
Spark问题定位参考文档
Spark 问题定位参考⽂档
⼀、获取任务执⾏信息
定位spark问题,⾸先需要找到任务的执⾏信息,主要包括sparkui,⽇志信息。 UI链接在⽇志⾥搜索trackingURL,找到任务对应的UI链接。
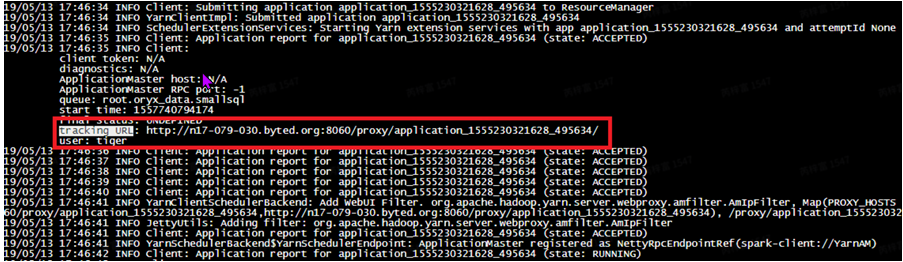
⽇志信息:
- Driver log
- Client 模式:DriverLog打印在本地,也就是提交任务的机器上(开发机等)
- Cluster 模式:DriverLog打打印在AM中,可以通过YARN⻚⾯找到任务⽇志链接
- Executor log
二、任务优化
任务执行慢
执⾏spark任务时,有很多种原因会导致任务执⾏缓慢,包括资源不⾜,参数设置不合理,集群 环境负载⾼,代码问题或者数据本⾝(如数据倾斜)等。
分配资源不足
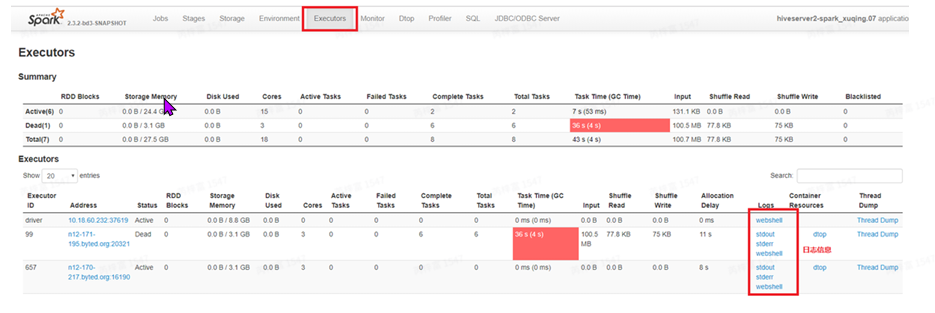
申请的资源不够:executors是否都被占满,通过SparkUI⻚⾯中的Executors信息(如下图), 查看Cores和ActiveTasks,如果ActiveTasks等于或接近Cores,则表⽰申请的资源被占满。当 任务的task较多时,可以适当增加executors数提⾼任务的并⾏度。
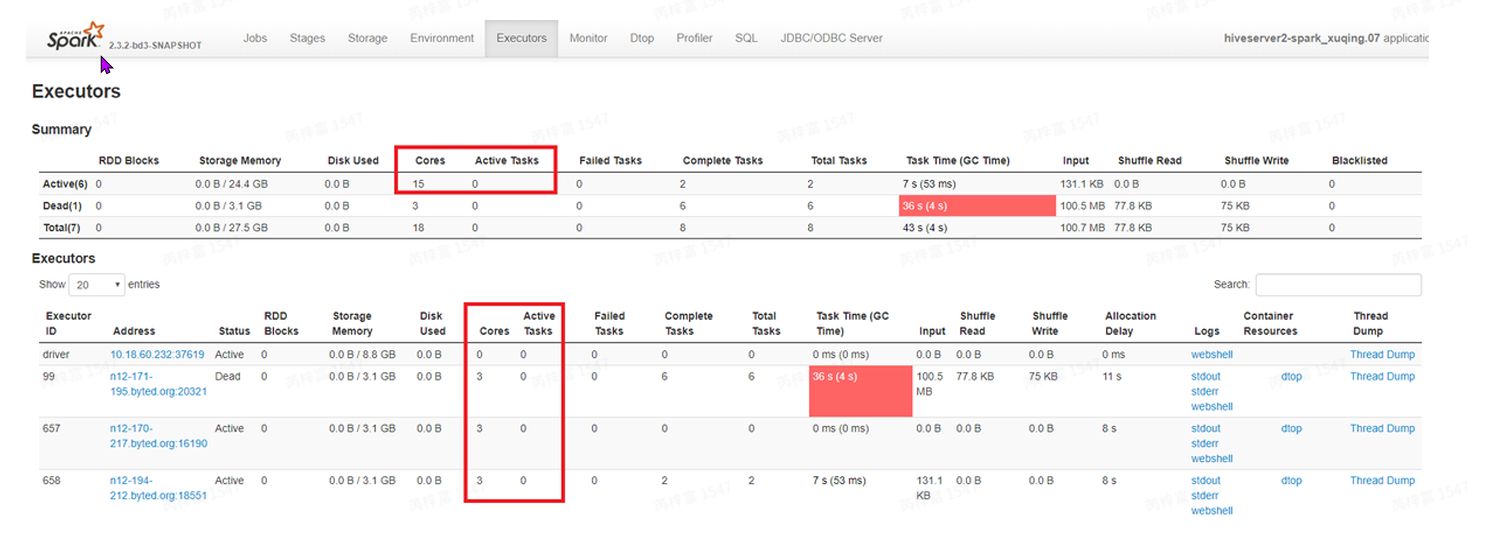
队列资源是否充⾜:上图中Active(6)代表任务向yarn申请到6个executors。如果UI⻚⾯上申 请到的executors数量远⼩于配置的数量(静态资源:spark.executor.instances,动态资源: spark.dynamicAllocation.maxExecutors)
集群节点资源:很多队列共享YARN集群,YARN集群节点负载(cpu,memory,io等)⾼时也会 导致spark任务执⾏缓慢
并发不足
task 并发设置不合理:spark作业shuffle后,tasks数由下⾯的参数控制:
- Spark 原⽣作业:spark.default.parallelism
- Spark sql 任务:spark.sql.shuffle.partitions(默认 200)
- 在开启AE(spark.sql.adaptive.enabled=true) 后,最⼤shuffletasks数由 spark.sql.adaptive.maxNumPostShufflePartitions(默认 500)控制。
如果在SparkUI⻚⾯上查看到某个shufflestage的tasks,duration⽐较⻓且ShuffleReadSize⽐ 较⼤,可以考虑增加调⼤shuffletask数来提⾼任务并⾏度。

Executor内存不⾜
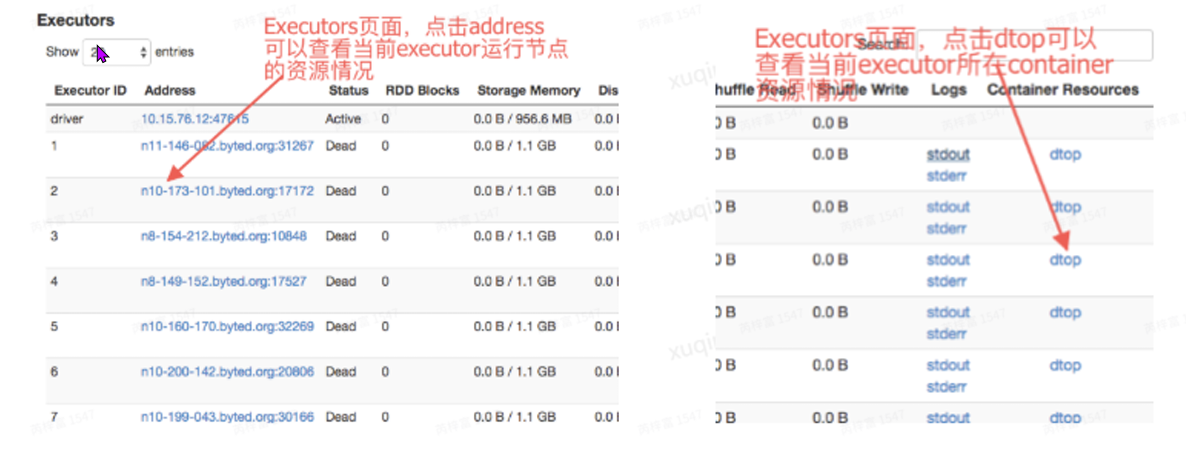
如何判断内存是否⾜够:通过Dtop查看container的资源使⽤,Dtop的Memorytab中⼀般有4个参数
- alloc 是application 向YARN申请的总的内存(executormemory+memoryOverhead)
- jvm_heap_cap是jvm堆的容量(executormemory中)
- jvm_heap_use是jvm堆的真实使⽤量
- used_rss 是实际使⽤的内存(jvm+overhead),保证⼩于alloc,否则会因为超出yarn的资源限 制⽽被kill
注意:python进程运⾏在overheadMemory中,由于不受JVMheap的限制,可能会发⽣抢占 JVMheapmemory⽽导致jvmheap内存不⾜⽽⼤量GC或者OOM的情况,进⽽导致任务运⾏很 慢,或者⼲脆运⾏不起来,此时应该增⼤overhead的内存
当出现以下错误信息时,也表⽰内存不⾜:
Spark UI⻚⾯上显⽰ExecutorLostFailure(executor374exitedcausedbyoneoftherunning tasks) Reason: Container killed by YARN for exceeding memory limits:需要增⼤ spark.yarn.executor.memoryOverhead
数据倾斜
查看每个task的InputSize/Records来判断,如果少数task处理的数据量明显⼤于其他task处理的 数据量,可以参照适当增加task并⾏度,或者找出倾斜的key单独处理(如去掉异常key,在join前 增加groupby进⾏去重等)
join 产⽣笛卡尔积:当⼀个执⾏join操作的stage的task读取的数据量很少但是task执⾏时⻓很 ⻓,且查看执⾏task的线程⼀直在正常RUNNING时,有很⼤概率是join的key不唯⼀(也就是 多对多连接)⽣成笛卡尔积,造成数据扩增了很多倍。这种情况⽬前没有太好的办法解决,只能通 过测试找出倾斜的key,并去重或过滤掉倾斜的key1
读数据阶段慢
案例一
Input Stage 包含较复杂的计算,task数不多,单个task很慢。 这个查询inputstage有复杂的计算,有⼤量的shuffle输出,单个task较慢
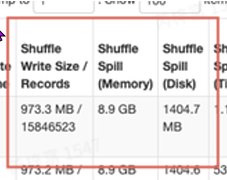
解决⽅式:下调spark.sql.files.maxPartitionBytes 以扩⼤并发为代价,缩短整体运⾏时间,在task数不太多的情况下可以使⽤
案例二
Input Stage 单个task处理数据量很⼩,每个task很快,但task数特别多,时间在调度上浪费很 多。
解决⽅式:
setspark.datasource.splits.max=40000; spark.sql.files.maxPartitionBytes 但参数设置会影响全局,如果要读多个表,可能对其他input stage 造成影响。对于这种情况,可以设置spark.datasource.splits.max,当task数⽬超过设置值, 或重新划分split使之尽可能接近设置值。
例如本例,通过设置set spark.datasource.splits.max=40000,将 task 数从 17W+减少到4W+,单个task数据量增加,但总 体调度时间节约,stage时间明显缩短。
输出⽂件太多
根据上⽅的并发不⾜优化⽅法,可以⽐较⾃由地扩⼤并发度,但可能带来输出⽂件数增多的问题,对 于该现象,提供参数在任务最后执⾏合并,由此可以没有负担地调整上层的并发度。
- set spark.merge.files.enabled = true; // 合并开关
- set spark.merge.files.number = 512; // 合并⽂件数
任务资源占用多
vcore 功能及使⽤说明 虚拟核数,设置⼤于1的数可以使⼀个核分配多个task,对于简单sql可以提升CPU利⽤率,对于复 杂任务有OOM⻛险。
适⽤场景:
- yarn分配队列资源时,基本上是按照1core:4Gmemory的⽐例来分配各队列的资源。当任务申 请的container完全按照1core:4Gmemory的⽐例申请时,队列memory⽤完时core也刚好⽤完。
- 对于⼀些不太消耗内存的简单sql,1core可能2G内存就够了,如果container按照1core:2G memory申请,当队列core⽤完时内存只使⽤了⼀半,core的总数始终受yarn队列的限制。如果开启 vcore=2功能,container申请时仍按照1core:4Gmemory的⽐例,因为vcore的存在实际上1core就 对应了2G内存,这时候队列可⽤的总core变成了原来的两倍。
set spark.vcore.boost=2;
并发度
与上⾯相对,并发不⾜任务会慢,并发多会增⼤资源⽤量,是个需要trade-off的环节
Executor内存
扩⼤内存⽤于计算的⽐例: executor⽤于计算的内存⽐例默认是0.6,即有0.4只⽤于spark的元数据和运⾏信息使⽤不参与计 算,当executor内存较⼤,这部分存在浪费,可以适当调⾼。
set spark.memory.fraction=0.75;缩⼩堆内和堆外内存 ⼩任务executormemory+memoryOverhead也可以调低,具体情况,均需要根据dtop信息适当 调整。
如何使⽤AE优化数据倾斜
set spark.driver.memory=20G; -- 处理数据倾斜时,需要收集额外信息,建议增加driver内存
set spark.sql.adaptive.skewedJoin.enabled=true; -- 总开关
set spark.sql.adaptive.skewedPartitionSizeThreshold=52428800; -- size阈值
set spark.sql.adaptive.skewedPartitionRowCountThreshold=5000000; -- record count阈值
set spark.sql.adaptive.skewedPartitionFactor=3; -- 超过中位数N倍数后,判断为数据倾斜(record count or size )
set spark.sql.adaptive.skewedPartitionMaxSplits=6; -- 倾斜后,拆分的task数量
set spark.shuffle.statistics.verbose=true; -- 收集shuffle统计信息
-- 如果shuffle partition数量超过2000后,需要额外设置以下参数:
set spark.shuffle.accurateBlockThreshold=4000000;
set spark.shuffle.accurateBlockRecordThreshold=500000;
-- 原因说明:partition不⾜2000时,spark会精确收集每个partition的统计信息;超过2000后,对于⼩于上述两个阈值的partition不予收集,使⽤平均值代替,从⽽导致中位数计算不准确,造成数据倾斜识别错误数据倾斜判断条件
- task处理的数据量(size:单位byte)⼤于 spark.sql.adaptive.skewedPartitionFactor*mediamSize并且数据量⼤于 spark.sql.adaptive.skewedPartitionSizeThreshold设置的值
- task 处理的记录数(count)⼤于spark.sql.adaptive.skewedPartitionFactor*mediamCount并且 记录数⼤于spark.sql.adaptive.skewedPartitionRowCountThreshold 设置的值
- 1 和2满⾜⼀条即可
Shuffle失败
报错 FetchFailedException, 主要原因 Shuffle数据所在机器忙,⽆法及时响应ShuffleFetch请求
解决⽅案
如果Job 执⾏时间超过半⼩时,可以通过如下配置解决
--conf spark.shuffle.hdfs.enabled=true
--conf spark.shuffle.io.maxRetries=1
--conf spark.shuffle.io.retryWait=0s
--conf spark.network.timeout=120s打开Spark重试策略
set spark.yarn.maxAppAttempts=2;原⽣Spark参数 spark.yarn.maxAppAttempts 默认value为3,Spark任务失败后,会重试3次, 包括OOM,解析异常等错误原因。⼤部分情况下,SparkSQL任务重试是不会成功的,会浪费计算时 间。因此TQS相关任务参数 spark.yarn.maxAppAttempts 均设置为1。
常用资源参数配置
| 参数 | 描述 | 默认值 |
|---|---|---|
| spark.executor.instances | 静态资源下:executor数 | 2 |
| spark.dynamicAllocation.enabled | 动态资源开关 | false |
| spark.dynamicAllocation.maxExecuto rs | 动态资源下:executor的最⼤个数 | 900 |
| spark.executor.memory | 每个executor的内存⼤⼩ | 8g |
| spark.memory.fraction | executor⽤于计算的内存 | 0.6 |
| spark.executor.memoryOverhead | 每个executor的堆外内存⼤⼩,堆外内存主要⽤于 数据IO,对于报堆外OOM的任务要适当调⼤,单位 Mb,与之配合要调⼤executorJVM参数,例如: setspark.executor.memoryOverhead=3072 setspark.executor.extraJavaOptions= XX:MaxDirectMemorySize=2560m | 6144 |
| spark.executor.cores | 每个executor的CPU数 | 4 |
| spark.sql.adaptive.enabled | Adaptiveexecution开关,包含⾃动调整并⾏度, 解决数据倾斜等优化, | true |
| spark.sql.adaptive.minNumPostShuffl ePartitions | AE相关,动态最⼩的并⾏度 | 1 |
| maxNumPostShufflePartitions | AE相关,动态最⼤的并⾏度,对于shuffle量⼤的任 务适当增⼤可以减少每个task的数据量,如1024 | 500 |
| spark.sql.adaptive.join.enabled | AE相关,开启后能够根据数据量⾃动判断能否将 sortMergeJoin转换成broadcastjoin | true |
| spark.sql.adaptiveBroadcastJoinThre shold | AE相关,spark.sql.adaptive.join.enabled设置为 true后会判断join的数据量是否⼩于该参数值,如 果⼩于则能将sortMergeJoin转换成broadcastjoin | spark.sql.auto BroadcastJoin Threshold |
| spark.sql.adaptive.skewedJoin.enabl ed | AE相关,开启后能够⾃动处理join时的数据倾斜 | false |
| spark.sql.files.maxPartitionBytes | 默认⼀个task处理的数据⼤⼩,如果给的太⼩会造 成最终任务task太多 | 2147483648 |
| spark.vcore.boost.ratio | 虚拟核数,设置⼤于1的数可以使⼀个核分配多个 task,对于简单sql可以提升CPU利⽤率,对于复 杂任务有OOM⻛险 | 1 |
| spark.shuffle.hdfs.enabled(⻓任务推 荐) | HDFSbasedSparkShuffle开关,可以提⾼任务容 错性,开启该参数,需要添加配置 spark.shuffle.hdfs.rootDir 对于这种错误: org.apache.spark.shuffle.FetchFailedException, 请使⽤该参数 | false |
| spark.sql.crossJoin.enabled | 对于会产⽣笛卡尔积的sql,默认配置是限制不能跑 的,在hive⾥可以配置set hive.mapred.mode=nonstrict跳过限制,相对应的 在spark⾥可以配置set spark.sql.crossJoin.enabled=true起到同样的效 果。 | true |
| spark.sql.broadcastTimeout | broadcastjoins时,⼴播数据最⻓等待时间,⽹络 不稳定时,容易出现超时造成任务失败,可适当增⼤ 此参数 | 300(单位: s) |
| spark.sql.autoBroadcastJoinThreshol d | 表能够使⽤broadcastjoin的最⼤阈值 | 20971520(20 MB) |
| spark.network.timeout | ⽹络连接超时参数 | 120s |
| spark.maxRemoteBlockSizeFetchToMem | reduce端获取的remoteblock存放到内存的阈值,超过该阈值后数据会写磁盘,当出现数据量⽐较⼤的 block时,建议调⼩该参数(⽐如512MB)。 | Long.MaxValue |
| spark.merge.files.enabled | 是否在写HDFS⽂件前进⾏合并。如果insert结果 的输出⽂件数很多,希望合并,可以设为true,会 多增加⼀个repartitionstage合并⽂件, repartition的分区数由spark.merge.files.number 控制 | false |
| spark.merge.files.number | 上⾯参数为true时⽬标⽂件数 | 512 |
| spark.datasource.splits.max | 第⼀阶段扫表的task上限,⽤⼾可以设置在 50000,task太多会造成下阶段oom。如果task不 够50000,则不做任何事情,否则限制task总数在 50000。 (默认不限制,task数等于总的⽂件⼤⼩除以 spark.sql.files.maxPartitionBytes) | 0(不限制 task上限) |