
高并发问题解决思路
高并发问题解决思路
高并发系统要关注的问题
对数据化的指标要有概念:清楚选择什么样的指标来衡量高并发系统【QPS/TPS】,理解并发量和QPS,了解自己系统的总用户量、活跃用户量,平峰和高峰时的QPS和TPS等关键数据。
详细了解设计方案的细节:比如读性能有瓶颈会引入缓存,但是忽视了缓存命中率、热点key、数据一致性等问题。
高并发设计不等同于性能优化:不能只从并发编程、多级缓存、异步化、水平扩容考虑而忽视高可用设计、服务治理和运维保障。
了解处理高并发问题的大方案及思路:比如垂直分层、水平分区、缓存等大思路,还要分析数据结构是否合理,算法是否高效,没想过从最根本的IO和计算两个维度去做细节优化。
高并发系统宏观目标
高并发绝不意味着只追求高性能,这是很多人片面的理解。从宏观角度看,高并发系统设计的目标有三个:高性能、高可用,以及高可扩展。
1、高性能:性能体现了系统的并行处理能力,同一时刻处理请求越多意味着并发能力越强,在有限的硬件投入下,提高性能意味着节省成本。同时,性能也反映了用户体验,响应时间分别是100毫秒和1秒,给用户的感受是完全不同的。
2、高可用:表示系统可以正常服务的时间。一个全年不停机、无故障;另一个隔三差五出线上事故、宕机,用户肯定选择前者。另外,如果系统只能做到90%可用,也会大大拖累业务。
3、高扩展:表示系统的扩展能力,流量高峰时能否在短时间内完成扩容,更平稳地承接峰值流量,比如双11活动、明星离婚等热点事件。
这3个目标是需要通盘考虑的,因为它们互相关联、甚至也会相互影响。
比如说:考虑系统的扩展能力,你会将服务设计成无状态的,这种集群设计保证了高扩展性,其实也间接提升了系统的性能和可用性。
再比如说:为了保证可用性,通常会对服务接口进行超时设置,以防大量线程阻塞在慢请求上造成系统雪崩,那超时时间设置成多少合理呢?一般,我们会参考依赖服务的性能表现进行设置。
微观目标
再从微观角度来看,高性能、高可用和高扩展又有哪些具体的指标来衡量?为什么会选择这些指标呢?
性能指标
通过性能指标可以度量目前存在的性能问题,同时作为性能优化的评估依据。一般来说,会采用一段时间内的接口响应时间作为指标。
1、平均响应时间:最常用,但是缺陷很明显,对于慢请求不敏感。比如1万次请求,其中9900次是1ms,100次是100ms,则平均响应时间为1.99ms,虽然平均耗时仅增加了0.99ms,但是1%请求的响应时间已经增加了100倍。
2、TP90、TP99等分位值:将响应时间按照从小到大排序,TP90表示排在第90分位的响应时间, 分位值越大,对慢请求越敏感。
3、吞吐量:和响应时间呈反比,比如响应时间是1ms,则吞吐量为每秒1000次。
通常,设定性能目标时会兼顾吞吐量和响应时间,比如这样表述:在每秒1万次请求下,AVG控制在50ms以下,TP99控制在100ms以下。对于高并发系统,AVG和TP分位值必须同时要考虑。
另外,从用户体验角度来看,200毫秒被认为是第一个分界点,用户感觉不到延迟,1秒是第二个分界点,用户能感受到延迟,但是可以接受。
因此,对于一个健康的高并发系统,TP99应该控制在200毫秒以内,TP999或者TP9999应该控制在1秒以内。
吞吐量通常以每秒请求数(RPS)或每秒事务数(TPS)来表示。它反映了系统在单位时间内处理请求的能力。吞吐量越高,说明系统处理请求的效率越高
响应时间是指用户从发出请求到接收到系统响应所花费的时间。响应时间越短,用户体验越好。响应时间通常以毫秒(ms)为单位
可用性指标
高可用性是指系统具有较高的无故障运行能力,可用性 = 正常运行时间 / 系统总运行时间,一般使用几个9来描述系统的可用性。

对于高并发系统来说,最基本的要求是:保证3个9或者4个9。原因很简单,如果你只能做到2个9,意味着有1%的故障时间,像一些大公司每年动辄千亿以上的GMV或者收入,1%就是10亿级别的业务影响。
可扩展性指标
面对突发流量,不可能临时改造架构,最快的方式就是增加机器来线性提高系统的处理能力。
对于业务集群或者基础组件来说,扩展性 = 性能提升比例 / 机器增加比例,理想的扩展能力是:资源增加几倍,性能提升几倍。通常来说,扩展能力要维持在70%以上。
但是从高并发系统的整体架构角度来看,扩展的目标不仅仅是把服务设计成无状态就行了,因为当流量增加10倍,业务服务可以快速扩容10倍,但是数据库可能就成为了新的瓶颈。
像MySQL这种有状态的存储服务通常是扩展的技术难点,如果架构上没提前做好规划(垂直和水平拆分),就会涉及到大量数据的迁移。
因此,高扩展性需要考虑:服务集群、数据库、缓存和消息队列等中间件、负载均衡、带宽、依赖的第三方等,当并发达到某一个量级后,上述每个因素都可能成为扩展的瓶颈点。
高并发实践方案
通用设计方案
通用的设计方法主要是从「纵向」和「横向」两个维度出发,俗称高并发处理的两板斧:纵向扩展和横向扩展。
纵向扩展(scale-up)
它的目标是提升单机的处理能力,方案又包括:
1、提升单机的硬件性能:通过增加内存、 CPU核数、存储容量、或者将磁盘 升级成SSD 等堆硬 件 的 方 式 来 提升 。
2、提升单机的软件性能:使用缓存减少IO次数,使用并发或者异步的方式增加吞吐量。
横向扩展(scale-out)
因为单机性能总会存在极限,所以最终还需要引入横向扩展,通过集群部署以进一步提高并发处理能力,又包括以下2个方向:
1、做好分层架构:这是横向扩展的提前,因为高并发系统往往业务复杂,通过分层处理可以简化复杂问题,更容易做到横向扩展。
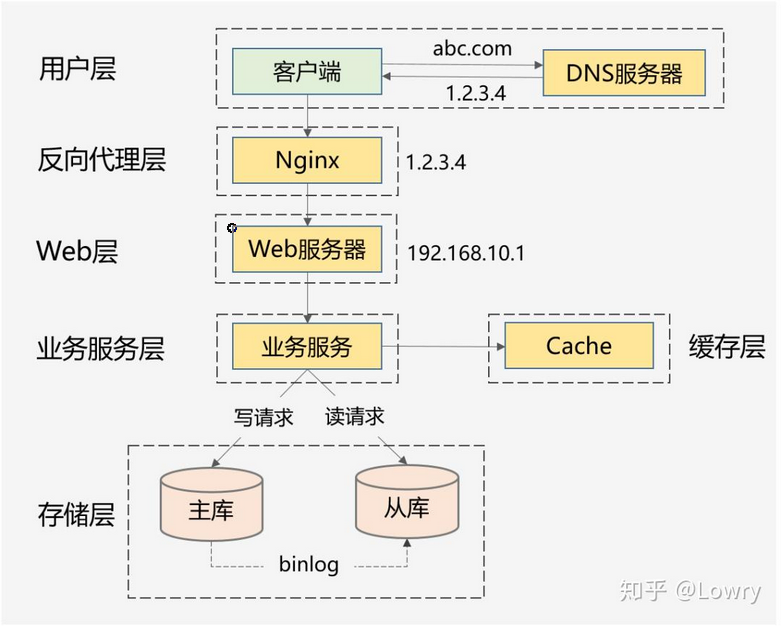
上面这种图是互联网最常见的分层架构,当然真实的高并发系统架构会在此基础上进一步完善。比如会做动静分离并引入CDN,反向代理层可以是LVS+Nginx,Web层可以是统一的API网关,业务服务层可进一步按垂直业务做微服务化,存储层可以是各种异构数据库。
2、各层进行水平扩展:无状态水平扩容,有状态做分片路由。业务集群通常能设计成无状态的,而数据库和缓存往往是有状态的,因此需要设计分区键做好存储分片,当然也可以通过主从同步、读写分离的方案提升读性能。
具体实践方案
下面结合工作中的实际情况,针对高性能,高可用,高可扩展性总结以下可以落地的技术:
高性能部署
1、集群部署,通过负载均衡减轻单机压力。
2、多级缓存,包括静态数据使用CDN、本地缓存、分布式缓存等,以及对缓存场景中的热点key、缓存穿透、缓存并发、数据一致性等问题的处理。
3、分库分表和索引优化,以及借助搜索引擎解决复杂查询问题。
4、考虑NoSQL数据库的使用,比如HBase、TiDB等,但是团队必须熟悉这些组件,且有较强的运维能力。
5、异步化,将次要流程通过多线程、MQ、甚至延时任务进行异步处理。
6、限流,需要先考虑业务是否允许限流(比如秒杀场景是允许的),包括前端限流、Nginx接入层的限流、服务端的限流。
7、对流量进行 削峰填谷 ,通过 MQ承接流量。
8、并发处理,通过多线程将串行逻辑并行化。
9、预计算,比如抢红包场景,可以提前计算好红包金额缓存起来,发红包时直接使用即可。
10、 缓存预热 ,通过异步 任务 提前 预热数据到本地缓存或者分布式缓存中。
11、减少IO次数,比如数据库和缓存的批量读写、RPC的批量接口支持、或者通过冗余数据的方式干掉RPC调用。
12、减少IO时的数据包大小,包括采用轻量级的通信协议、合适的数据结构、去掉接口中的多余字段、减少缓存key的大小、压缩缓存value等。
13、程序逻辑优化,比如将大概率阻断执行流程的判断逻辑前置、For循环的计算逻辑优化,或者采用更高效的算法。
14、各种池化技术的使用和池大小的设置,包括HTTP请求池、线程池(考虑CPU密集型还是IO密集型设置核心参数)、数据库和Redis连接池等。
15、JVM优化,包括新生代和老年代的大小、GC算法的选择等,尽可能减少GC频率和耗时。
16、锁选择,读多写少的场景用乐观锁,或者考虑通过分段锁的方式减少锁冲突。
上述方案无外乎从计算和 IO 两个维度考虑所有可能的优化点,需要有配套的监控系统实时了解当前的性能表现,并支撑你进行性能瓶颈分析,然后再遵循二八原则,抓主要矛盾进行优化。
高可用实践方案
1、对等节点的故障转移,Nginx和服务治理框架均支持一个节点失败后访问另一个节点。
2、非对等节点的故障转移,通过心跳检测并实施主备切换(比如redis的哨兵模式或者集群模式、MySQL的主从切换等)。
3、接口层面的超时设置、重试策略和幂等设计。
4、降级处理:保证核心服务,牺牲非核心服务,必要时进行熔断;或者核心链路出问题时,有备选链路。
5、限流处理:对超过系统处理能力的请求直接拒绝或者返回错误码。
6、MQ场景的消息可靠性保证,包括producer端的重试机制、broker侧的持久化、consumer端的ack机制等。
7、灰度发布,能支持按机器维度进行小流量部署,观察系统日志和业务指标,等运行平稳后再推全量。
8、监控报警:全方位的监控体系,包括最基础的CPU、内存、磁盘、网络的监控,以及Web服务器、JVM、数据库、各类中间件的监控和业务指标的监控。
9、灾备演练:类似当前的“混沌工程”,对系统进行一些破坏性手段,观察局部故障是否会引起可用性问题。
高可用的方案主要从冗余、取舍、系统运维3个方向考虑,同时需要有配套的值班机制和故障处理流程,当出现线上问题时,可及时跟进处理。
高扩展的实践方案
1、合理的分层架构:比如上面谈到的互联网最常见的分层架构,另外还能进一步按照数据访问层、业务逻辑层对微服务做更细粒度的分层(但是需要评估性能,会存在网络多一跳的情况)。
2、存储层的拆分:按照业务维度做垂直拆分、按照数据特征维度进一步做水平拆分(分库分表)。
3、业务层的拆分:最常见的是按照业务维度拆(比如电商场景的商品服务、订单服务等),也可以按照核心接口和非核心接口拆,还可以按照请求源拆(比如To C和To B,APP和H5 )。
实际项目私用方案
分布式架构
整个架构:可采用分布式架构,利用微服务架构拆分服务部署在不同的服务节点,避免单节点宕机引起的服务不可用!
针对分布式架构下的单个服务,负载均衡:使用nginx等对访问量过大的服务采用负载均衡,实现服务集群,提高服务的最大并发数,防止压力过大导致单个服务的崩溃!
使用中间件
使用消息中间件:对服务之间的数据传输,使用诸如rabbit mq,kafka等等分布式消息队列异步传输,防止同步传输数据的阻塞和数据丢失!
使用分布式缓存
针对读多写少的场景。
95%的业务场景下,可以无脑选择Redis。
除非满足如下两种条件可以考虑本地缓存:
- 大key,且热key,网络可能会成为瓶颈。
- 基本上不会进行更改。
缓存预热:通过增加多级缓存实现,提前将一些基础数据预热到缓存中,不要大量请求访问数据库。
异步优化
异步(Asynchronnous)化:以异步化方式将交易创建过程中,对于有严格先后调用关系的服务保持顺序执行,对于能够同步执行的所有服务均采用异步化方式处理。阿里巴巴内部使用消息中间件的方式实现了业务处理流程,提高服务的并发处理。 通过异步化被分割的两部分逻辑处理并没有太多事务性的关系,即一般是前面部分的逻辑处理成功后,后面那部分是否成功执行不会对前一部分的处理结果产生影响。
异步其实是保证最终一致性的一种手段,比如扣减库存,在用户成功发生交易后,向队列中发送一个扣减事件,排队进行数据库库存扣减,只要能保证最终结果一致性即可。
乐观锁思路
乐观锁,是相对于“悲观锁”采用更为宽松的加锁机制,大都是采用带版本号(Version)更新。实现就是,这个数据所有请求都有资格去修改,但会获得一个该数据的版本号,只有版本号符合的才能更新成功,其他的返回抢购失败。这样的话,我们就不需要考虑队列的问题,不过,它会增大CPU的计算开销。但是,综合来说,这是一个比较好的解决方案。
降级服务处理
服务降级:如果不是核心链路,那么就把这个服务降级掉。打个比喻,现在的APP都讲究千人千面,拿到数据后,做个性化排序展示,如果在大流量下,这个排序就可以降级掉!
服务限流
限流:就是想在一定时间内把请求限制在一定范围内,保证系统不被冲垮,同时尽可能提升系统的吞吐量。
注意到,有些时候,缓存和降级是解决不了问题的,比如,电商的双十一,用户的购买,下单等行为,是涉及到大量写操作,而且是核心链路,无法降级的,这个时候,限流就比较重要了。
数据库优化
数据库:采用主从复制,读写分离,甚至是分库分表,表数据根据查询方式的不同采用不同的索引比如b tree,hash,关键字段加索引,sql避免复合函数,避免组合排序等,避免使用非索引字段作为条件分组,排序等!减少交互次数,一定不要用select *!
确定业务类型
读操作多:采用垂直扩容方案(redis、CDN)。采用水平扩容没有太大的意义,因为性能的瓶颈不在写操作,所以不需要实时去完成,用更多的服务器来分担压力性价比太低。所以针对单个系统去强化它的读性能就可以了 。
写操作多:采用水平扩容方案(HBase、增加服务器、数据库)。也可以考虑垂直扩容提升单个数据库的性能,但会发现资金与硬盘的IO能力是有限的,所以需要增加更多数据库来分担写的压力。
垂直扩容(纵向扩展)
提高单个服务(服务器、数据库)自身能力
但会增大单个服务中其他软件设施的依赖与管理、服务内部复杂度
水平扩容(横向扩展)
水平扩展其实就是增加服务器数量,部署更多的无状态服务。
对于数据库的话就堆从库,但有一点需要注意,从数据库从库去读取数据,是有主从延迟的,所以对实时性要求比较高的读场景,如:在程序中的一个方法体内的“写后读”,尽量还是要走主库。另外,如果从库过多,会导致主库的负载压力变大和主从延迟变高,这点也需要注意。
但会增加网络、数据库IO开销、管理多个服务器的难度
分布式系统下对单个服务进行扩容就是水平扩展。
分库分表
分库:当数据库服务器的硬件成为瓶颈了,这是可以考虑分库,比如:CPU使用率100%了,IOPS和Load过高了,网卡被打满了,等等。
分表:当硬件资源不是瓶颈,而数据库锁成为瓶颈的时候,可以考虑分表作为方案。其实,数据库中不仅仅有记录锁、间隙锁、Next-Key锁,还有意向锁
在高并发写场景下,解决了热点资源的锁征用问题,基本上就解决了50%的高并发问题。分表又包括垂直分表和水平分表。
垂直分表就是把一些不常用的大字段剥离出去。举个例子:user表中用户名、性别和年龄字段占用的空间不大,地址和个人简介占用的空间较大,但一个数据页的空间是有限的(16k),把一些无用的数据拆分出去,一页就能存放更多行的数据。内存存放更多有用的数据,就减少了磁盘的访问次数,性能就得到提升。
水平分表,因为一张表内的数据太多了, B+ 树的层级就越高,访问的性能就差,所以进行水平拆分。
当然,一旦进行了分库分表,就会带来查询和排序的问题,而合理的分库分表策略可以将此类问题的影响降至最低,或者引入ES去进行复杂场景补充,也是个不错的方案。
MQ消峰
MQ消峰是典型地应对高并发写场景的策略,通常有两种做法:
- 一种是请求来了就直接往MQ里扔,然后再由MQ的消费者按照节奏慢慢进行处理。
- 另一种是请求来了先做其中重要且不耗时的步骤,做完之后再往MQ里扔,MQ的消费者按照节奏慢慢做那些不重要且耗时的步骤。
当然,有一点需要提醒,MQ更多地是解决系统中瞬时高并发的问题。
如果用户的请求量长期居高不下,会导致MQ消费者需要处理的请求越来越多地积压,这时的解决方案就需要放在提升系统处理能力上了。