
SparkAQESkewedJoin优化指南
Spark AQE SkewedJoin优化指南
写在前面
如果你没有兴趣/时间阅读全文,那么可以先试着设置以下几个参数:
- set spark.sql.adaptive.skewedJoin.enabled=true;
- set spark.sql.adaptive.skewedJoinWithAgg.enabled=true,
- set spark.sql.adaptive.multipleSkewedJoin.enablled=true
- set spark.sql.adaptive.allowBroadcastExchange.enabled=true
- set spark.sql.adaptive.forceOptimizeSkewedJo∈=true
- set spark.sql.adaptive.multipleSkewedJoinWithAgg0rWin.enabled=true
- set spark.sql.adaptive.skewedJoinSupportUnion.enabled=true
提醒三点
- spark.shuffle.highlyCompressedMapStatusThreshold(默认5000)需要大于等于spark.sql.adaptive.maxNumPostShufflePartitions(设置相等即可,默认2000),否则AQE SkewedJoin可能无法生效。
- spark.sql.adaptive.maxNumPostShufflePartitions 设置过高(例如超过2w),会增加driver cpu的压力,可能出现executor心跳注册超时的可能,建议同时提高driver的内存和cpu个数。
- 倾斜非常严重,被拆分后倾斜仍然很严重,可能是shuffle 分布统计精度太低,需要降低spark.shuffle.accurateBlockThreshold,默认为100M,可按需降低(例如改成4M或1M)。
- 需要注意的是,降低该参数会增加Driver内存的压力(统计数据更加精确),为防止出现Driver OOM等问题,建议同时提高driver的内存和cpu个数。
PS:如果此时,还是无法解决你的数据倾斜问题,请移至目Spark AE SkewedJoin优化指南
如何看参数生效
打开spark作业链接,点击SQLTag,查看作业执行计划图,可见执行图中出现一个SortMergeJoin/ShuffledHashJoin有(skew=true)的标志

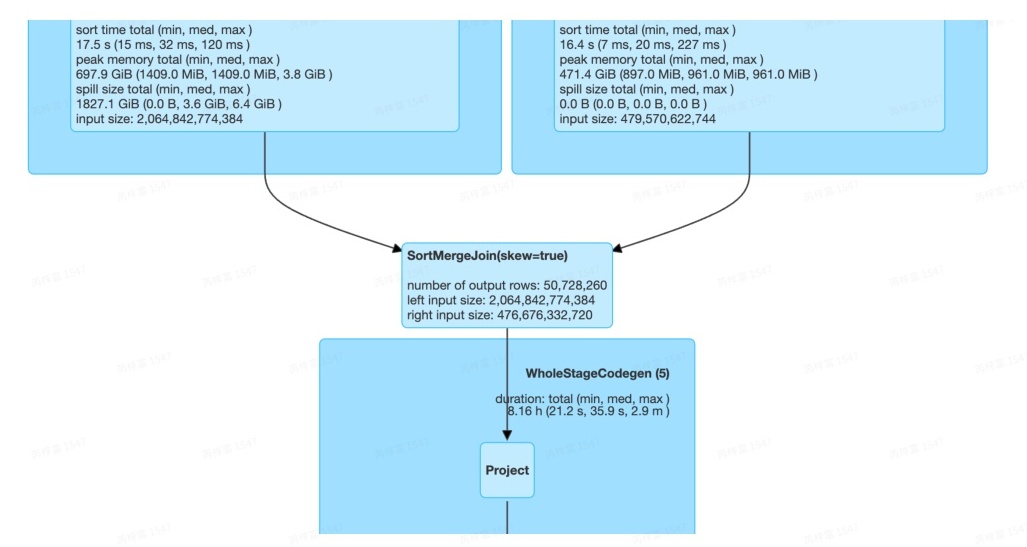
AQE只有在执行到倾斜Join所在的Stage时才会修改执行图,所以没有执行到倾斜Join所在的Stage时,不会观察到上述变化。
倾斜优化未生效该怎么办
- 设置 spark.shuffle.highlyCompressedMapStatusThreshold 与spark.sql.adaptive.maxNumPostShufflePartitions 相等即可。
- 提高统计数据精确度:set spark.shuffle.accurateBlockThreshold=1048576
- 查看sqlplan,如果在sql plan中发现有BucketUnion节点,如下图

加上参数:set spark.sql.bucket.union.enable=false
PS:如果上述参数都加上了,倾斜优化还是没有生效,大概率是JoinType与倾斜侧不同方向,例如Left Join,倾斜侧为右侧,此时,无解。
倾斜优化效果不明显怎么办
设置 spark.shuffle.highlyCompressedMapStatusThreshold 与spark.sql.adaptive.maxNumPostShufflePartitions 相等即可。
提高统计数据精确度:set spark.shuffle.accurateBlockThreshold=1048576;
调整倾斜判断阈值:set spark.sql.adaptive.skewedPartitionFact
何为数据倾斜
何谓数据倾斜?数据倾斜指的是,并行处理的数据集中,某一部分(如Spark的一个Partition)的数据显著多于其它部分,从而使得该部分的处理速度成为整个数据集处理的瓶颈。
造成数据倾斜的原因有很多,其中一个场景是一张表中某几个固定key的记录条数特别多,导致在做SortMergeJoin的时候,同-key的大量数据被一个task执行,导致这个task执行耗时过长。
如何发现数据倾斜
如果SortMergeJoin所在的Stage运行时间存在异常现象(如运行时间较数据量明显不符,或者并行度非常低),在Spark UI的Stage页面,可以看到Stage运行阶段的Metrics统计。
Summary Metrics for 167 Completed Tasks
| Metric(percentile) | 25th | Median | 75t | 90th | 95th | 99th | Max | |
|---|---|---|---|---|---|---|---|---|
| Duration | 0ms | 5 | 7% | 115 | 16% | 19% | 19 min | 1.6h |
| GC Tie | 0 ms | 16 ms | 0.3s | 0.85 | 2 | 2 | 종동 | 47% |
| Shuffe Sorial Boad Time | 0.ms | 13.% | 39.5 | 1.9 min | 3.1 min | 3.4.min | 6.1 min | 8.0.min |
| Shuffe Read Size/Records | 0.08/0 | 41.3 MB/3148241 | 52.1 MB/3920604 | 57.0 MB/4343403 | 59.3 MB/4571128 | 67.8 MB/4682142 | 1762.8 MB/152338314 | 10.3 GB/649140282 |
| Shute Wirlte Time | 0ms | 0.28 | 0.45 | 0.65 | 11 | 51.5 | 13% | |
| Shutfe Wite Size/Records | 0.0B/0 | 5.0MB/297954 | 10.8 MB/631749 | 17.8 MB/1054039 | 26.4 MB/1624982 | 57.2 MB/3385806 | 1677.4MB/151355463 | 10.5 GB/648154804 |
| Shutte HDFS Witte Time | 0m | 0.21 | 0.4⑮ | 0.7 | % | 년 | 40 | m0 |
| Shuffe Spil Time | 소 | 0ms | 0ms | ms | ms | 0ms | dP | |
| Shuffe spill (memory) | 0.08 | 094 | 0.08 | 6 | 0. | 0.08 | 32.8 GB | 151.7 G8 |
| Shufte spill (diak) | 0.08 | 0.0B | 0.0B | 0.00 | 0.08 | 0.08 | 4.6 GB | 30.5 GB |
可以看到上图中,不同的Task之间Shuffle Read和运行时间相差极大,运行时间为中位数的task 读取了52M数据,运行时间为7s,而运行时间最长的Task读取了10.3G的数据,是中位数的2000倍,运行时间为1.6h,是中位数的820倍。
这是典型的数据倾斜,由于少数的task读取了过多的数据,导致了长尾现象,即Stage的完成由这几个task决定。数据倾斜不仅会导致作业运行变慢,而且由于某些Task读取的数据过多,失败的概率增加,作业的稳定性也会受到影响。
AQE处理SkewedJoin的原理
当执行某个stage时,计算每个输入partition的大小。如果某一个partition的数据量或者记录条数超过中位数的N倍,并且大于某个预先配置的阈值,我们就认为这是一个数据倾斜的partition,需要进行特殊的处理。
假设A表和B表做innerjoin,并且A表中第0个partition是一个倾斜的partition,使用N个任务去处理该partition。每个任务只读取若干个map的shuffle 输出文件,然后读取B表partition 0的数据做join。最后,将N个任务join的结果通过Union操作合并起来。在这样的处理中,B表的partition 0会被读取N次,虽然这增加了一定的额外代价,但是通过N个任务处理倾斜数据带来的收益仍然大于这样的代价。如果B表中partition 0也发生倾斜,对于innerjoin也可以将B表的partition 0分成若干块,分别与A表的partition 0进行join,最终union起来。
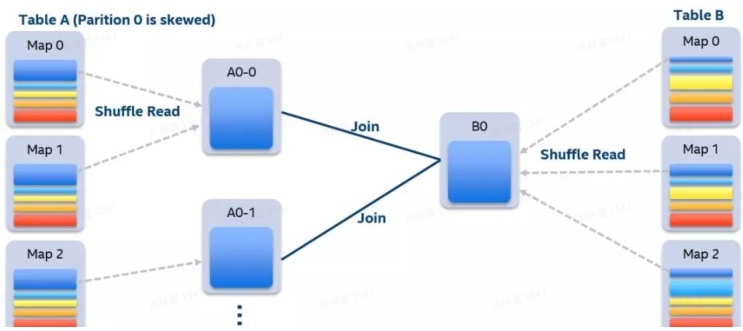
·..
AQE SkewedJoin生效条件
Join物理算子类型
AQE的SkewedJoin只针对SortMergeJoin和ShuffleHashJoin,对于BroadcastHashJoin无法生效。
JoinType
由于AQE的原理是拆分Partition,并分别与对应的Partition进行Join操作,然后将结果Union,所以对于Outer Join,非Outer Side是无法拆分的。
假设JoinType为LeftOuter,则如果Join的右侧输入存在倾斜,AQE是无法处理的。如果JoinType为Inner,则Join两边的倾斜都是可以处理的。
Join Pattern
AQE的优化是Stage级别的,即AQE在Stage执行之前,会根据当前Stage的已完成的上游的统计信息,对当前Stage进行优化调整。目前AQE支持如下几种包含SortMergeJoin的Stage Pattern。
Normal Join
最常见的Join Pattern,Stage10中,只有一个SortMergeJoin,且两边都是Sort+Exchange的组合.
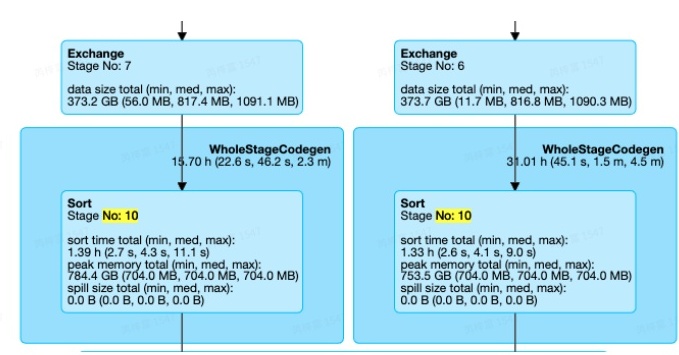
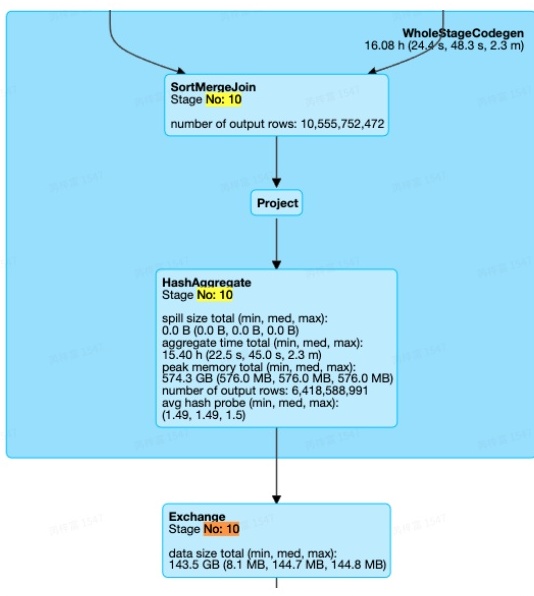
注:Join两边的倾斜是否可以处理,与JoinType有关。
JoinWIthAgg
Stage10中,同样只有一个SortMergeJoin,但是Join的一边并不是Sort+Exchange的组合,而是存在Aggregate算子
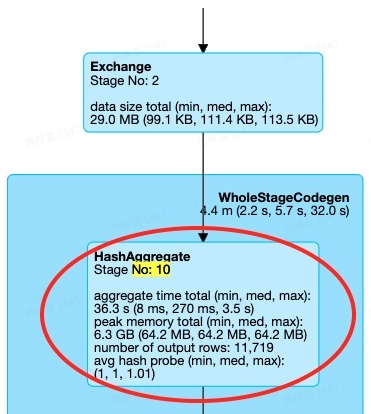
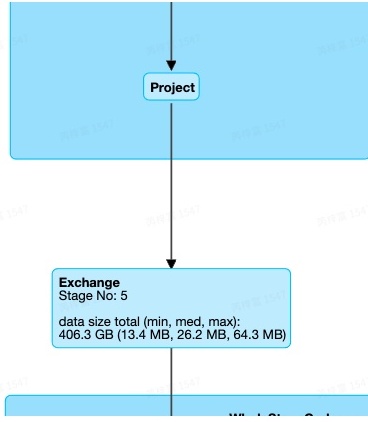
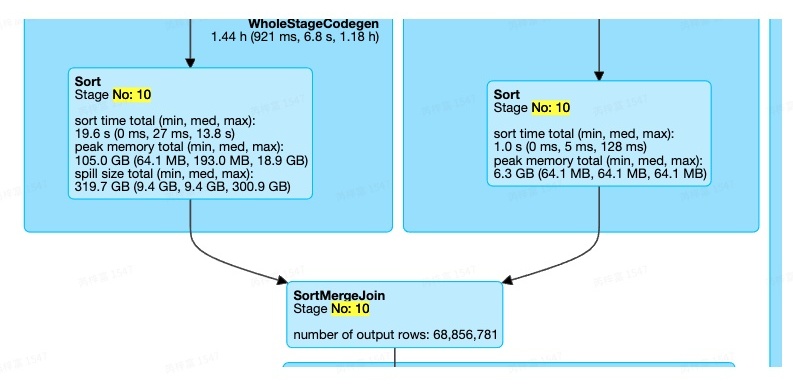
注:Join两边的倾斜是否可以处理,除了与JoinType有关,还与是否存在Agg算子有关。存在Agg算子的一侧也是无法处理倾斜的。例如,JoinType为Right Outer,且Join的右侧存在Agg算子,则Join 两边的倾斜都无法处理。
MultipleJoin
Stage21中存在多个SortMergeJoin
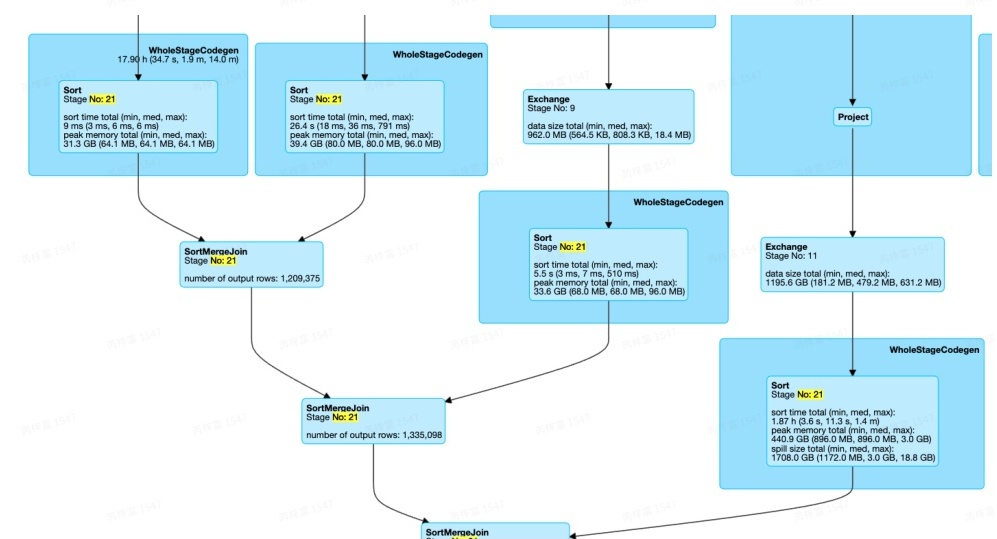
注:符合该Pattern的Stage有多个SorttMergeJoin,多个输入,某个输入的倾斜是否能够被处理,需要满足从最上层的Join到输入的路线中经过的所有Join的JoinType,例如

如果Join2.joinType=RightOuter,则A、B的倾斜无法处理;若Join2.join1Type=LeftOuter && Join1.joinType=RightOuter,则只有B的倾斜可以被处理。
MultipleJoinWithAggOrWin
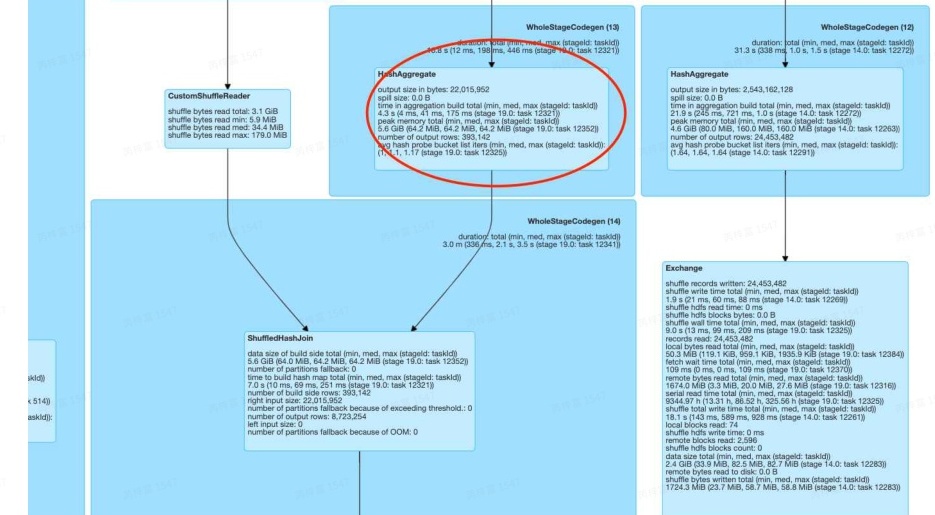
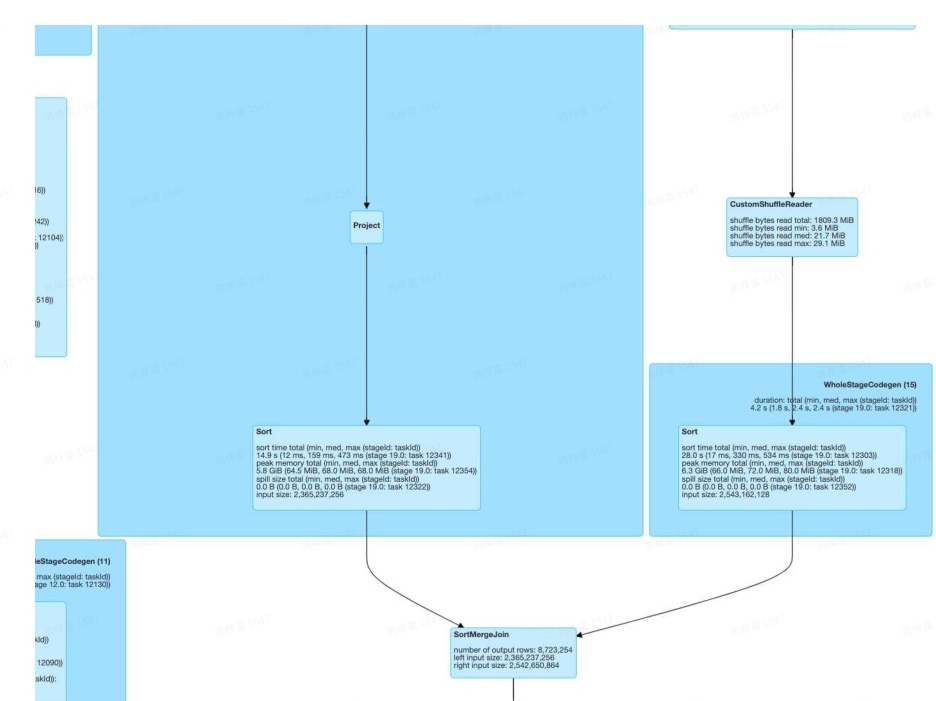
从上图我们可以看到,Stage 19中存在连续的Join,且还存在 HashAgg算子,我们目前的优化中支持了这一场景。
SkewedJoinWithUnion
如果用户的SQL中使用了UNION ALL,那么发生 SkewedJoin的 Stage 可能存在 Union算子。
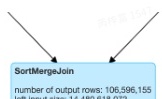
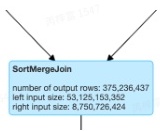

如上图所示,stage 318存在Union,而Union的两边是两个SortMergeJoin,之前如果这两个SortMergeJoin 出现倾斜,是无法处理的,我们目前优化中支持了这一场景。
AQE SkewedJoin优化参数配置
| 配置参数 | 意义 | 默认值 | TQS默认值(adhoc/etl) |
|---|---|---|---|
| spark.sql.adaptive.skewedPartitionSizeThreshold | 倾斜Partition的Size阈值,partition的size超过该阈值才会判断是否倾斜 | 64* 1024* 1024 | 52428800/67108864 |
| spark.sql.adaptive.skewedPartitionRowCountThreshold | 倾斜Partition的record阈值,partition的record超过该阈值才会判断是否倾斜,与 | 64* 1024* 1024 | 5000000/10000000 |
| skewedPartitionSizeThreshold是或的关系 | |||
| spark.sql.adaptive.skewedPartitionFactor | 数据倾斜判定标准,某一partition数据量超过中位数的N倍,将会判定为数据倾斜 | 5 | 5/10 |
| spark.sql.adaptive.skewedPartitionMaxSplits | 被判定为数据倾斜后最多会被拆分成的份数 | 5 | 6/5 |
如何查看这些参数
在Spark Ui的 Environment Tag页面有该任务的相关配置信息。
参数配置建议
如果想提高倾斜Partition的判定门槛,即不希望较小的Partition被认为是倾斜的,可以调skewedPartitionSizeThreshold
如果倾斜非常严重,例如几十上百倍,则可以提高skewedPartitionMaxSplits,增加倾斜Partition被拆分的个数,提高并发。
不同JoinPattern的开关
| 配置参数 | 意义 | 默认值 | TQS默认值(adhoc/etl) |
|---|---|---|---|
| spark.sql.adaptive.skewedJoin.enabled | Normal Join Pattern的优化开关 | true | true |
| spark.sql.adaptive.skewedJoinWithAgg.enabled | JoinWithAgg Pattern的优化开关 | true | true |
| spark.sql.adaptive.multipleSkewedJoin.enabled | MultipleJoin Pattern的优化开关 | true | true |
AQE SkewedJoin不生效的可能原因
- Join的物理算子不是SortMergeJoin或ShuffleHashJoin
- 倾斜侧不符合JoinType的要求
- Join所在的Stage不符合任何一种Join Pattern
- stage的partition大于highlyCompressedMapStatusThreshold 阈值
- AQE获取上游Stage的统计信息的精度收到一个阈值参数的影响spark.shuffle.highlyCompressedMapStatusThreshold,即当partition的数目大于该阈值时,AQE无法获取partition的详细分布统计,也就无法判断是否存在倾斜的partition。该参数目前默认值为2000,后续会逐步增大该阈值。
- 解决方案:增加 spark.shuffle.highlyCompressedMapStatusThreshold,确保其大于partition数目(一般为spark.sql.adaptive.maxNumPostShufflePartitions)