
Spark基本运行原理
Spark基本运行原理
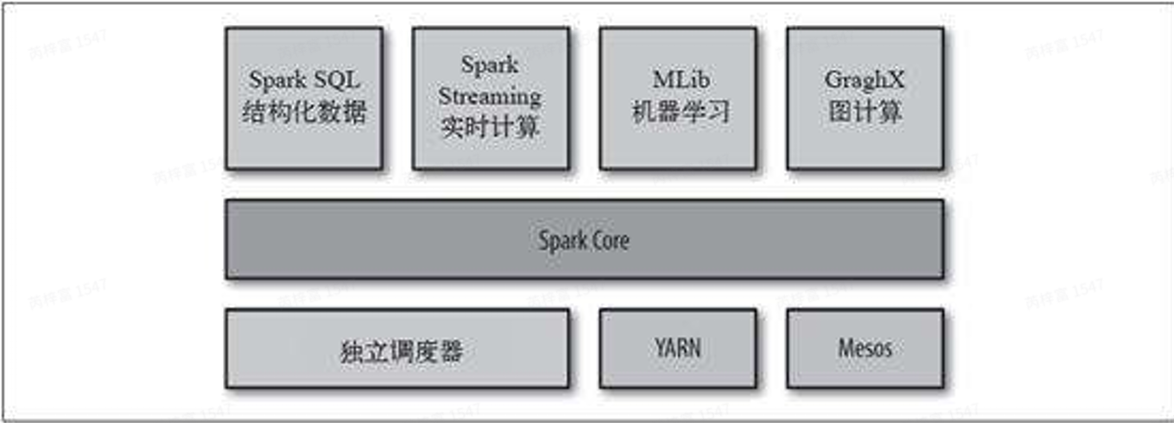
Spark简介
Spark 分布式计算框架由美国加州⼤学伯克利分校的AMP实验室开发。相⽐于Hadoop⾃带的 MapReduce计算框架,Spark优势明显。Spark⼀⽅⾯提供了更加灵活丰富的数据操作⽅式,有些 需要分解成⼏轮MapReduce作业的操作,可以在Spark⾥⼀轮实现;另⼀⽅⾯,每轮的计算结果都 可以分布式地存放在内存中,下⼀轮作业直接从内存中读取数据,节省⼤量磁盘IO开销。
- DAG
- 内存计算
- MRtask->进程级别,sparktask->线程级别
Spark运行模式
基础概念
Yarn: Hadoop资源管理系统,为应⽤提供统⼀的资源管理和调度。
- ResourceManger:处理客⼾端请求、启动和监控ApplicationMaster、监控NodeManager、 资源的分配与调度
- NodeManger:管理单个节点上的资源、处理来⾃ResourceManager的命令、处理来⾃ ApplicationMaster的命令
- ApplicationMaster:为应⽤程序申请资源
Spark
- Application:⽤⼾⾃⼰写的Spark应⽤程序,批处理作业的集合。Application的main⽅法为 应⽤程序的⼊⼝,⽤⼾通过Spark的API,定义了RDD和对RDD的操作 。
- SparkContext:Spark最重要的API,⽤⼾逻辑与Spark集群主要的交互接⼝。
- Driver:主控进程。SparkContext运⾏在其中,负责产⽣DAG,提交Job,转化Task。 Executor:负责执⾏Task,并将结果返回给Driver,同时也提供缓存的RDD的功能
提交Job得两种运行模式
Yarn-Client
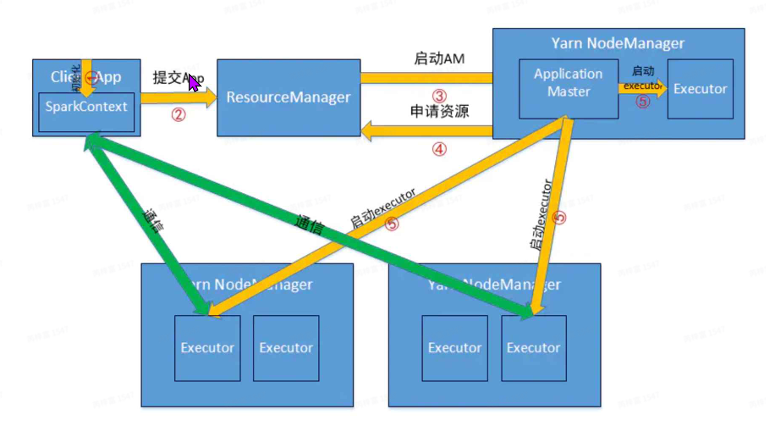
Yarn-Cluster

区别:
- yarn-client模式driver端在本地,可以与集群进⾏调度和通讯,进⾏交互式作业。但如果作业很 多则会造成client端压⼒很⼤。
- yarn-cluster模式driver运⾏在AM中,client提交完作业就可以关掉了,但⽆法进⾏交互式作业。
⼀个sql语句是如何处理数据的?

逻辑计划:
- 未解析的逻辑算⼦树:仅有数据结构,不包含数据信息。
- 解析的逻辑算⼦树:节点中绑定各种信息。
- 优化后的逻辑算⼦树:应⽤各种优化规则对⼀些抵消的逻辑计划进⾏转换。
物理计划:
- 根据逻辑算⼦树⽣成物理算⼦树的列表(可能1对多)
- 从列表中按⼀定的策略选取最优的物理算⼦树。
- 对选取的物理算⼦树进⾏提交前的准备⼯作:确保分区操作正确、物理算⼦树节点重⽤、执⾏ 代码⽣成等。
一个例子
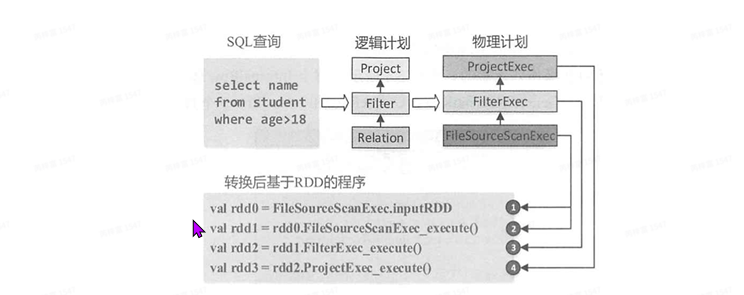
以上步骤都在driver端进⾏,不涉及分布式计算。
RDD(ResilientDistributedDateSet)
⼀种分布式的内存抽象,表⽰⼀个只读的数据分区集合。有丰富的转换操作,通常由其他RDD转换 创建,并记录如何衍⽣的信息。
RDD的⼀些特性:
容错机制:
- Lineage:根据⾎缘关系回溯RDD信息,失败重试参数:
- spark.task.maxFailures->4
- spark.stage.maxConsecutiveAttempts->4
- checkpoint:lineage太⻓、计算代价⼤时,可采⽤更稳健的硬盘持久化。
- Lineage:根据⾎缘关系回溯RDD信息,失败重试参数:
Partition(分区): ⼀个RDD在物理上被切分为多个Partition,即数据分区,这些Partition可以分布在不同的节点上;
Dependency(依赖)
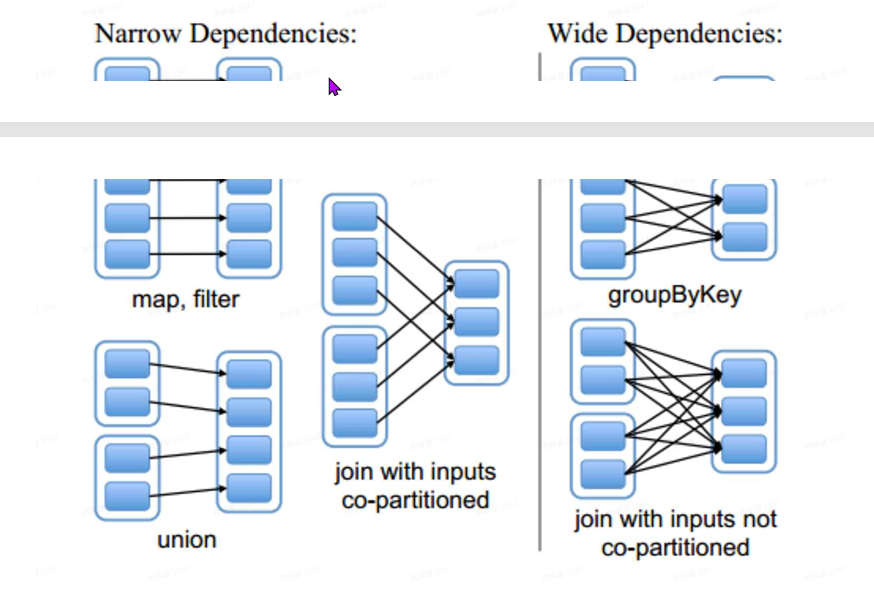
- NarrowDenpndency:map、filter、union
- Shuffle Dependency:join、groupByKey、reduceByKey
DAG:DirectedAcyclicGraph

- Job:在⼀个Application中,以Action算⼦划分Job,如collect、saveAsTextFile、show
- Stage:⼀个Job中,⼜以Shuffle为边界划分出的不同阶段,如join、groupByKey、 reduceByKey
- Task:每个Stage由⼀组并发的Task组成(即TaskSet),task个数由输⼊⽂件的切⽚个数来决定 的。通过算⼦修改了某⼀个rdd的分区数量,task数量也会同步修改。⼀个Stage的总Task的个数 由Stage中最后的⼀个RDD的Partition的个数决定
Shuffle
经典的MapReduce

- shuffle的map端:
- 在maptask执⾏时,它的输⼊数据来源于HDFS的block,MapReduce中叫split,spark中叫 partition. split与block⼀般是⼀对⼀.。
- mapper运⾏后,数据变为key/value的形式,通过partition函数,将数据进⾏分区,它的作 ⽤就是根据key或value以及reduce的数量来决定数据最终应该由那个reducetask处理。这⾥ 默认使⽤hashpartition,就是对key进⾏hash后再与reducetask的数量取模。
- 接下来,需要将数据写⼊内存缓冲区中,它的作⽤是批量收集map的结果,以减少磁盘的IO影 响。我们的key/value对以及Partition的结果都会被写⼊缓冲区。在写⼊之前,key/value值都 会被序列化成字节数组.
- 这个内存缓冲区默认为100MB,当maptask的输出结果达到80%的时候开始磁盘溢写,也就 是spill。这个溢写是由单独线程来完成的,不影响Map结果往缓冲区写的过程.
- 当溢写线程启动后,就会对这80MB的数据做排序(sort),这⾥的排序是对序列化的字节做排 序。⽽且这个sort和咱们逻辑上做排序操作没任何关系,它是为了reduce端在处理数据时,不 ⽤把所有的数据全部加载到内存处理,⽽是通过归并排序的⽅式从磁盘按顺序加载数据。这样 会⼤⼤减轻reduce端的压⼒。
- 每次溢写会在磁盘上⽣成⼀个溢写⽂件,如果map的输出结果很⼤,那就会有多个溢写⽂件存 在。当maptask真正完成时,会将这些⽂件合并成⼀个,这个过程就叫做Merge。
- 在⼀些情况下,我们可以在这⾥加⼀个combine操作,⽐如wordcount的求和,相当于在 map端做了⼀次reduce,这样可以减少map端数据,并给reduce端减少压⼒。
- shuffle的reduce端:
- reduce进程会启动⼀些copy线程,然后将⽂件从map端fetch数据回来并保存在本地磁盘中。
- 将不同map端数据进⾏merge,shuffle结束。
- Reducer进⾏处理,最后把结果放到HDFS上。

每个MapTask产⽣两个⽂件,每个节点只有2*M个⽂件。
问题:
数据倾斜会在哪⼀个环节出现?为什么?
数据倾斜会在shuffle阶段出现,因为涉及到了数据打散,如果某个值的数据异常多,则会导致这个值全部分布在一个partition中,造成数据倾斜。在sql中join和group by会产生shuffle操作,group by一般会有预处理步骤,不用太关注;join操作是发生数据倾斜的最主要场景。
举⼀个⾃⼰业务会出现倾斜的场景 shuffle过程会消耗那些资源?哪些会成为瓶颈?
内存、cpu、网络io、磁盘io。shuffle中涉及到了数据的shuffle write、shuffle read,数据的序列化,网络传输。在我们可控制的内存、cpu资源来看,最主要的瓶颈是shuffle read阶段会因为数据量的过大而导致内存溢出,因此需要合理的调整每个partition的数据量并均匀的分散数据。
为什么 join操作⼀定发⽣shuffle吗?·
不一定。如果其中一张表的数据量非常小,可以采取broadcast join来避免shuffle操作,大大缩短任务时间。在RDD api中可以自由控制每个shuffle的并行度,在两个RDD已由相同分区函数分区并partition数相同的情况下,join不会发生shuffle操作。
以下哪个sql会发⽣shuffle?(多选)
- select col1,col2 from table where col1 = 'hello' 错误。过滤不会产生shuffle
- select table1.a from table1 join table2 on table1.a = table2.a 正确。join是shuffle最主要的场景
- select col1,count(1) as ct from table group by col1 正确。聚合也会产生shuffle
- select col1, col2, row_number() over(partition by col1,sort by col2 desc) as rn from table 正确。窗口函数中有分区操作,也产生来shuffle
根据你对shuffle过程的理解,以下哪种⽅式可能会优化shuffle性能?(多选)
- 增加Executor个数 正确。增加资源不仅对shuffle性能好,对任何计算操作都有很大帮助
- 增加并行度 正确。增加task数量,相当于减少每个task处理的数据量。在task处理的数据量巨大的情况下是很有帮助的
- 合并输入小文件 正确。初始task由输入文件的个数决定,如果小文件过多,会导致每个task处理数据量小且task数过多。适当的合并输入小文件可以提升性能
- 先join,再过滤 错误。应该先过滤,在join。这样会减少shuffle中产生的数据量,提升shuffle效率
并⾏度越⼤越好吗?为什么?
并不是。在每个task处理的数据量过多时,可以适当增加并行度来减少每个task处理的数据量,以此增加速度。但当task处理的数据量非常小时,可以适当的减小并行度来减少task个数,因为driver在生成、分配、监视task时需要消耗时间,executor在切换处理task时也需要消耗时间。这些额外的消耗积少成多,增加了任务总时长。
Driver的功能是什么,有什么作用?
Driver主控进程,负责产生DAG和提交job,解析sql的逻辑和物理执行计划,不涉及具体的计算。而Executor负责具体的数据计算和缓存RDD等,执行具体的task任务。