
SparkWebUI和常⽤参数讲解
SparkWebUI和常⽤参数讲解
分享⽬标:
- 让⼤家了解SparkWebUI,知道如何去看?怎么看?要看些什么?了解哪些指标是关键点,我们该 如何通过这些信息来解决任务的问题和优化任务。
- 列举常⽤的spark参数,包括原⽣⾃带的配置和我司定制化的配置,了解这些参数是做什么的?为 什么要调节?如何去调节?相关spark原理可以参考
通过⼀个例⼦来⾛进sparkwebui
Sql语句:看情况加⼀下描述
CREATE TABLE ies_dw_test.zhangfei_20200320_challenge_label_1 AS
2 SELECT * from(
3 SELECT /*+mapjoin(b)*/
4 b.*,
5 a.second_level_label_name,
6 count(1) as cn,
7 row_number() over( --row_number()
8 partition by b.challenge_ids
9 order by count(1) desc
10 ) as rn
11 FROM
12 aweme.mds_dm_item_id_stats a
13 JOIN ies_dw_test.guanyu_huati b --broadcast join
14 on a.challenge_ids = b.challenge_ids
15 where --filter
16 date = '${date}'
17 and item_create_day >= '20190901'
18 and a.challenge_ids is not null
19 group by --group by (aggregate)
20 b.time,
21 b.challenge_name,
22 b.challenge_ids,
23 b.discription,
24 a.second_level_label_name
25 ) t
26 where --filter
27 rn <= 2Sparksql最后查询计划图
SQL选项卡(只有执⾏了sparkSQL查询才会有SQL选项卡)可以查看SQL执⾏计划的细节,它提 供了SQL查询的DAG以及显⽰Spark如何优化已执⾏的SQL查询的查询计划。
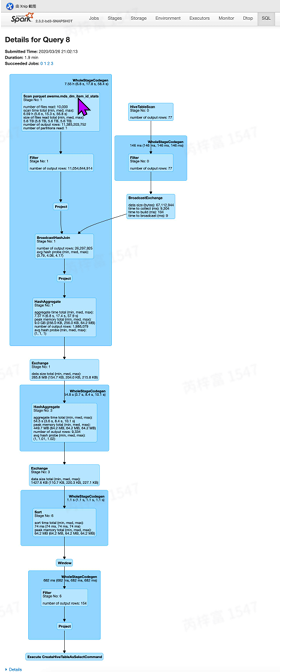
Exchange节点
- 实现数据并⾏化的重要算⼦,⽤于解决数据分布(Distribution)相关问题。继承它的⼦类有两种:
- BroadcastExchange:⼴播操作。
- ShuffleExchange:通过shuffle进⾏重分区。
WholeStageCodegen
全阶段代码⽣成,把⼀个stage⾥的算⼦进⾏了整合、优化。Tungsten中的内容。⼤⼤减少了虚函 数的调⽤,减少了CPU的调⽤,使得SQL的执⾏速度有很⼤提升Spark官方JIRA。
Spark2.0之前,SparkSQL的底层实现是基于VolcanoIteratorModel,这也是⼤多数据库处 理sql的底层模型,这个模型的执⾏可以概括为:⾸先数据库引擎会将SQL翻译成⼀系列的关系代数 算⼦或表达式,然后依赖这些关系代数算⼦逐条处理输⼊数据并产⽣结果。每个算⼦在底层都实现 同样的接⼝,⽐如都实现了next⽅法,然后⼀步步next完成。优点是抽象起来很简单,很容易实 现,⽽且可以通过任意组合算⼦来表达复杂的查询。但是缺点也很明显,存在⼤量的虚函数调⽤, 会引起CPU的中断,最终影响了执⾏效率。可以通过设置 spark.sql.codegen.wholeStage = false 查看。
SparkSQL的优化器Optimizer
AnalyzedLogicalPlan可以将SQL的逻辑很好的表⽰。然⽽在实际应⽤当中,很多低效的写法会带来执 ⾏效率的问题,需要进⼀步对其进⾏处理,得到更有的逻辑算⼦树。于是,针对SQL逻辑算⼦树的优 化器Optimizer应运⽽⽣。在2.1版本中实现了16个batch,包含53优化规则。⽐如有:
- 算⼦下推(OperatorPushDown):数据库常⽤优化⽅式,将上层算⼦节点尽量下推,靠近叶⼦ 结点,达到减少后续处理的数据量甚⾄简化后续的处理逻辑。⽐如列剪裁,他只读取查询语句中涉 及到的列。
- 算⼦组合(OperatorCombine):将能够组合的算⼦尽量整合在⼀起,避免重复计算,提⾼性 能。
- 常量折叠和⻓度消减(ConstantFoldingandStrengthReduction):涉及常量的节点在实际处理 之前完成静态处理。
⼀个优化场景:
谓词下推(PushDownPredicate): 算⼦下推的⼀种。如果底层数据源在进⾏扫描时能⾮常快速的完成数据的过滤,那么就会把过滤 交给底层数据源来完成,这就是谓词下推。
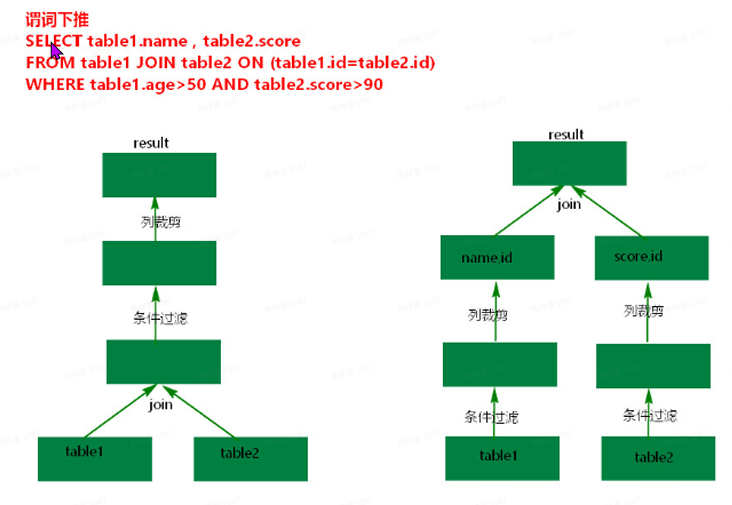
我司根据这部分做了进⼀步优化局部排序使⽤⽂档 末尾有event_log_hourly的案例可以参 考。SparkSQL中where中的过滤条件,会转化成Parquet的过滤条件,这样就可以在存储层⾯避免读 取⽆⽤的数据。通过封装SparkSql的DataSourceAPI完成各类数据源的查询,那么如果底层数据源⽆ 法⾼效完成数据的过滤,就会执⾏直接的全局扫描,把每条相关的数据都交给SparkSql的Filter操作符 完成过滤,虽然SparkSql使⽤的CodeGeneration技术极⼤的提⾼了数据过滤的效率,但是这个过程 ⽆法避免⼤量数据的磁盘读取,甚⾄在某些情况下会涉及⽹络IO(例如数据⾮本地化时);进⾏局部排 序来进⼀步加快底层数据过滤。使⽤场景:如果数据集使⽤⾮常频繁,可以在⽣成时将数据进⾏局部 排序。这⾥将会产⽣额外的资源消耗,需要trade-off,权衡。
alter table {tableName} set tblproperties ("localsort.enabled" = "true",
"localsort.columns" = "{column1,column2}", "parquet.block.size" = "33554432",
"parquet.compression" = "gzip")解释HashAggregate预聚合:这⾥是指的stage1中的partial_count。数据算⼦下推的⼀种,直接 在读取数据本地进⾏预聚合,功能上相当于上次讲的MapReduce中的combine操作,提前在map 端进⾏局部聚合来减少reduce端数据。这个相当于是sparksql的⼀个优化。但并不是所有的聚合 函数都可以进⾏预聚合的,⽐如说avg(),求平均数,不能说提前先求个平均数,那就有问题了。 这⾥的count是可以的。
业务层面调优
虽然SparkSQL优化功能很强⼤,但它并不是完美的。我们还是需要根据实际的情况来进⾏逻辑的最优 化。例如以下⼏点:
数据复⽤:
- 计算复⽤:重⽤相同的操作逻辑,减少cpu的计算代价。
- 数据复⽤:读同⼀份数据的两个任务之间没有依赖关系,想办法合并任务逻辑,使得只读⼀次 数据,减少IO操作。
select * from (
select a from t where b = 1
union
select a from t where b = 2
)
改为:
select * from (
select a from t where b = 1 or b = 2
)- 多表Join顺序调整:⼤⼤减少shuffle中间结果数据。这个信息可以在webui的sql图中看到。
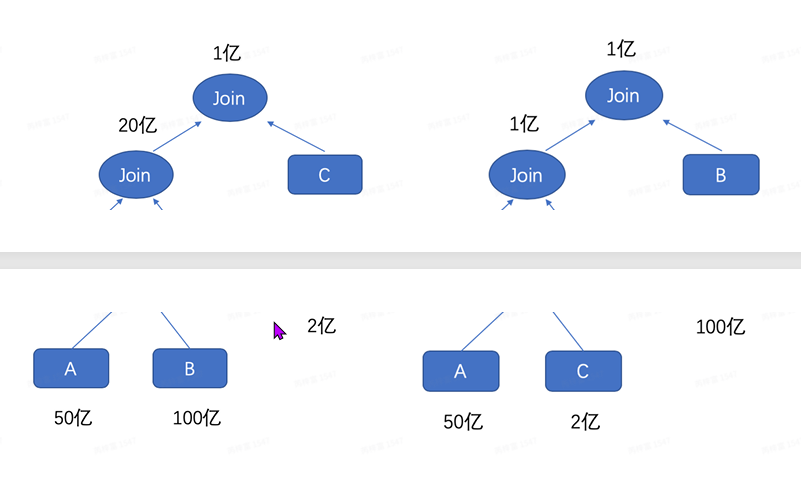
- 数据倾斜处理:分布式任务的优化就是合理的分配数据到各个节点上进⾏处理。但实际业务中数据 很难均匀分布,⽐如热点⽤⼾、视频。那么数据倾斜就会产⽣在shuffle中:Aggregation和Join。 其中Aggregation有Partial机制,问题不是很突出。在Join中,某些key数据量远⼤于其他时,处 理这些key的任务就会⾮常慢,甚⾄挂掉。业务层⾯解决思路:
- 过滤⽆关数据:实际业务中⼤量数据倾斜都是由业务⽆关的数据导致。⽐如脏数据、null数 据。排查后过滤即可。
- ⼩表⼴播:使⽤mapjoin也就是BroadcastJoin的⽅式避免shuffle。
- 倾斜数据分离:将有数据倾斜表T先分为t1和t2,t1没有倾斜数据,t2只包含倾斜数据。分别 join,在union。
- 数据打散:思路为分散倾斜数据。例如:将A、B两表按id进⾏Join,可以先将⼤表A中id加后 缀(id0,id1,id2),起打散作⽤。⼩表B中每条数据都复制多份。这样就可以起到数据均匀 处理的效果。
表A:
select id,value,concat(id,(rand() * 1000)%3) as id_new from A
表B:
select id,value,concat(id,suuffix) as id_new
from (
select id,value,suffix from B
)- 通过逻辑改写避免shuffle:⽐如⼀些数组的操作会通过lateralviewexplode+groupby。可以尝 试编写udf来解决问题。
SparkUI的选项卡组成
⼤部分指标都有说明,把⿏标移动上去即可显⽰,有些指标列表还⽀持排序,⼤家可以在上⾯多多 探索。
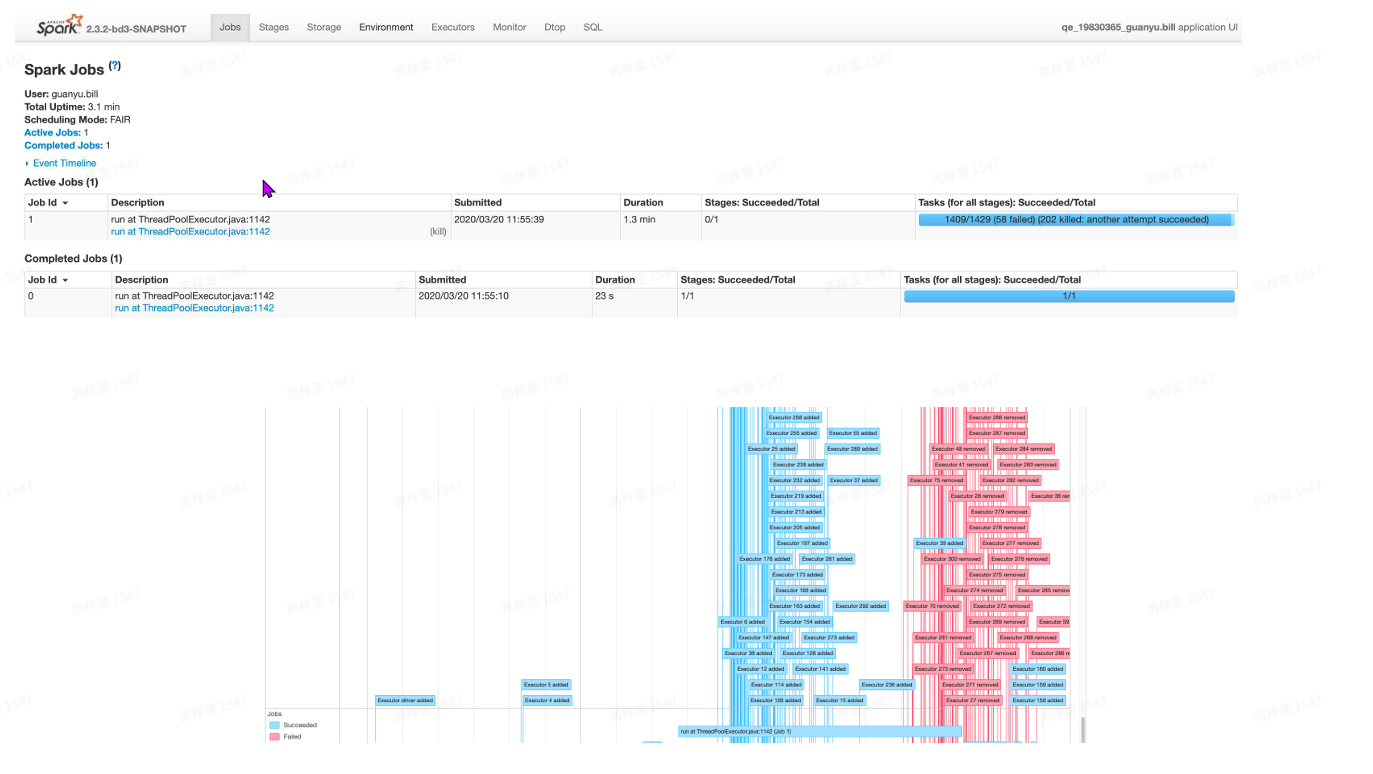
Jobs
在提交spark任务运⾏后,⽇志中会输出trackingURL即任务的⽇志链接。在浏览器中打开tracking URL后,默认进⼊Jobs⻚。Jobs展⽰的是整个spark应⽤任务的job整体信息:
- User: spark任务提交的⽤⼾,⽤以进⾏权限控制与资源分配。
- Total Uptime: spark application总的运⾏时间,从appmaster开始运⾏到结束的整体时间。
- Scheduling Mode: application中task任务的调度策略,由参数spark.scheduler.mode来设置,可选的参数有FAIR和FIFO,我司默认是FAIR。这与yarn的资源调度策略的层级不同,yarn的资源调度是针对集群中不同application间的,⽽sparkschedulermode则是针对application内部task set级别的资源分配。yarn的FAIR模型是⼀种公平模型,相当于每个任务轮换使⽤资源等,这样能 使的⼩job能很快执⾏,⽽不⽤等⼤job完成才执⾏了。
- CompletedJobs:已完成Job的基本信息,如想查看某⼀个Job的详细情况,可点击对应Job进⾏ 查看。
- Active Jobs: 正在运⾏的Job的基本信息。
- Event Timeline: 在application应⽤运⾏期间,Job和Exector的增加和删除事件进⾏图形化的展 现。这个就是⽤来表⽰调度job何时启动何时结束,以及Excutor何时加⼊何时移除。我们可以很⽅ 便看到哪些job已经运⾏完成,使⽤了多少Excutor,哪些正在运⾏。
Job默认都是串⾏提交运⾏的,如果Job间没有依赖,可以使⽤多线程并⾏提交Job,实现Job并 发。
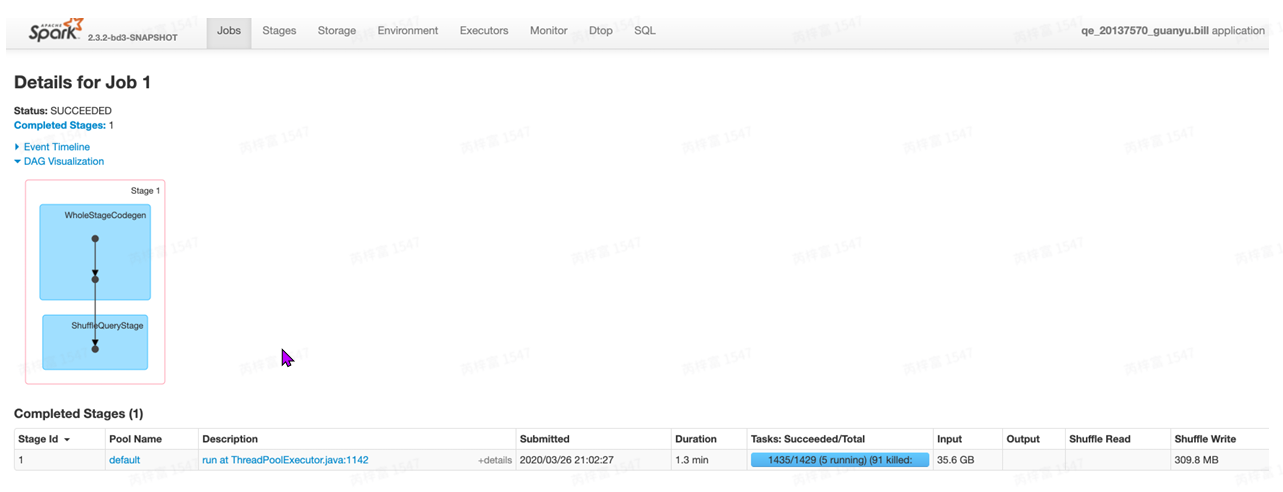
JobsDetail
在Jobs⻚⾯点击进⼊某个Job之后,可以查看某⼀Job的详细信息:
- Stauts: 展⽰Job的当前状态信息。
- Active Stages: 正在运⾏的stages信息,点击某个stage可进⼊查看具体的stage信息。
- Pending Stages: 排队的stages信息,根据解析的DAG图stage可并发提交运⾏,⽽有依赖的stage 未运⾏完时则处于等待队列中。
- CompletedStages: 已经完成的stages信息。
- Event Timeline: 展⽰当前Job运⾏期间stage的提交与结束、Executor的加⼊与退出等事件信息。
- DAGVisualization: 当前Job所包含的所有stage信息(stage中包含的明细的tranformation操 作),以及各stage间的DAG依赖图。DAG也是⼀种调度模型,在spark的作业调度中,有很多作业 存在依赖关系,所以没有依赖关系的作业可以并⾏执⾏,有依赖的作业不能并⾏执⾏
Stages
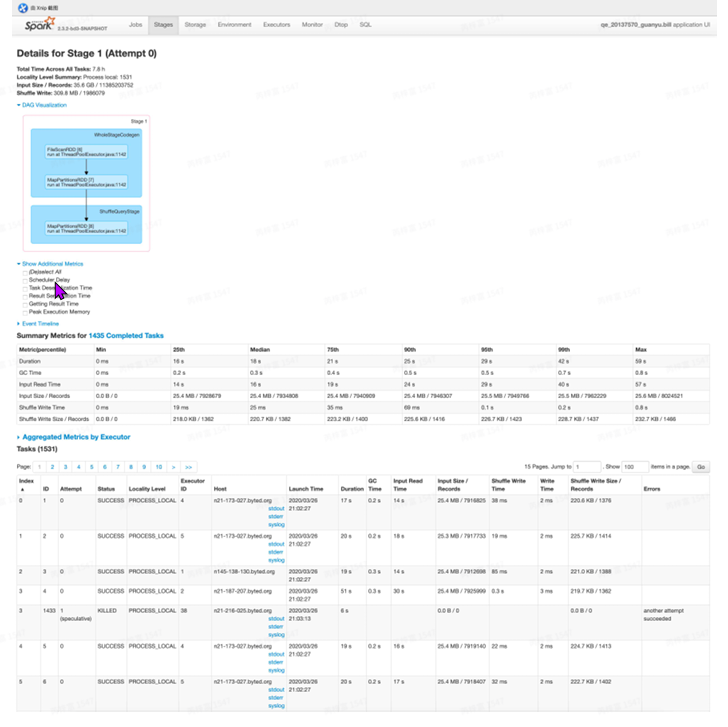
在JobDetail⻚点击进⼊某个stage后,可以查看某⼀stage的详细信息:
- Total time across all tasks: 当前stage中所有task花费的时间和。
- Locality Level Summary: 不同本地化级别下的任务数,本地化级别是指数据与计算间的关系。
- PROCESS_LOCAL进程本地化:task与计算的数据在同⼀个Executor中。
- NODE_LOCAL节点本地化:情况⼀:task要计算的数据是在同⼀个Worker的不同Executor进 程中;情况⼆:task要计算的数据是在同⼀个Worker的磁盘上,或在HDFS上,恰好有 block 在同⼀个节点上。
- RACK_LOCAL机架本地化,数据在同⼀机架的不同节点上:情况⼀:task计算的数据在 Worker2的Executor中;情况⼆:task计算的数据在Worker2的磁盘上。 ANY跨机架,数据在⾮同⼀机架的⽹络上,速度最慢。
- Input Size/Records: 输⼊的数据字节数⼤⼩/记录条数。这⾥可以通过参数控制任务初始并⾏度。
- Output Size / Records: 输出的数据字节数⼤⼩/记录条数。
- Shuffle Write: 为下⼀个依赖的stage提供输⼊数据,shuffle过程中通过⽹络传输的数据字节数/记 录条数。应该尽量减少shuffle的数据量及其操作次数,这是spark任务优化的⼀条基本原则。
- Shuffle read:总的shuffle字节数,包括本地节点和远程节点的数据 DAGVisualization: 当前stage中包含的详细的tranformation操作流程图。
- ShowAdditional Metrics:显⽰额外的⼀些指标。⿏标移上去会有相应的解释。
- Scheduler Delay:调度延迟时间,包含把任务从调度器输送给excutor,并且把任务的结果从 excutor返回给调度器。如果调度时间⽐较久,则考虑降低任务的数量,并且降低任务结果⼤⼩
- Task Deserialization Time:反序列化excutor的任务,也包含读取⼴播任务的时间
- Result Serialization Time:在executor上序列化task结果所花费的时间。
- Getting Result Time:从executor中获取结果的时间。
- Event Timeline: 清楚地展⽰在每个Executor上各个task的各个阶段的时间统计信息,可以清楚地 看到task任务时间是否有明显倾斜,以及倾斜的时间主要是属于哪个阶段,从⽽有针对性的进⾏优 化
- SummaryMetricsforXXXCompletedTasks:已完成的Task的指标摘要。
- Duration:task持续时间
- GCTime:taskgc消耗时间
- Output Write Time:输出写时间
- Output Size/ Records :输出数量⼤⼩,条数。
- Shuffle HDFS ReadTime:shuffle中间结果从hdfs读取时间
- Shuffle Read Size/Records: shuffle 读⼊数据⼤⼩/条数
- Shuffle Spill Time: shuffle 中间结果溢写时间。
- Shuffle spill (memory):shuffle溢写使⽤的内存⼤⼩。
- Shuffle spill (disk):shuffle 溢写使⽤的硬盘⼤⼩。
- Aggregated Metrics by Executor: 汇总指标。将task运⾏的指标信息按executor做聚合后的统计信 息,并可查看某个Excutor上任务运⾏的⽇志信息。这⾥可以看到executor完成task的情况,读⼊ 的数据量,shufflewrite、shuffleread数据量,根据这些指标判断节点是否健康。
- Tasks: 当前stage中所有任务运⾏的明细信息。右边部分都是需要关注的点。
Stages
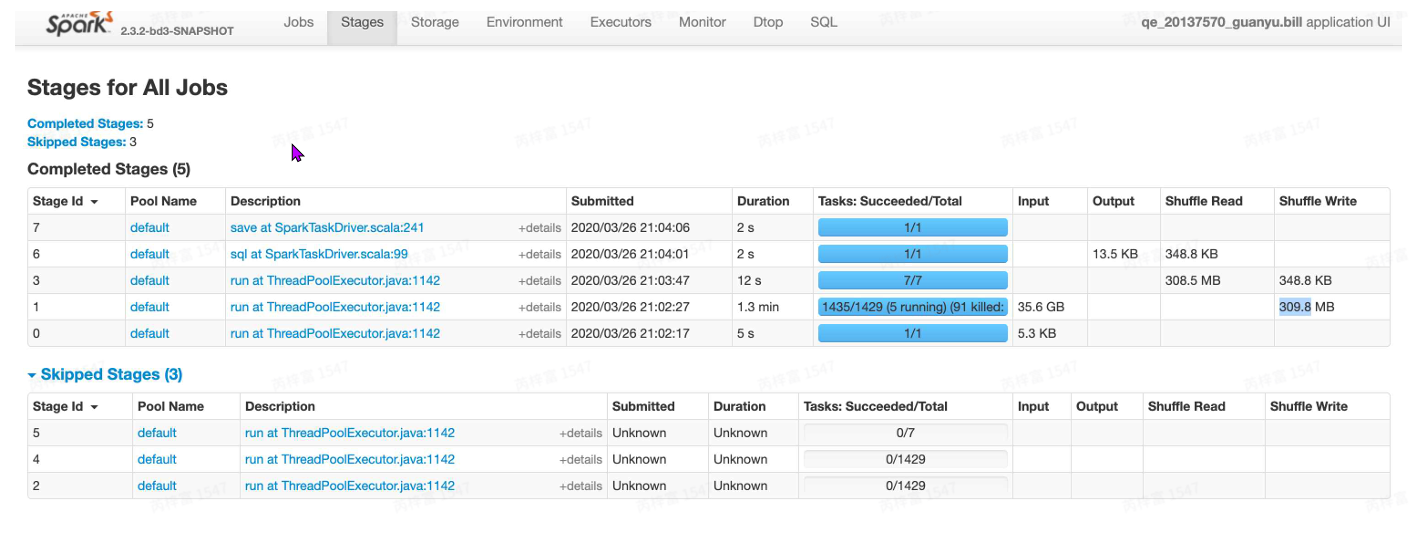
- Skipped stages:因为shuffle的落地⽂件如果还有对应rdd使⽤,它就不会被垃圾回收掉,stage发 现数据已经在磁盘或内存中了,那么就不会重新计算了。在将Stage分解成TaskSet的时候,如果⼀ 个RDD已经Cache到了BlockManager(BlockManager是spark管理⾃⼰的存储的组件,包括 memory和disk,⽐如RDD-Cache、Shuffle-output、broadcast都由它管理),则这个RDD对应 的所有祖宗Stage都不会分解成TaskSet进⾏执⾏,所以这些祖宗Stage和它们对应的Task就会在 Spark ui上显⽰为skipped。
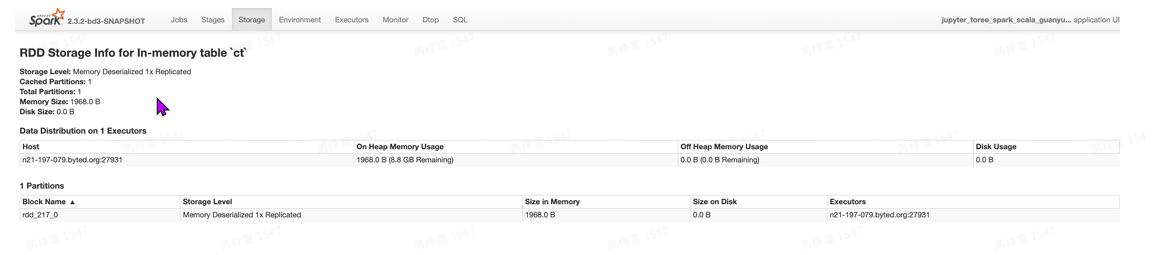
Storage
storage⻚⾯能看出application当前使⽤的缓存情况,可以看到有哪些RDD被缓存了,以及占⽤的内 存资源。如果job在执⾏时持久化(persist)/缓存(cache)了⼀个RDD,那么RDD的信息可以在这 个选项卡中查看。

Spark sql的使⽤⽅式:
cache table tableName --
缓存全表
2 cache table ct as select ... --
缓存查询结果
3 uncache table tableName --
使⽤完最好⼿动释放缓存。- 这个缓存仅可以在⼀个sparkapplication中使⽤,sparkapp结束就没有了。
- 使⽤场景:如果某个表或者某个中间结果反复使⽤,可以利⽤这个特性来防⽌反复计算。
StorageDetail
点击某个RDD即可查看该RDD缓存的详细信息,包括缓存在哪个Executor中,使⽤的block情况, RDD上分区(partitions)的信息以及存储RDD的主机的地址。
Environment
Environment选项卡提供有关Spark应⽤程序(或SparkContext)中使⽤的各种属性和环境变量的信 息。⽤⼾可以通过这个选项卡得到⾮常有⽤的各种Spark属性信息,⽽不⽤去翻找属性配置⽂件。通 过平台⼯具提交任务时,其默认参数配置可以在这⾥查找。
Executor
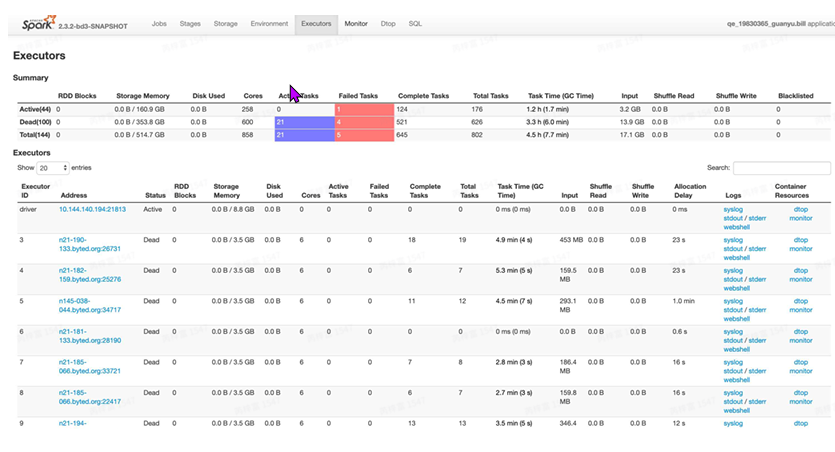
Executors选项卡提供了关于内存、CPU核和其他被Executors使⽤的资源的信息。这些信息在 Executor级别和汇总级别都可以获取到。⼀⽅⾯通过它可以看出来每个excutor是否发⽣了数据倾斜, 另⼀⽅⾯可以具体分析⽬前的应⽤是否产⽣了⼤量的shuffle,是否可以通过增加并⾏度来减少shuffle 的数据量。
- Summary:该application运⾏过程中使⽤Executor的统计信息。
- Executors: 每个Excutor的详细信息(包含driver),可以点击查看某个Executor中任务运⾏的详 细⽇志
Monitor
JVMHeapSize:jvm的堆内存使⽤情况。 Executor 分配:查看任务Executor分配情况。
Dtop
查看作业cpu、mem的使⽤率。
常⽤配置参数及原理
基本参数详解
Driver
主控进程。SparkContext运⾏在其中,负责产⽣DAG,提交Job调度task。task数量越多,消耗内 存和⽹络io越多。
- spark.driver.memory=12G :driver的堆内存
- spark.driver.cores :driver的core数
- spark.driver.memoryOverhead=6144 :driver的堆外内存
Executor
负责执⾏Task,并将结果返回给Driver,同时也提供缓存的RDD的功能。shuffle越多或数据量越 ⼤,消耗的内存越多。task计算的并⾏度由core个数决定。core越多,计算越快,task所占⽤的内 存空间就越⼩。所以这是⼀个trade-off,如果任务的shuffle量很⼩,主要是⼀些计算、过滤操作, 那么可以多核少内存,甚⾄可以开启 spark.vcore.boost.ratio=2 (原 spark.vcore.boost=2 ) ,⼀个core来跑两个task,提⾼cpu利⽤率。如果shuffle很重,那么 就需要看shufflewrite/read指标来调节内存⼤⼩。
- spark.executor.memory=8G :每个executor的堆内存⼤⼩。⻛神默认5g。关于堆内存 的组成,可以参考:spark静态内存,spark动态内存
- spark.executor.cores=4 :每个executor的核数,默认1个core运⾏1个task。⻛神默认 3个
- spark.executor.memoryOverhead=6144 :每个executor的堆外内存,默认取 max(384MB,spark.executor.memory*0.1),dorado默认6G,⻛神默认3G
我们需要配置使⽤的资源主要就是cpu和内存,虽然⽹络带宽和硬盘也是计算任务的主要消耗品,但 这块⼉不需要我们操⼼。从计算任务⻆度来看,资源当然是越多越好,但资源这东西不是免费的, 它是⼀块⼉很⼤的成本。所以从公司⻆度看待,我们要最⼤化利⽤我们的资源。⼤了来讲,我们要 优化任务之间的合理调度,将集群资源使⽤率削峰填⾕;⼩的来说,我们要优化每个任务的逻辑, 根据不同计算情况进⾏资源调整。
这⾥涉及到了yarn集群资源,yarn的队列机制是为了控制不同业务线的资源⼤⼩,可以配置每个队 列最⼤、最⼩资源量来进⾏弹性分配。HL/topi队列配置的最⼤、最⼩量基本相同,意味着我们队列 的资源是固定的(这个队列配置为固定的⼀批服务器)。集群配置的core、mem⽐是1:5,当其中 ⼀种资源分配完后,另⼀种资源就Reserved了,所以⼤家可以尽量按照这个⽐例来配置executor的 core和memory。
Executor个数
建议使⽤动态资源分配(默认开启) 官⽅⽂档link。使它可以根据⼯作负载动态调整应⽤程序占⽤ 的资源。这意味着,如果不再使⽤资源,应⽤程序可能会将资源返回给集群,并在稍后需要时再 次请求资源。如果多个应⽤程序共享Spark集群中的资源,该特性尤其有⽤。Driver会判断如果 没有在taskpending的情况,资源会被释放掉
- spark.dynamicAllocation.enabled=true ,开启参数
- spark.dynamicAllocation.minExecutors=5 ,executor最⼩申请个数
- spark.dynamicAllocation.maxExecutors=900 ,executor最⼤申请个数
- spark.dynamicAllocation.initialExecutors=5 ,初始申请executor个数,默认等 于minExecutors ◦
- spark.dynamicAllocation.executorIdleTimeout=120s ,⼀个executor空闲超过 该参数时,⾃动释放资源 ◦ ◦ ◦ 4.
- spark.dynamicAllocation.schedulerBacklogTimeout (默认1秒),如果有task pending超过该参数,开启资源申请
- spark.dynamicAllocation.sustainedSchedulerBacklogTimeout (默认等于上 ⾯的参数),当pendingtask存在以后,每隔该参数进⾏⼀个资源的申请(如果资源有,会以1、 2、4、8指数的申请) spark.shuffle.service.enabled=true ,在不删除由executors产⽣的shuffle⽂件的 情况下删除executors
Spark内存管理
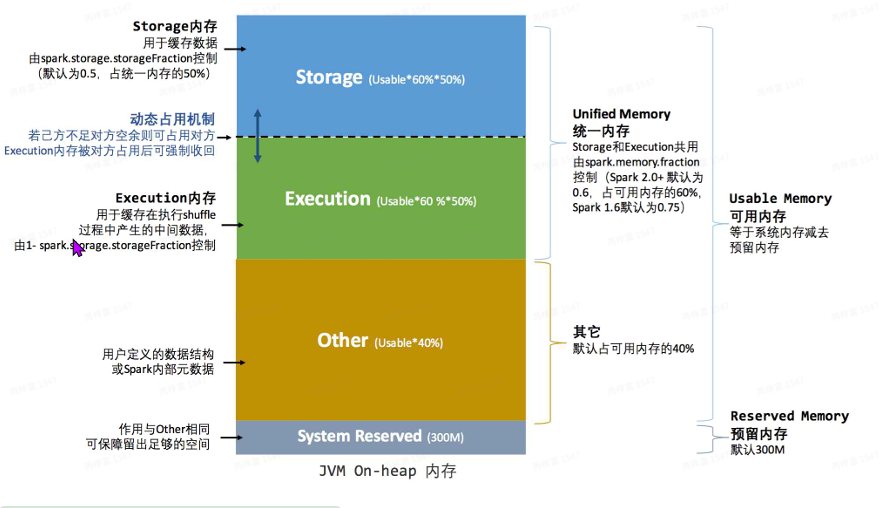
spark.memory.fraction=0.6 统⼀内存占⽐。在shuffle很重、内存很⼤的情况下可以适 当调⼤该参数。
SparkSQLJoin原理简介
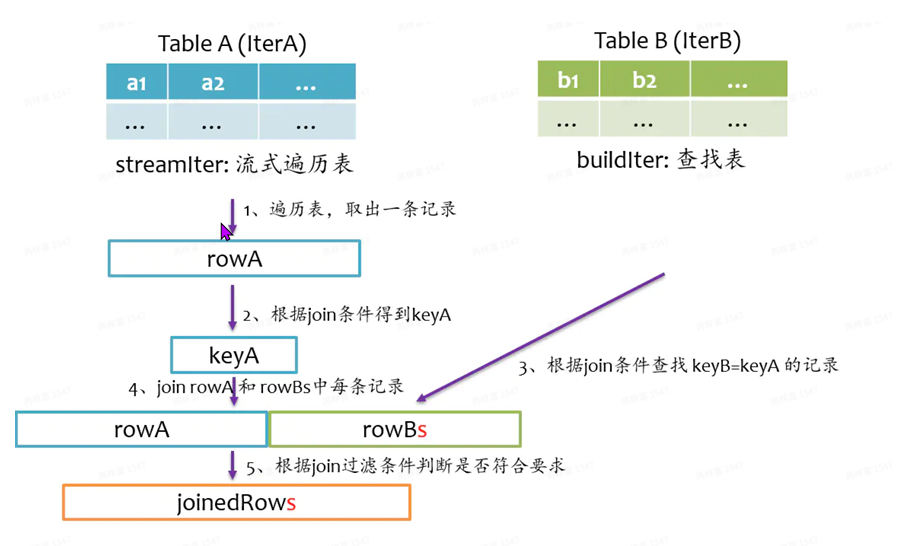
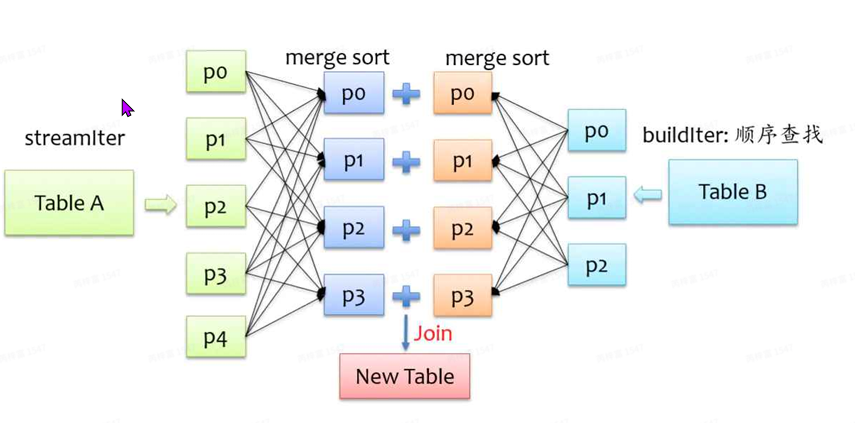
总体上来说,Join的基本实现流程如下图所⽰,Spark将参与Join的两张表抽象为流式表 (StreamTable)和查找表(BuildTable),通常系统会默认设置为StreamTable⼤表,BuildTable为⼩ 表。流式表的迭代器为streamItr,查找表迭代器为BuidIter。Join操作就是遍历streamIter中每条 记录,然后再buildIter中查找相匹配的记录。
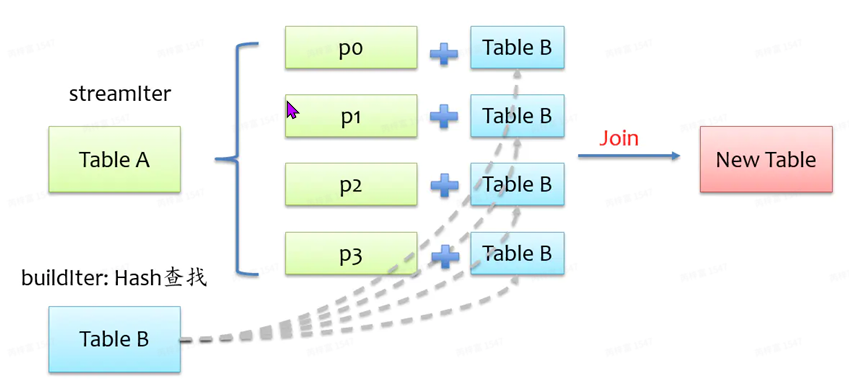
BroadcastJoin机制:
对⼩表进⾏⼴播,避免shuffle的产⽣。webui的sql图可以看到drivercollect的时间,build建表 压缩时间,broadcast⼴播时间。所以频繁有⼴播时,会对driver端产⽣较⼤压⼒。需要注意的 是:在Outer类型的Join中,基表不能被⼴播,⽐如AleftouterjoinB时,只能⼴播右表B。
触发场景:
- 被⼴播表⼩于参数 spark.sql.autoBroadcastJoinThreshold=20971520 ,默认 10MB。公司改默认20MB
- 在SQL中显⽰添加Hint(MAPJOIN、BROADCASTJOIN或BROADCAST)
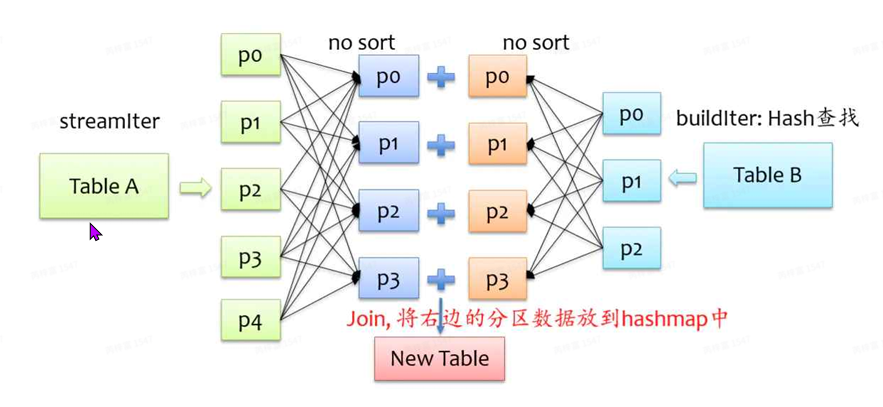
ShuffledHashJoin机制
步骤:
- 对两张表分别进⾏shuffle重分区,将相同key的记录分到对应分区中,这⼀步对应Exchange节点
- 将查找表分区构造⼀个HashMap,然后在流式表中⼀⾏⾏对应查找。
要将来⾃BuildTable每个分区的记录放到hash表中,那么BuildTable就不能太⼤,否则就存不下, 默认情况下hashjoin的实现是关闭状态,如果要使⽤hashjoin,原⽣spark必须满⾜以下四个条 件:
- spark.sql.autoBroadcastJoinThreshold 设定的值,即不满 查找表总体估计⼤⼩超过 ⾜BroadcastJoin 条件 关闭优先使⽤SortMergeJoin开关
- spark.sql.join.preferSortMergeJoin=false 每个分区的平均⼤⼩不超过
- spark.sql.autoBroadcastJoinThreshold 设定的值,查找 表数据量<⼴播数据阈值*shuffle的partition数。
- streamIter 的⼤⼩是 buildIter 三倍以上
ShuffledHashJoin触发条件⾮常苛刻,我司有相关优化策略,下⾯会提到。
SortMergeJoin机制
此为sparksql的主要join⽅式,hashjoin是将⼀侧的数据完全加载到内存中,这对⼀定⼤⼩的表 ⽐较适⽤,但两个表都很⼤时,⽆论加载哪个表到内存都不理想。所以sparksql使⽤sortmerge 的⽅式。
步骤:
- 对两张表分别进⾏shuffle重分区,将相同key的记录分到对应分区中并进⾏排序,这⼀步对应 Exchange节点和sort节点。也就是spark的sortmergeshuffle过程。
- 遍历流式表,对每条记录都采⽤顺序查找的⽅式从查找表中搜索,由于排序的特性,每次处理 完⼀条记录,只需从上⼀次结束的位置开始继续查找。整体上来说,查找性能还是较优的。
动态控制spark并⾏度及AE特性 (AdaptiveExecution)
在RDD操作中可以⾃由的设置每次shuffle算⼦的并⾏度,但在sql语句中并没有提供这样的操作, 只能通过Spark⾃带的是spark.sql.shuffle.partition来控制的,spark默认200,任务从头到尾的所有 shuffle都是这个并⾏度,⽆法⾃由操控。
intel在社区贡献了⾃适应调节的特性,可以让作业根据每次shuffle的数据量⾃⾏调节并⾏度。实 现原理是在每个stage完成后再启动⼀个⼦Job来计算shuffle中间结果量,依此来进⾏调节task个数。
为什么要调节并⾏度?
- 并⾏度如果太⼩,每个reducer处理的数据量多,task不停的溢写会造成⼤量的磁盘io,导致 task执⾏时间过⻓,如果内存⽐较⼩+当时的物理机不是很健康(很常⻅)的情况,轻则gc时间 过⻓,重则直接任务失败。
- 并⾏度如果太⼤,每个task处理的数据量⼩,driver的压⼒会很⼤(调度task),并且task 多,shuffle的时候map阶段(shufflewrite)写的⽂件也会变多,reduce段去拉取数据的时候 会读取⼤量的⼩⽂件。
- spark.sql.adaptive.enabled = ture ,⾃适应执⾏框架的开关,默认开启
- spark.sql.adaptive.minNumPostShufflePartitions=1 reduce个数区间最⼩值
- spark.sql.adaptive.maxNumPostShufflePartitions= 500 reduce个数区间最⼤ 值
- spark.sql.adaptive.shuffle.targetPostShuffleInputSize= 67108864 动 态调整reduce个数的partition⼤⼩依据,reduce端task能否合并的⼤⼩阈值,多个连续的 tasks(按task id排序,物理连续)数据量⼩于该阈值且也满⾜targetPostShuffleRowCount (下⼀⾏的参数)条件时时会合并成⼀个task。
- spark.sql.adaptive.shuffle.targetPostShuffleRowCount=20000000 动态 调整reduce个数的partition条数依据,如设置20000000则reduce阶段每个task最少处理 20000000条的数据。
需要注意最⼤并⾏度的设置,不要设为2的幂次⽅(收起程序员的强迫症)
AE还做了shuffle得相关优化:
SortMergeJoin调整为BroadcastJoin
- spark.sql.adaptive.join.enabled=true ,开启后,参与join的两个stage对应的⼦ job执⾏完成后,统计各stageshuffle数据量⼤⼩,如果某⼀个stageshuffle数据量⼩于 spark.sql.adaptiveBroadcastJoinThreshold(默认为 spark.sql.autoBroadcastJoinThreshold设置的值),就将执⾏计划由SortMergeJoin调整为 BroadcastHashJoin。
SortMergeJoin调整为ShuffledHashJoin
- spark.sql.adaptive.hashJoin.enabled=true 开启后AE会根据task数据量⼤⼩⾃ 动判断能否将SortMergeJoin转换成ShuffledHashJoin。
- spark.sql.adaptiveHashJoinThreshold=52428800 每个partition的数据量都⼩于 等于该值,则将执⾏计划由SortMergeJoin调整为ShuffledHashJoin,调整后会消除原来耗时 的排序过程。do默认20MB,⻛默认50MB
处理数据倾斜功能。
- SparkAESkewedJoin优化指南 set spark.sql.adaptive.skewedPartitionFactor=3;
- set spark.sql.adaptive.skewedPartitionMaxSplits=20;
- set spark.sql.adaptive.skewedJoin.enabled=true;
- set spark.sql.adaptive.skewedJoinWithAgg.enabled=true;
- set spark.sql.adaptive.multipleSkewedJoin.enabled=true;
- set spark.shuffle.highlyCompressedMapStatusThreshold=20000;
处理数据倾斜推荐使用AE特性
Sparkshuffle中间结果落地hdfs
将shuffle中间结果多保存⼀份到hdfs上。⼀些节点可能会因为负载⾼,⼼跳连不上跑丢了,那它 上⾯的shuffle中间结果就找不到了。作业就会重试。所以在⼤型作业中,可以使⽤此命令。
- spark.shuffle.hdfs.enabled=false ,开启后, 建议添加以下两个参数
- spark.shuffle.io.maxRetries=1 ,shuffle拉去数据重试次数,最⼩为1
- spark.shuffle.io.retryWait=0s
适⽤场景
- 重试成本⾼(耗时久,或者需要的资源多)
- 对SLA要求⾼,不能接受因为FetchFailedException引起的StageRetry造成的Delay
不适⽤场景
- 作业执⾏时间短(如低于30分钟)
- 重试成本低
- 对稳定性要求低,但对速度要求⾼,如ad-hoc查询
注意:开启hdfsshuffle尽量避免shuffle的stage的task太多,否则会对hdfsnn的写和读会造成压 ⼒。
初始task数调节
初始task个数由读⼊⽂件个数决定。AE⽆法触及。
以下两种情况是需要调节的:
- task数量过多,⽽且每个task读⼊的数据量很少:driver端压⼒很⼤,产⽣⼤量的rpc通信。
- task读⼊数据量过⼤,应当增加并⾏度提⾼速度。
Spark读取Parquet⽂件,会按列剪枝。⽽划分Split时并未考虑列剪枝。因此当所选取的列数远⼩于总 列数时,实际每个⽂件内需要读取的数据量很⼩,可能只有⼏MB甚⾄⼏KB。因此可根据⽬标列数占 总列数的⽐例相应增⼤⽂件⼤⼩。
- spark.sql.hive.convertMetastoreParquet= true 当向Hivemetastore中读写 Parquet表时,SparkSQL将使⽤SparkSQL⾃带的ParquetSerDe(SerDe: Serialize/Deserilize的简称,⽬的是⽤于序列化和反序列化),⽽不是⽤Hive的SerDe,Spark SQL⾃带的SerDe拥有更好的性能。
- spark.sql.parquet.adaptiveFileSplit= true Dorado默认false,如读取 parquet,需⼿动开启。
- spark.sql.files.maxPartitionBytes Dorado默认1G,⻛神默认256MB = 1073741824 每个task处理最多的数据量。
- spark.sql.files.openCostInBytes=16777216 Dorado默认值16MB,神默认 4MB spark.datasource.splits.max ,读多个表时,上⾯的参数可能会对其他表input造成 影响。可以使⽤该参数来直接设置task数,当task数超过该值时,会重新划分⽂件并使之尽可 能接近设置值。Do默认没有,⻛神默认50000
输出数据⼩⽂件⽂件合并
Spark输出⽂件的数量由最后⼀个stage的并⾏度来决定。 如果开启此功能,会增加⼀定程度的计算消耗。
合并⼩⽂件的⽬的:
- Spark sql mergefile功能 为了下游任务使⽤时task数量变少,虽然有相关参数调节,但从根本上解决最好。
- hdfs是设计为存储⼤块⼉数据使⽤的,如果分割的⽂件太⼩,则会导致⽂件数过多,那么管理⽂件 元数据的namenode就会有很⼤压⼒。
合并⽂件⽅式:
按⽂件数合并:
spark.merge.files.enabled=false ,开启⽂件合并。Do、神默认关闭。
spark.merge.files.number=512 ,输出⽂件数量。
说明
- 该功能会在原来job的最后⼀个stage后⾯增加1个stage来控制最后⽣成的⽂件数量,任务性能 上会有⼀点影响,但基本可以忽略。
- 该功能能够精确的控制⽣成的⽂件数量。
- 对于动态分区,每个分区表⽣成spark.merge.files.number个⽂件。
按⽂件⼤⼩合并:
spark.sql.adaptive.enabled=true 开启AE。
spark.merge.files.byBytes.enabled=false 开启⽂件合并。
spark.merge.files.byBytes.repartitionNumber=1000 int类型
spark.merge.files.byBytes.fileBytes=134217728 long类型
spark.merge.files.byBytes.compressionRatio=3 double类型,该参数表⽰ shuffle数据量与最后⽣成到hdfs上的数据量的压缩⽐,因为shuffle⽂件和⽣成到hdfs上的⽂件 存储格式和压缩格式都不相同,通过shuffle数据量预估hdfs⽂件数据量时会有⼀定的误差,因 此设置该参数来调节
原理:会在原来job的最后⼀个stage后⾯增加2个stage,第⼀个stage的并⾏度由参数spark.merge.files.byBytes.repartitionNumber控制(默认1000),然后根据第⼀个stageshuffle的 数据量来预估最后⽣成到hdfs上的⽂件数据量⼤⼩,并通过预估的⽂件数据量⼤⼩计算第⼆个stage的 并⾏度,即最后⽣成的⽂件个数。
HDFS的namenode记录的是block的元信息。⼩⽂件过多会导致nn压⼒多⼤。
这⾥说⼀下Hadoop分布式⽂件系统(HDFS),它也有最⼩读写单位:block,不过⽐传统磁盘⼤ 很多,官⽹默认128MB。我查了下我们公司的dfs.block.size默认是512MB。它提供这个抽象的单位 的好处是为了节省寻址时间,⽽且可以存储超过单个磁盘⼤⼩的⼤⽂件,因为它可以将⼤⽂件切分 成多个block,然后每个block分别去做副本。这⾥介绍下block的切分,按咱们公司来说,如果⽂件 <=512MB的话,就认为它是1个block,存储⼤⼩为⽂件实际⼤⼩,⽐如500KB的⽂件就是占⽤ 500KB的物理空间,不是512MB;如果⼤于512MB,则按512切分,⽐如513MB,那就切2个。所以 对集群来说落地⽂件⼤⼩在500MB左右是最合适的。
但是对跑任务来说,是trade-off,总⽂件量不变的情况下,block越多,任务的并⾏读取就会提⾼, 任务速度会快,相反,block少,速度会慢。
Task失败重试机制
- spark.task.maxFailures=8 ,公司默认为8。⼀个固定task失败次数达到该值则判定 task所在的Stage失败了,意味着可以重试7次 ◦
- spark.stage.maxConsecutiveAttempts=4 ,⼀个固定stage重试次数达到该值则判定 stage所在的Job失败了,意味着可以重试3次
推测执⾏
有时可以看到task被kill,显⽰:anotherattemptsucceeded,这个就是推测执⾏的效果。这是 由于集群节点状况不⼀,所以可能有些task执⾏在机器负载⾼的机⼦上,这时符合上⾯的条件后,会 另起⼀个相同的task到其他节点,最后谁先完成算谁的。技术来源于⽣活,骑驴找⻢。
- spark.speculation=true 公司默认开启 spark.speculation.interval=100ms 每隔该参数时间对task进⾏检查
- spark.speculation.multiplier=1.5 当⼀个task的执⾏时⻓超过task运⾏时⻓的中 位数的参数倍的时候,推测task开启
- spark.speculation.quantile=0.75 该stage必须完成task超过该参数百分⽐之后, 推测task才会执⾏