
Sparksql全流程原理
Sparksql全流程原理
现在的大数据开发很多公司为了效率考虑,大多数使用sql,不管是hive sql 还是spark sql,其执行流程大多很类似,在我的工作中,更多的是使用spark sql来进行作业的开发,所以第一篇,我们先来从整体上分析一下spark sql的执行流程。
1、执行流程概述
sql在转换为RDD执行中会经过如下几个阶段:
词法分析:将输入的SQL语句拆解为单词序列,并识别出关键字、标识、常量等信息;
语法分析:检查词法分析解析出来的单词序列是否满足SQL语法规则;
逻辑计划:语法分析完的结果会生成原始的逻辑计划信息,在这个阶段会进行分析和优化处理,具体会分为如下几个阶段:
物理计划:物理计划会将上一步的逻辑计划进一步转换,生成可以执行的计划信息
如果用一张图展示,那我们开发完一个sql任务,它的总的执行流程是这样的:
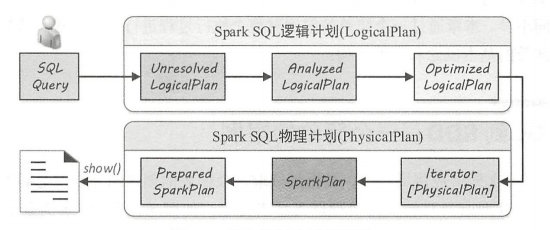
其中每隔个阶段又做了不同的工作:
1.1、Unresolved-未解析阶段
此阶段主要做了两件事:
1、将sql字符串通过antrl4转化成AST逻辑语法树
2、将AST语法树经过spark自定义访问者模式转化成logicalPlan【可以理解为精简版语法树】
该阶段语法树中仅仅是数据结构,不包含任何数据信息
1.2、Analyzed-分析阶段
此阶段会将上一阶段获得的逻辑语法树和元数据进行绑定,构建出更包含元数据的逻辑语法树
如果是hivesql,则此阶段会和hive-catalog进行交互
1.3、Optimized-优化阶段
此阶段是对分析阶段的逻辑计划做进一步优化,将应用各种优化规则对一些低效的逻辑计划进行转换
例如将原本用户不合理的sql进行优化,如谓词下推,列裁剪,子查询共用等。
1.4、PhysicalPlan-物理计划阶段
物理计划阶段将上一步逻辑计划阶段生成的逻辑算子树进行进一步转换,生成物理算子树,物理算子树的节点会直接生成 RDD 或对 RDD 进行 transformation 操作;
1.5、Cost-Model-策略选取阶段
Cost Model 对应的就是基于代价的优化(Cost-based Optimizations,CBO,详见 SPARK-16026 ),核心思想是计算每个物理计划的代价,然后得到最优的物理计划。但是截止到spark3.0,这一部分并没有实现
1,6、Prepared-预提交阶段
此节点是提交前的优化,内部是同的规则作用在sparkPlan物理树,从而获得优化后的可执行的物理树。
其中有个重头戏,就是spark3.0中新增功能AQE【自适应执行】,SPARK-9850 在 Spark 中提出了自适应执行的基本思想,关于功能实现不在这里过多陈述,可查看相关文献;由此可以看出AQE功能目前只能通过sparksql才能使用
2、sparksql读取pg数据
接下来我们将从postgresql数据库中读取一张表数据,表结构如下:
+---+------+-----------------+-----+------+------+--------+--------+-------------------+
|cid| cname| caddress|ccity|cstate| czip|ccountry|ccontact| cemail|
+---+------+-----------------+-----+------+------+--------+--------+-------------------+
| 1| 马云| 大马路一号| 杭州| 浙江|110120| 中国| 阿云| mayun@alibaba.com|
| 2|刘强东|中关村上地一街2号| 北京| 北京|100000| 中国|奶茶妹妹|liuqiangdong@jd.com|
| 3|马化腾| 你懂得| 东莞| 广东|300000| 中国| 马化腾| mahuateng@qq.com|
+---+------+-----------------+-----+------+------+--------+--------+-------------------+从sparksql读取数据库中的数据开始:
val sql =
"""
|select * from cust where cid <=2 and cname != '刘强东'
|""".stripMargin
session.sql(sql).show()
session.sql(sql).explain(true)spark.sql 来自 SparkSession.scala 文件,我们来看看具体的源码:
/**
* 使用Spark执行SQL查询,并将结果作为“DataFrame”返回。
*/
def sql(sqlText: String): DataFrame = {
//下面这个方法总共做了两步
// 1 parsing 阶段
// 2 parsing 阶段生成的逻辑计划经过处理生成 DataFrame 返回
Dataset.ofRows(self, sessionState.sqlParser.parsePlan(sqlText))
}在.ofRows()方法中,有一个参数sessionState,这个对象里面存储了sql在执行期间的所有数据状态,所以接下来详细介绍这个对象。
3、SessionState
3.1、介绍
Apache Spark 2.0引入了SparkSession,其目的是为用户提供了一个统一的切入点来使用Spark的各项功能,不再需要显式地创建SparkConf, SparkContext 以及 SQLContext,因为这些对象已经封装在SparkSession中。此外SparkSession允许用户通过它调用DataFrame和Dataset相关API来编写Spark程序。
那么在sparkSql模块中,sql各个阶段的解析的核心类则是SessionState,在后续的文章中会多次使用到SessionState的变量,故本节将介绍SessionState是如何构建的
3.2、sparksession的创建
// TODO 创建SparkSQL的运行环境
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("sparkSQL")
val spark = SparkSession.builder().config(sparkConf)
.getOrCreate()
// hive如下:
val spark = SparkSession.builder().config(sparkConf)
.enableHiveSupport()
.getOrCreate()可以看到,sparksession的创建使用的创建者设计模式,这样spark就可以使用.config()的方法配置属性然后构建对象。
3.2.1、getOrCreate()
def getOrCreate(): SparkSession = synchronized {
// SparkSession只能在Driver端创建和访问
assertOnDriver()
// 首先检查是否存在有效的线程本地SparkSession,如果session不为空,
//且session对应的sparkContext未停止了,返回现有session
// Get the session from current thread's active session.
var session = activeThreadSession.get()
if ((session ne null) && !session.sparkContext.isStopped) {
applyModifiableSettings(session)
return session
}
// 线程同步执行
// Global synchronization so we will only set the default session once.
SparkSession.synchronized {
// 如果当前线程没有活动会话,请从全局会话获取它
// If the current thread does not have an active session, get it from the global session.
session = defaultSession.get()
if ((session ne null) && !session.sparkContext.isStopped) {
applyModifiableSettings(session)
return session
}
// 没有活动或全局默认会话。创建一个新的sparkContext
// No active nor global default session. Create a new one.
val sparkContext = userSuppliedContext.getOrElse {
val sparkConf = new SparkConf()
options.foreach { case (k, v) => sparkConf.set(k, v) }
// set a random app name if not given.
if (!sparkConf.contains("spark.app.name")) {
sparkConf.setAppName(java.util.UUID.randomUUID().toString)
}
SparkContext.getOrCreate(sparkConf)
// Do not update `SparkConf` for existing `SparkContext`, as it's shared by all sessions.
}
// Initialize extensions if the user has defined a configurator class.
val extensionConfOption = sparkContext.conf.get(StaticSQLConf.SPARK_SESSION_EXTENSIONS)
if (extensionConfOption.isDefined) {
val extensionConfClassName = extensionConfOption.get
try {
val extensionConfClass = Utils.classForName(extensionConfClassName)
val extensionConf = extensionConfClass.newInstance()
.asInstanceOf[SparkSessionExtensions => Unit]
extensionConf(extensions)
} catch {
// Ignore the error if we cannot find the class or when the class has the wrong type.
case e @ (_: ClassCastException |
_: ClassNotFoundException |
_: NoClassDefFoundError) =>
logWarning(s"Cannot use $extensionConfClassName to configure session extensions.", e)
}
}
// 重点此处构建SparkSession;extensions入参为自定义扩展类,后面会有一节单独介绍。
session = new SparkSession(sparkContext, None, None, extensions)
options.foreach { case (k, v) => session.initialSessionOptions.put(k, v) }
setDefaultSession(session)
setActiveSession(session)
// Register a successfully instantiated context to the singleton. This should be at the
// end of the class definition so that the singleton is updated only if there is no
// exception in the construction of the instance.
sparkContext.addSparkListener(new SparkListener {
override def onApplicationEnd(applicationEnd: SparkListenerApplicationEnd): Unit = {
defaultSession.set(null)
}
})
}
return session
}3.3、SessionState类
在SparkSession类中有一个核心属性:SessionState,该属性存储着sparksql各个阶段的执行过程,十分重要:
/**
* State isolated across sessions, including SQL configurations, temporary tables, registered
* functions, and everything else that accepts a [[org.apache.spark.sql.internal.SQLConf]].
* If `parentSessionState` is not null, the `SessionState` will be a copy of the parent.
*
* This is internal to Spark and there is no guarantee on interface stability.
*
* @since 2.2.0
*/
@InterfaceStability.Unstable
@transient
lazy val sessionState: SessionState = {
parentSessionState
.map(_.clone(this))
.getOrElse {
val state = SparkSession.instantiateSessionState(
SparkSession.sessionStateClassName(sparkContext.conf),
self)
initialSessionOptions.foreach { case (k, v) => state.conf.setConfString(k, v) }
state
}
}3.3.1、属性
下面是sessionState类的定义,我们可以看看都保存了哪些状态信息。
private[sql] class SessionState(
sharedState: SharedState,
val conf: SQLConf,
val experimentalMethods: ExperimentalMethods,
val functionRegistry: FunctionRegistry,
val udfRegistration: UDFRegistration,
catalogBuilder: () => SessionCatalog,
val sqlParser: ParserInterface,
analyzerBuilder: () => Analyzer,
optimizerBuilder: () => Optimizer,
val planner: SparkPlanner,
val streamingQueryManager: StreamingQueryManager,
val listenerManager: ExecutionListenerManager,
resourceLoaderBuilder: () => SessionResourceLoader,
createQueryExecution: LogicalPlan => QueryExecution,
createClone: (SparkSession, SessionState) => SessionState) {}我们可以看到源码中对这个类的说明:
A class that holds all session-specific state in a given [[SparkSession]].
包含了所有sparksession会话期间的状态信息sharedState:会话期间的共享状态,例如全局视图管理器,外部目录等。
conf:特征的k-v类型的sql配置文件
experimentalMethods:用于添加自定义计划策略和优化器的接口。
functionRegistry:用于管理用户注册的功能的内部目录。
udfRegistration:向用户公开的用于注册用户定义函数的接口。
catalogBuilder:创建用于管理表和数据库状态的内部目录的函数。
sqlParser:从SQL文本中提取表达式、计划、表标识符等的解析器。
analyzerBuilder:用于创建逻辑查询计划分析器的函数,用于解析未解析的属性和关系。
optimizerBuilder:用于创建逻辑查询计划优化器的函数。
planner:将优化的逻辑计划转换为物理计划的计划器。
streamingQueryManager:用于启动和停止流式查询的接口。
listenerManager:用于注册自定义[[QueryExecutionListener]]的接口。
resourceLoaderBuilder:创建会话共享资源加载器以加载JAR、文件等的函数。
createQueryExecution:用于创建QueryExecution对象的函数。
createClone:用于创建会话状态的克隆的函数。
SessionState中包含了很多的属性,这些属性在执行sparksql期间存储各个阶段的数据信息,其中比较重要的有下面几个:
SessionCatalog:
按照 SQL 标准,Catalog 是一个宽泛概念,通常可以理解为一个容器或数据库对象命名空间中的一个层次,主要用来解决命名冲突等问题。
在 Spark SQL 系统中,Catalog 主要于各种函数元信息(数据库、数据表、数据视图、数据分区与函数等)的统一管理。
具体来讲,Spark SQL 中Catalog 体系就是以 SessionCatalog 为主,通过 SparkSession 来提供给外界调用。一般,一个 SparkSession 对应一个SessionCatalog。
本质上,SessionCatalog 起到了一个代理的作用,对底层的元数据信息(例如,Hive Metastore)、临时表信息、视图信息和函数做了封装。
ParserInterface
编译器通用接口,用来将 SQL 语句转换成 AST(抽象语法树),也就是 Unresolved Logical Plan,这个接口中包含对 SQL 语句、Expression 表达式和 TableIdentifier 数据表标识符的解析方法,下面是接口的实现和继承关系:

ParserInterface 有两个主要实现类:
- SparkSqlParser 用于外部调用,我们平常写的 SQL 都是它在解析。
- CatalystSqlParser 用于内部 Catalyst 引擎使用的解析器。
当我们从表中读取数据,未解析的逻辑执行计划是不带任何类型信息的数据。
== Parsed Logical Plan ==
'Project [*]
+- 'Filter (('cid <= 2) && NOT ('cname = 刘强东))
+- 'UnresolvedRelation `cust`Analyzer
提供逻辑查询计划的分析器,这个分析器会使用 SessionCatalog 中的信息将 UnsolvedAttributes 和 UnsolvedRelationships 转换为有类型的对象。
其中,UnsolvedAttributes 保存尚未解析的属性的名称,UnsolvedRelationships 保存尚未在SessionCatalog中查找的关系的名称。
简单来讲,就是将 Unresolved Logical Plan 转化成 Analyzed Logical Plan。
这个过程主要会结合 DataFrame 的 Schema 信息(来自 SessionCatalog),检查下面 3 点:
- 表名称
- 字段名称
- 字段类型
== Analyzed Logical Plan ==
cid: int, cname: string, caddress: string, ccity: string, cstate: string, czip: string, ccountry: string, ccontact: string, cemail: string
Project [cid#0, cname#1, caddress#2, ccity#3, cstate#4, czip#5, ccountry#6, ccontact#7, cemail#8]
+- Filter ((cid#0 <= 2) && NOT (cname#1 = 刘强东))
+- SubqueryAlias `cust`
+- Relation[cid#0,cname#1,caddress#2,ccity#3,cstate#4,czip#5,ccountry#6,ccontact#7,cemail#8] JDBCRelation(public.customer) [numPartitions=1]从上面解析过的执行计划可以看到。已经给读出来的各个字段绑定类型,并且在解析过程中使用的列名是cid#0,子查询的表名是cust.
Optimizer
所有优化器都应该继承的抽象类,包含标准规则批次(扩展优化器可以覆盖它)。
其实例类是 SparkOptimizer
Optimizer 会基于启发式的规则,将 Analyzed Logical Plan 转化成 Optimized Logical Plan 。
其中,启发式的规则主要涉及以下 3 个方面的优化:
- 谓词下推,简单来讲就是把过滤操作尽可能往数据源方向移动,这样可以减少计算存储的负载。
- 列剪裁,简单来讲就是根据列存储格式 footer 中的元数据信息来细粒度提取想要的数据,从而减少 IO 消耗。这里只有列存储格式比如 ORC 或者 Parquet 才能享受这个优化。
- 常量折叠,简单来讲就是把一些可以直接计算得到的结果替换掉本来的表达式,比如 1+1=2 这样的。
== Optimized Logical Plan ==
Filter (((isnotnull(cid#0) && isnotnull(cname#1)) && (cid#0 <= 2)) && NOT (cname#1 = 刘强东))
+- Relation[cid#0,cname#1,caddress#2,ccity#3,cstate#4,czip#5,ccountry#6,ccontact#7,cemail#8] JDBCRelation(public.customer) [numPartitions=1]SparkPlanner
基于既定的规则将逻辑计划转换成具体的物理计划(不涉及执行,只是提前规划),即将Optimized Logical Plan 转化成 Physical Plan。
简单来说,逻辑计划就是“应该做什么”,物理计划就是“具体怎么做”。
物理计划包含 3 个子阶段:
- 首先,根据逻辑算子树,生成物理算子树的列表
- 其次,从列表中按照一定的策略选取最优的物理算子树
- 最后,对选取的物理算子树进行提交前的准备工作,例如,确保分区操作正确、物理算子树节点重用、执行代码生成等,得到 Prepared SparkPlan。
最终生成的是一个 RDD 对象,并将其提交给 Spark Core 来执行。
== Physical Plan ==
*(1) Scan JDBCRelation(public.customer) [numPartitions=1] [cid#0,cname#1,caddress#2,ccity#3,cstate#4,czip#5,ccountry#6,ccontact#7,cemail#8] PushedFilters: [*IsNotNull(cid), *IsNotNull(cname), *LessThanOrEqual(cid,2), *Not(EqualTo(cname,刘强东))], ReadSchema: struct<cid:int,cname:string,caddress:string,ccity:string,cstate:string,czip:string,ccountry:strin...在sessionState里面的者四个方法,就是这个sql的执行流程。
**// The following fields are lazy to avoid creating the Hive client when creating SessionState.
lazy val catalog: SessionCatalog = catalogBuilder()
lazy val analyzer: Analyzer = analyzerBuilder()
lazy val optimizer: Optimizer = optimizerBuilder()
lazy val resourceLoader: SessionResourceLoader = resourceLoaderBuilder()**回到SparkSession构建SessionState过程,可以看到先是通过config的CATALOG_IMPLEMENTATION属性分辨构建出两种SessionState:
1、HiveSessionStateBuilder
2、SessionStateBuilder
//创建sessionstate
@InterfaceStability.Unstable
@transient
lazy val sessionState: SessionState = {
parentSessionState
.map(_.clone(this))
.getOrElse {
// 调用instantiateSessionState函数通过传入的全类名创建session
val state = SparkSession.instantiateSessionState(
SparkSession.sessionStateClassName(sparkContext.conf),
self)
initialSessionOptions.foreach { case (k, v) => state.conf.setConfString(k, v) }
state
}
}
//通过名字区分创建那种session
private def sessionStateClassName(conf: SparkConf): String = {
conf.get(CATALOG_IMPLEMENTATION) match {
case "hive" => HIVE_SESSION_STATE_BUILDER_CLASS_NAME
case "in-memory" => classOf[SessionStateBuilder].getCanonicalName
}
}
/**
* Helper method to create an instance of `SessionState` based on `className` from conf.
* The result is either `SessionState` or a Hive based `SessionState`.
*/
private def instantiateSessionState(
className: String,
sparkSession: SparkSession): SessionState = {
try {
// invoke `new [Hive]SessionStateBuilder(SparkSession, Option[SessionState])`
val clazz = Utils.classForName(className) //通过反射创建session
val ctor = clazz.getConstructors.head
// 注意:这里将hive | in-memory的 className构建成了统一的父类BaseSessionStateBuilder,
并且调用了..build()函数
private def instantiateSessionState(
ctor.newInstance(sparkSession, None).asInstanceOf[BaseSessionStateBuilder].build()
} catch {
case NonFatal(e) =>
throw new IllegalArgumentException(s"Error while instantiating '$className':", e)
}
}看一下BaseSessionStateBuilder的继承关系:
看一下创建sessionstate的build()方法
/**
* Build the [[SessionState]].
*/
def build(): SessionState = {
new SessionState(
session.sharedState,
conf,
experimentalMethods,
functionRegistry,
udfRegistration,
() => catalog,// catalog元数据,后面会在catalog一节单独介绍
sqlParser,// sql解析核心类
() => analyzer,// analyzer阶段核心类
() => optimizer,// optimizer阶段核心类
planner,// 物理计划和锡类
streamingQueryManager,
listenerManager,
() => resourceLoader,
createQueryExecution,
createClone)
}
//创建sql解析器
/**
* Parser that extracts expressions, plans, table identifiers etc. from SQL texts.
*从SQL文本中提取表达式、计划、表标识符等的解析器。
* Note: this depends on the `conf` field.
依赖于配置文件conf
*/
protected lazy val sqlParser: ParserInterface = {
extensions.buildParser(session, new SparkSqlParser(conf))
}
//创建Analyzer解析器
/**
* Logical query plan analyzer for resolving unresolved attributes and relations.
*用于解析未解析属性和关系的逻辑查询计划分析器。
* Note: this depends on the `conf` and `catalog` fields.
注意:这取决于“conf”和“catalog”字段。
*/
protected def analyzer: Analyzer = new Analyzer(catalog, conf) {
override val extendedResolutionRules: Seq[Rule[LogicalPlan]] =
new FindDataSourceTable(session) +:
new ResolveSQLOnFile(session) +:
customResolutionRules
override val postHocResolutionRules: Seq[Rule[LogicalPlan]] =
PreprocessTableCreation(session) +:
PreprocessTableInsertion(conf) +:
DataSourceAnalysis(conf) +:
customPostHocResolutionRules
override val extendedCheckRules: Seq[LogicalPlan => Unit] =
PreWriteCheck +:
PreReadCheck +:
HiveOnlyCheck +:
customCheckRules
}
// 创建optimizer优化器类
/**
* Logical query plan optimizer.
*逻辑查询计划优化器。
* Note: this depends on `catalog` and `experimentalMethods` fields.
注意:这取决于“catalog”和“实验方法”字段。
*/
protected def optimizer: Optimizer = {
new SparkOptimizer(catalog, experimentalMethods) {
override def extendedOperatorOptimizationRules: Seq[Rule[LogicalPlan]] =
super.extendedOperatorOptimizationRules ++ customOperatorOptimizationRules
}
}
// 创建planner物理计划类
/**
* Planner that converts optimized logical plans to physical plans.
*将优化的逻辑计划转换为物理计划的计划器。
* Note: this depends on the `conf` and `experimentalMethods` fields.
*/
protected def planner: SparkPlanner = {
new SparkPlanner(session.sparkContext, conf, experimentalMethods) {
override def extraPlanningStrategies: Seq[Strategy] =
super.extraPlanningStrategies ++ customPlanningStrategies
}
}至此sql各个阶段的核心类创建准备完成,每种核心类的使用会在后面各个阶段的文种中详细展开,请关注下节内容。
最后我们在回顾一下上面的流程,发现上面的 4 个类/接口对应的就是前面提到的 4 大阶
将这 4 个阶段串联起来,就得到了 Spark SQL 最基本的工作流程:
注:此处给出的是基本的工作流程,其中不包含 AQE(自适应查询执行), CBO(基于成本的优化),WSCG(全阶段代码生成)等,完整的流程会在最后一讲讲完上述几个概念之后再给出。