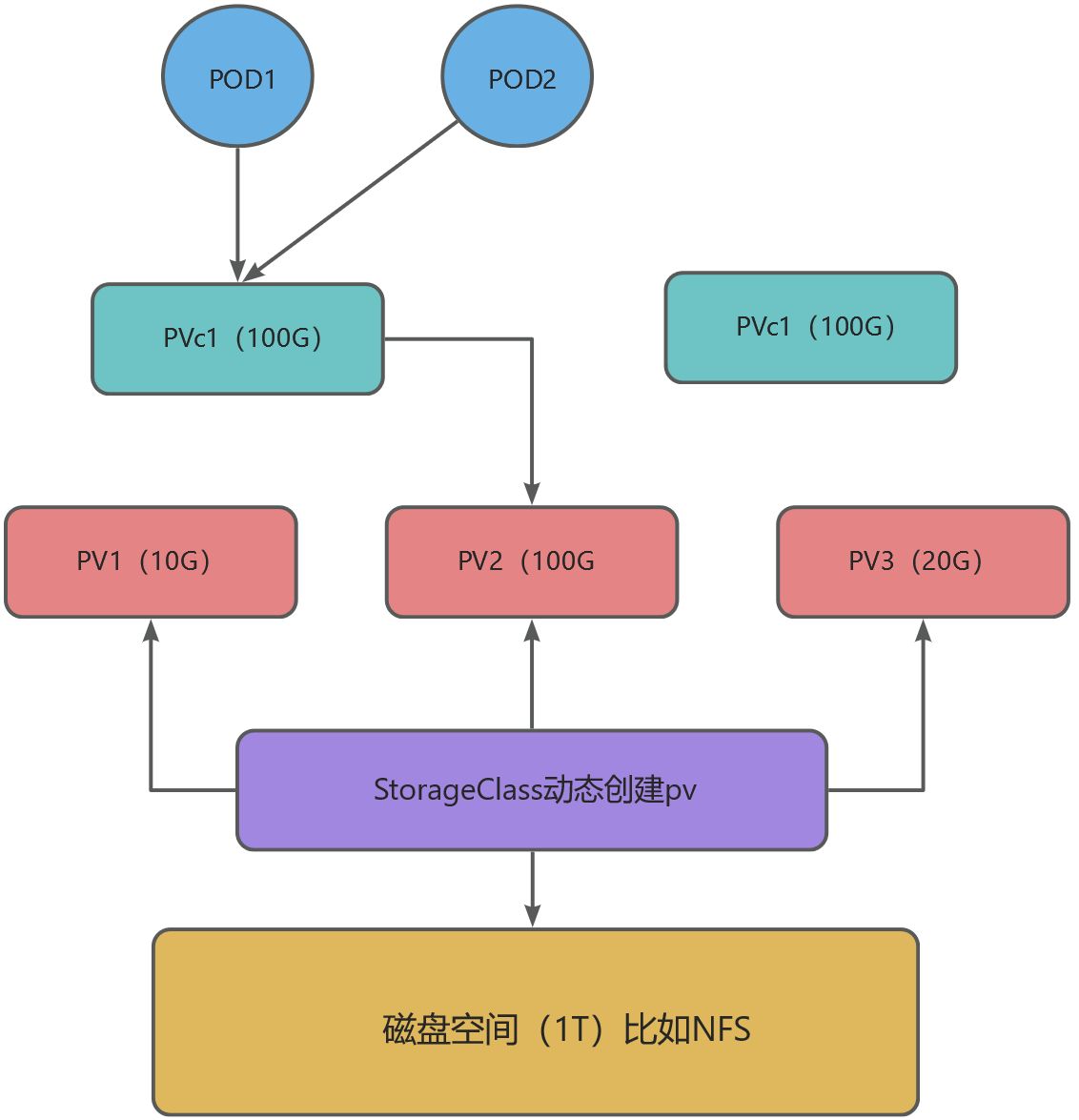
配置文件,日志文件一般都需要配置持久化券。
2.3.2.3、Configmap
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Chart.Name }}-configmap
data: -- 配置文件数据
{{- range $path, $_ := .Files.Glob "files/conf/*.*" }}
{{ base $path | indent 2 }}: |-
{{ tpl ($.Files.Get $path) $ | indent 4 }}
{{- end -}}2.3.2.4、Service
apiVersion: v1
kind: Service
metadata:
name: {{ include "dw-trace-ms-msg.fullname" . }}
labels:
{{- include "dw-trace-ms-msg.labels" . | nindent 4 }}
spec:
type: {{ .Values.service.type }}
ports:
- port: {{ .Values.service.port }}
targetPort: http
protocol: TCP
name: http
selector:
{{- include "dw-trace-ms-msg.selectorLabels" . | nindent 4 }} -- 选择代理的podport:service端口;
targetport:容器端口。
2.3.2.5、Ingress
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: dw-trace-ms-msg-ingress
namespace: "{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}"
spec:
# 配置安全连接密钥
tls:
- hosts:
- {{ tpl (printf "{{ .Values.%s.ingress.host }}" .Values.global.releaseEnv) . }}.cfets.com
secretName: dw-trace-tls-secret
rules:
- host: {{ tpl (printf "{{ .Values.%s.ingress.host }}" .Values.global.releaseEnv) . }}.cfets.com
http:
paths: -- 配置域名前缀
- path: "/updatePresentRate"
pathType: "Prefix"
backend:
service:
name: {{ include "dw-trace-ms-msg.fullname" . }}
port:
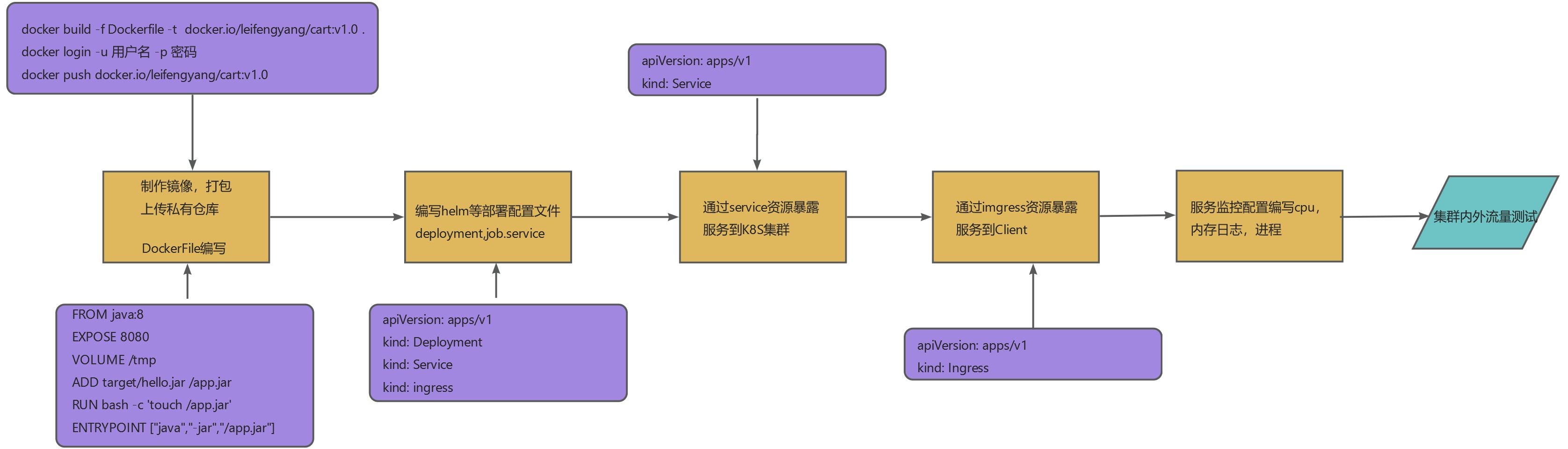
number: 19191 -- 域名映射端口2.3.2.6、云服务部署流程
3、部署过程中遇到问题
3.1、应用到人大金仓的tcp连接被reset
3.1.1、现象
环境:生产
定时任务查询数据库被卡住(执行一个很简单的sql查询,没有响应),导致定时任务执行时间超时或者失败,从日志中看每隔一段时间就会去尝试重新建立连接,直到建立成功为止,才会执行查询。
从数据库端查看tcp连接发现物理连接已经断开,但是数据库连接池中的逻辑连接仍然存在。
3.1.2、原因
其一:worker节点的tcp_timeout_established默认是86400s,master节点的tcp_timeout_established=180s,默认值432000被修改,容器云服务器和数据库服务器之间的物理连接只能够保持3分钟然后断开,但是应用里面数据库连接池中的逻辑连接仍然存在,应用认为连接连接池中的连接是正常的,所以在执行查询的时候被卡主。
其二:druid数据库连接池配置中开启了keepAlive = true参数配置,minEvicatableIdleTimeMills参数配置为5小时,即5小时才探活一次,导致服务器之间的物理连接断开。
alb(Application Load Balance),K8s中实现负载均衡的一个服务,Pod重启后会修改内核参数tcp_timeout_established,厂商那边给出的解决方案是升级灵雀云版本可以彻底解决。
3.1.3、解决
- 当前解决方案是在我们部署的服务中,设置污点,即不允许服务在master节点上启动,这样所有的服务都在worker节点上启动即可避免这个问题。
- 修改minEvicatableIdleTimeMills = 120000ms,2分钟做一次探活检测,保证物理连接不会断开。
另外为什么alb重启会将tcp_timeout_established设置为180S,改变其默认值?
当并发量很高的情况下,如果这个值设置的很大,会导致conntrack过多,导致新的包无法建立连接。所以alb重启的时候会重新这个值。
3.2、启动容器时docker拉取镜像失败
3.2.1、现象
环境:uatc套环境第一次升级
典型的场景是k8s出现dockerpullimageFailed事件,所有的服务都无法启动,一直处于pending状态。
3.2.2、原因
出现这种情况需要从两个方面排查:
- 首先是镜像的版本号,可能有多个镜像版本,当前拉去的镜像版本并不存在。
- 忘记配置在拉去镜像的时候login 操作,docker从habor上拉取镜像的时候,首先需要登录habor,然后才能拉取镜像。
3.2.3、解决
两种方案:
- 在部署服务的yaml文件中配置secret保密字典,这样每次在部署的时候,拉取镜像之前k8s会自动登录habor后再pull。
- 给serviceaccount授权secret,然后将服务部署在授权的serviceaccount下面,yaml脚本中不再需要配置secret,默认拥有拉取镜像的权限。
3.3、应用出现OOM
默认情况下 Docker 运行的容器对宿主机的物理内存/swap交换内存的使用是无限制的
部署在云上的应用,一般需要设置容器运行最大的可用内存,所以在创建容器的时候,尽量根据自己的业务场景评估一下所需内存,然后设置request和limit参数。
启动进程的时候,一般会设置堆的最大和最小内存,启动的最小内存和最大内存一般不要超过容器的最大内存,当进程所需的内存超过容器内存就会报OOM。
厂务应用内存需求一般比较稳定,特别需要注意数据处理类服务,缓存的大小,如果某一天数据量过大,需求缓存过多会导致OOM。
resources:
limits:
cpu: 2c
memory: 4Gi
requests:
cpu: 4c
memory: 8Gi3.4、持久化磁盘爆满导致容器无法启动
3.4.1、现象
环境:st环境
启动容器时候容器报FailedMount,事件,持久化目录无法读取和写入,容器无法启动。st环境中产生了一个gc文件非常大,导致持久化盘占满。
需要对持久化盘进行及时的清理和监控,通过日志框架或者定时任务定时删除多余的日志文件。
3.4.2、原因及解决
原因:
服务没有配置持久化目录的清理策略,导致持久化目录中磁盘空间占满,容器无法挂载导致启动失败。
解决:
部署的应用一般要设置日志或者数据的自动清理策略,一般保留最近30天的数据。需要注意的是如果使用log4j等日志框架,因为容器每次启动后pod名字都会变化,所以如果日志文件的名字中带有主机的名字,框架配置的30天策略将会失效,即上一次启动pod产生的日志文件无法被清理,需要通过定时脚本删除日志。
灵雀云全局日志策略默认是30天,最好针对项目评估日志保留天数,配置项目策略。
3.5、监控配置
灵雀云上的服务通过平台提供的普罗米修斯组件进行监控,但是运行部规定监控的创建必须自动化进行,所以在开发完部署脚本后,需要开发监控脚本,通常需要对一下几个资源进行监控:
- 工作负载内存使用率
- 容器内存使用率
- 工作负载cpu使用率
- 容器运行事件
- 日志监控
- 部署监控
- 持久化空间占用率监控。
- pod个数监控
通常需要通过yaml文件配置以上资源的监控,监控的时效性和准确性与具体的平台有关,目前中台遇到过误报事件。
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
annotations:
alert.cpaas.io/notifications: '[{ "name": "whjyzx-alert","namespace": "cpaas-system" }]'
alert.cpaas.io/rules.version: '9'
cpaas.io/display-name: ap-lq-alert-dw-trace-ms-msg
labels:
alert.cpaas.io/cluster: "{{ tpl (printf "{{ .Values.%s.alert.clusterName }}" .Values.global.releaseEnv) . }}"
alert.cpaas.io/kind: Deployment
alert.cpaas.io/name: dw-trace-ms-msg
alert.cpaas.io/namespace: "{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}"
alert.cpaas.io/owner: System
alert.cpaas.io/project: "{{ tpl (printf "{{ .Values.%s.alert.project }}" .Values.global.releaseEnv) . }}"
prometheus: kube-prometheus
rule.cpaas.io/cluster: "{{ tpl (printf "{{ .Values.%s.alert.clusterName }}" .Values.global.releaseEnv) . }}"
rule.cpaas.io/name: ap-lq-alert-dw-trace-ms-msg
rule.cpaas.io/namespace: "{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}"
name: ap-lq-alert-dw-trace-ms-msg
namespace: "{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}"
spec:
groups:
- name: general
rules:
- alert: workload.cpu.utilization
annotations:
alert_notifications: '[{"name":"whjyzx-alert","namespace":"cpaas-system"}]'
expr: 'avg (avg by(namespace,pod,container) (container_cpu_usage_seconds_total_irate5m{namespace="{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}",pod=~"dw-trace-ms-msg-[a-z0-9]{7,10}-[a-z0-9]{5}",container!="",container!="POD"}) / avg by(namespace,pod,container) (kube_pod_container_resource_limits_cpu_cores{namespace="{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}",pod=~"dw-trace-ms-msg-[a-z0-9]{7,10}-[a-z0-9]{5}"}))>0.9'
for: 180s
labels:
alert_cluster: "{{ tpl (printf "{{ .Values.%s.alert.clusterName }}" .Values.global.releaseEnv) . }}"
alert_indicator: workload.cpu.utilization
alert_indicator_aggregate_range: '0'
alert_indicator_blackbox_name: ""
alert_indicator_comparison: ">"
alert_indicator_query: ""
alert_indicator_threshold: '0.9'
alert_indicator_unit: '%'
alert_involved_object_kind: Deployment
alert_involved_object_name: dw-trace-ms-msg
alert_involved_object_namespace: "{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}"
alert_name: workload.cpu.utilization
alert_namespace: "{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}"
alert_project: "{{ tpl (printf "{{ .Values.%s.alert.project }}" .Values.global.releaseEnv) . }}"
alert_resource: ap-lq-alert-dw-trace-ms-msg
severity: High
- alert: workload.pod.container.memory.utilization
annotations:
alert_notifications: '[{"name":"whjyzx-alert","namespace":"cpaas-system"}]'
expr: 'avg by (pod, container) (avg by(namespace,pod,container) (container_memory_working_set_bytes{container!="POD",container!="",namespace="{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}",pod=~"dw-trace-ms-msg-[a-z0-9]{7,10}-[a-z0-9]{5}"}) / avg by(namespace,pod,container) (kube_pod_container_resource_limits_memory_bytes{namespace="{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}",pod=~"dw-trace-ms-msg-[a-z0-9]{7,10}-[a-z0-9]{5}"}))>0.85'
for: 180s
labels:
alert_cluster: "{{ tpl (printf "{{ .Values.%s.alert.clusterName }}" .Values.global.releaseEnv) . }}"
alert_indicator: workload.pod.container.memory.utilization
alert_indicator_aggregate_range: '0'
alert_indicator_blackbox_name: ""
alert_indicator_comparison: '>'
alert_indicator_query: ""
alert_indicator_threshold: '0.85'
alert_indicator_unit: '%'
alert_involved_object_kind: Deployment
alert_involved_object_name: dw-trace-ms-msg
alert_involved_object_namespace: "{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}"
alert_name: workload.pod.container.memory.utilization
alert_namespace: "{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}"
alert_project: "{{ tpl (printf "{{ .Values.%s.alert.project }}" .Values.global.releaseEnv) . }}"
alert_resource: ap-lq-alert-dw-trace-ms-msg
severity: High
- alert: workload.memory.utilization
annotations:
alert_notifications: '[{"name":"whjyzx-alert","namespace":"cpaas-system"}]'
expr: 'avg (avg by(namespace,pod,container) (container_memory_working_set_bytes{container!="POD",container!="",namespace="{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}",pod=~"dw-trace-ms-msg-[a-z0-9]{7,10}-[a-z0-9]{5}"}) / avg by(namespace,pod,container) (kube_pod_container_resource_limits_memory_bytes{namespace="{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}",pod=~"dw-trace-ms-msg-[a-z0-9]{7,10}-[a-z0-9]{5}"}))>0.9'
for: 180s
labels:
alert_cluster: "{{ tpl (printf "{{ .Values.%s.alert.clusterName }}" .Values.global.releaseEnv) . }}"
alert_indicator: workload.memory.utilization
alert_indicator_aggregate_range: '0'
alert_indicator_blackbox_name: ""
alert_indicator_comparison: '>'
alert_indicator_query: ""
alert_indicator_threshold: '0.9'
alert_indicator_unit: '%'
alert_involved_object_kind: Deployment
alert_involved_object_name: dw-trace-ms-msg
alert_involved_object_namespace: "{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}"
alert_name: workload.memory.utilization
alert_namespace: "{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}"
alert_project: "{{ tpl (printf "{{ .Values.%s.alert.project }}" .Values.global.releaseEnv) . }}"
alert_resource: ap-lq-alert-dw-trace-ms-msg
severity: High
- alert: workload.event.reason.count
annotations:
alert_notifications: '[{"name":"whjyzx-alert","namespace":"cpaas-system"}]'
expr: 'round(avg(rate(workload_event_reason_count{cluster_name="{{ tpl (printf "{{ .Values.%s.alert.clusterName }}" .Values.global.releaseEnv) . }}",kind="Deployment",name="dw-trace-ms-msg",namespace="{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}",query="BackOff Failed"}[300s])*300))>3'
for: 15s
labels:
alert_cluster: "{{ tpl (printf "{{ .Values.%s.alert.clusterName }}" .Values.global.releaseEnv) . }}"
alert_indicator: workload.event.reason.count
alert_indicator_aggregate_range: '300'
alert_indicator_blackbox_name: ""
alert_indicator_comparison: '>'
alert_indicator_query: 'BackOff Failed'
alert_indicator_threshold: '3'
alert_indicator_unit: '条'
alert_involved_object_kind: Deployment
alert_involved_object_name: dw-trace-ms-msg
alert_involved_object_namespace: "{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}"
alert_name: workload.event.reason.count
alert_namespace: "{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}"
alert_project: "{{ tpl (printf "{{ .Values.%s.alert.project }}" .Values.global.releaseEnv) . }}"
alert_resource: ap-lq-alert-dw-trace-ms-msg
severity: High
- alert: workload.pod.status.phase.running
annotations:
alert_notifications: '[{"name":"whjyzx-alert","namespace":"cpaas-system"}]'
expr: '(count(min by(pod)(kube_pod_container_status_ready{namespace="{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}",pod=~"dw-trace-ms-msg-[a-z0-9]{7,10}-[a-z0-9]{5}"}) ==1) or on() vector(0))<2'
for: 180s
labels:
alert_cluster: "{{ tpl (printf "{{ .Values.%s.alert.clusterName }}" .Values.global.releaseEnv) . }}"
alert_indicator: workload.pod.status.phase.running
alert_indicator_aggregate_range: '0'
alert_indicator_blackbox_name: ""
alert_indicator_comparison: '<'
alert_indicator_query: ""
alert_indicator_threshold: '2'
alert_indicator_unit: ""
alert_involved_object_kind: Deployment
alert_involved_object_name: dw-trace-ms-msg
alert_involved_object_namespace: "{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}"
alert_name: workload.pod.status.phase.running
alert_namespace: "{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}"
alert_project: "{{ tpl (printf "{{ .Values.%s.alert.project }}" .Values.global.releaseEnv) . }}"
alert_resource: ap-lq-alert-dw-trace-ms-msg
severity: High
- alert: workload.log.keyword.count
annotations:
alert_notifications: '[{ "name": "whjyzx-alert","namespace": "cpaas-system" }]'
expr: 'round(avg(rate(workload_log_keyword_count{cluster_name="{{ tpl (printf "{{ .Values.%s.alert.clusterName }}" .Values.global.releaseEnv) . }}",kind=~"(?i:(Deployment))",name="dw-trace-ms-msg",namespace="{{ tpl (printf "{{ .Values.%s.alert.clusterName }}" .Values.global.releaseEnv) . }}",query="representative interest rate bond list initialization failed"}[180s])*180))>=0'
for: 15s
labels:
alert_cluster: "{{ tpl (printf "{{ .Values.%s.alert.clusterName }}" .Values.global.releaseEnv) . }}"
alert_indicator: workload.log.keyword.count
alert_indicator_aggregate_range: '180'
alert_indicator_blackbox_name:
alert_indicator_comparison: '>='
alert_indicator_query: 'representative interest rate bond list initialization failed'
alert_indicator_threshold: '0'
alert_indicator_unit: '条'
alert_involved_object_kind: Deployment
alert_involved_object_name: dw-trace-ms-msg
alert_involved_object_namespace: "{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}"
alert_name: workload.log.keyword.count
alert_namespace: "{{ tpl (printf "{{ .Values.%s.alert.namespace }}" .Values.global.releaseEnv) . }}"
alert_project: "{{ tpl (printf "{{ .Values.%s.alert.project }}" .Values.global.releaseEnv) . }}"
alert_resource: ap-lq-alert-dw-trace
severity: High3.6、helm中字符解析
环境:new-uat
new-uatc环境中遇到一个字符解析失败的案例:
{{ tpl (printf "{{ .Values.%s.alert.clusterName }}" .Values.global.releaseEnv) . }}
Values文件内容如下:
global:
releaseEnv:
ST:
UATC:
NEW-UAT:
SIM_WG字符串解析:
xxx:%s
xxx-xxx:%s-%s
xxx_xxx:%s_%s
helm语法检查很严格,所以在开发完成部署脚本后,可以使用工具对脚本进行渲染输出:
helm template file
helm install service --dry-run3.7、正确使用pvc
Pvc的全称是PersistentVolumnClaim(声明持久卷),如果将部署文件和pvc申请文件放在一个helm中,在helm升级和卸载的时候,会将pvc也一并卸载,之前落盘的数据就会丢失,所以建议使用两个helm或者pvc单独创建,保证卸载服务的时候持久化卷不被卸载。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: {{ lower .Values.global.releaseEnv }}-ncdw-mdp-f-scheduler-log-pvc01
spec:
accessModes:
- ReadWriteMany
volumeMode: Filesystem
storageClassName: cephfs -- 建议这个字段不指定,使用默认值
resources:
requests:
storage: {{ tpl (printf "{{ .Values.%s.scheduler.logpvc01 }}" .Values.global.releaseEnv) . }}模拟和生产的pvc名字不同,st和uat是一样的,因为历史遗留原因,灵雀云没有统一修复,所以在申请pvc的时候建议不要指定名字,否则会创建资源失败;
storageClassName:cephfs :默认不要指定,但是也要关注下具体的平台,如果不指定的情况下有没有默认的storageClassName。
3.8、正确使用探针
启动探针(Startup Probe):用于检测容器是否已经启动,启动探针在容器启动时运行,而不会周期性地运行。
存活探针(Liveness Probe):用于检测容器是否处于正常运行状态。如果容器未响应探针,则 Kubernetes 认为容器已经崩溃,并将重启该容器。
就绪探针(Readiness Probe):就绪探针是一种用于检测容器是否已准备好接收流量的机制,允许您在容器启动后,等待容器内应用程序或服务完全初始化和准备就绪之后再将流量导入容器,当启动探针执行完成后,开始执行就绪探针,如果容器未响应就绪探针,则 Kubernetes 认为容器尚未准备好,并将从 Service 端点中删除该容器。
合理配置存活探针和启动探针的时间,如果设置时间太短,会导致pod无限重启。
评估应用启动时间,设置启动探针工作时间,存活探针时间要大于启动探针时间。
3.9、重启策略,镜像拉取策略
JOB:重启策略有三种:OnFailure,Never,Always
拉取镜像策略:
- Always:
如果容器的imagePullPolicy设置为Always,每次创建Pod或者重启容器时,kubelet都会尝试从镜像仓库拉取最新的镜像版本。这对于使用 latest 标签或者希望总是获取最新镜像内容的场景非常有用。 - IfNotPresent(默认值):
当imagePullPolicy设置为IfNotPresent时,如果本地节点上已经存在该镜像,则不会尝试从镜像仓库拉取镜像;仅当本地不存在该镜像时,kubelet才会去远程仓库拉取镜像。对于具有明确版本标签(如v1.0)的镜像,通常建议使用此策略以避免不必要的镜像下载。 - Never:
如果设置为Never,无论本地是否存在镜像,kubelet都不会尝试从远程仓库拉取镜像,而是始终使用本地已有的镜像。这种策略适用于不希望自动升级镜像版本且确保始终使用固定镜像的情况。
Deployment更新策略:
Kubernetes中的Deployment对象使用了一种叫做"滚动更新"的策略来管理Pod的更新。这个更新策略是通过一系列的步骤进行的,每个步骤都会替换一定百分比的旧Pod,直到所有的Pod都被替换完毕。
在Deployment的定义中,你可以指定以下几种重启策略:
- Recreate:这是最简单的重启策略。当你将Pod模板中的某个字段更新时,旧的Pod会被删除,然后根据新的模板创建新的Pod。在这个过程中,服务是不可用的。
- RollingUpdate(默认):这是滚动更新的策略,它会逐个替换旧的Pod。在更新过程中,服务是可用的,并且可以通过设置maxUnavailable和maxSurge参数来控制更新的过程。
服务在滚动更新时,deployment控制器的目的是:给旧版本(old_rs)副本数减少至0、给新版本(new_rs)副本数量增至期望值(replicas)。大家在使用时,通常容易忽视控制速率的特性,以下是kubernetes提供的两个参数:
- maxUnavailable:和期望ready的副本数比,不可用副本数最大比例(或最大值),这个值越小,越能保证服务稳定,更新越平滑;
- maxSurge:和期望ready的副本数比,超过期望副本数最大比例(或最大值),这个值调的越大,副本更新速度越快。
数值
- maxUnavailable: [0, 副本数]
- maxSurge: [0, 副本数]
注意:两者不能同时为0。
比例
- maxUnavailable: [0%, 100%] 向下取整,比如10个副本,5%的话==0.5个,但计算按照0个;
- maxSurge: [0%, 100%] 向上取整,比如10个副本,5%的话==0.5个,但计算按照1个;
注意:两者不能同时为0。
建议配置 - maxUnavailable == 0
- maxSurge == 1
这是我们生产环境提供给用户的默认配置。即“一上一下,先上后下”最平滑原则:1个新版本pod ready(结合readiness)后,才销毁旧版本pod。此配置适用场景是平滑更新、保证服务平稳,但也有缺点,就是“太慢”了。
3.10、日志爆满
环境:生产
生产部署的服务日志级别一般设置大于等于info级别,不能设置为debug级别,debug级别可能导致打印日志过多撑爆容器云日志采集服务器。
日志级别:debug
日志策略:默认全局策略,保留30天,尽量评估项目日志量,配置项目策略。
3.11、资源获取api使用
通过jdk原生包后去cpu核心数和内存时候,部分api返回的资源是主机的资源数,并不是当前服务所在pod的资源数,需要使用docker api获取容器内资源数量。
数据处理应用目前没有使用到获取底层资源api。
3.12、进程和定时任务(Task)监控
环境:生产环境
进程假死的情况,定时任务监控。
定时任务监控的场景是任务跑的时间过长,任务卡住等场景:
- 在其他服务器上配置定时任务,定时去扫描定时任务的执行时间,如果发现超时的定时任务,就可以发送http请求将任务杀掉,然后重跑任务。
进程假死:
服务程序假死具有以下特征:
- 程序对请求没有任何响应;
- 程序请求时没有任何日志输出;
- 程序进程存在,通过jps或者ps查看进程,可以看到服务进程存在;
造成假死的可能原因
- java线程出现死锁,或所有线程被阻塞;
- 数据库连接池中的连接耗尽,导致获取数据库连接时永久等待;
- 出现了内存泄漏导致了OutOfMemory,内存空间不足导致分配内存空间持续失败;服务器的可用内存足够,但是分配给jvm的内存被耗尽的情况,容易出现这种情况;
- 服务程序运行过程中替换了jar包,但是没有进行重启服务,这属于不按规则操作引起的问题;
- 磁盘空间满,导致需要写数据的地方全部失败;
- 线程池满,无法分配更多的线程来处理请求,通常是因为线程被大量阻塞在某个请求上;