
零拷贝技术
零拷贝技术
传统IO执行流程
传统的IO拷贝执行流程主要涉及用户空间、内核空间以及硬件之间的数据交互。在这个过程中,数据通常需要从硬盘(或其他存储设备)读取到内核缓冲区,然后再复制到用户缓冲区,最后根据需要将数据发送到网络或其他外部设备。
具体步骤如下:
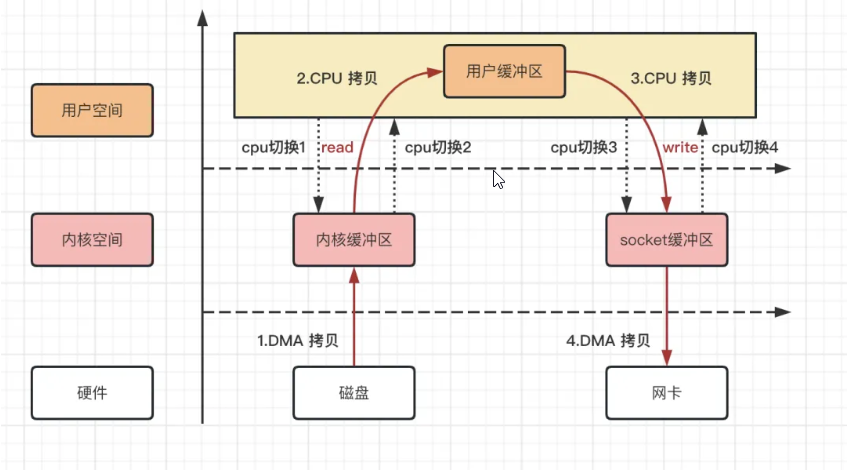
用户进程发起读请求:
- 当用户进程需要读取文件时,它会通过系统调用(如
read())向操作系统发起读请求。 - 此时,用户进程的上下文从用户态切换到内核态。
- 当用户进程需要读取文件时,它会通过系统调用(如
DMA拷贝数据到内核缓冲区:
- 操作系统接收到读请求后,会利用DMA(Direct Memory Access,直接内存存取)控制器将数据从硬盘(或其他存储设备)拷贝到内核缓冲区。
- 这个过程是由DMA控制器完成的,不需要CPU的参与,从而减轻了CPU的负担。
- 操作系统接收到读请求后,会利用DMA(Direct Memory Access,直接内存存取)控制器将数据从硬盘(或其他存储设备)拷贝到内核缓冲区。
CPU拷贝数据到用户缓冲区:
- 数据被DMA拷贝到内核缓冲区后,CPU会将数据从内核缓冲区拷贝到用户缓冲区。
- 这个过程需要CPU的参与,因为它需要执行内存访问指令来完成数据的复制。
- 数据被DMA拷贝到内核缓冲区后,CPU会将数据从内核缓冲区拷贝到用户缓冲区。
用户进程处理数据:
- 数据被拷贝到用户缓冲区后,用户进程可以对其进行处理。
- 此时,用户进程的上下文从内核态切换回用户态。
- 数据被拷贝到用户缓冲区后,用户进程可以对其进行处理。
用户进程发起写请求(如果需要):
- 如果用户进程需要将数据写入到网络或其他外部设备,它会通过系统调用(如
write())向操作系统发起写请求。- 同样,用户进程的上下文会从用户态切换到内核态。
- 如果用户进程需要将数据写入到网络或其他外部设备,它会通过系统调用(如
CPU拷贝数据到socket缓冲区:
- 操作系统接收到写请求后,CPU会将数据从用户缓冲区拷贝到socket缓冲区(或其他设备缓冲区)。
- 这个过程也需要CPU的参与。
- 操作系统接收到写请求后,CPU会将数据从用户缓冲区拷贝到socket缓冲区(或其他设备缓冲区)。
DMA拷贝数据到外部设备:
- 最后,DMA控制器会将数据从socket缓冲区拷贝到网卡(或其他外部设备),完成数据的发送。
- 这个过程同样是由DMA控制器完成的,不需要CPU的参与。
- 最后,DMA控制器会将数据从socket缓冲区拷贝到网卡(或其他外部设备),完成数据的发送。
系统调用返回:
- 当数据成功发送后,系统调用会返回给用户进程,用户进程的上下文从内核态切换回用户态。
从上述过程可以看出总共经历了4 次拷贝次数、4 次上下文切换次数。
其中数据拷贝次数包括2 次 DMA 拷贝,2 次 CPU 拷贝;而CPU 切换次数包括4 次用户态和内核态的切换。
io读写流程
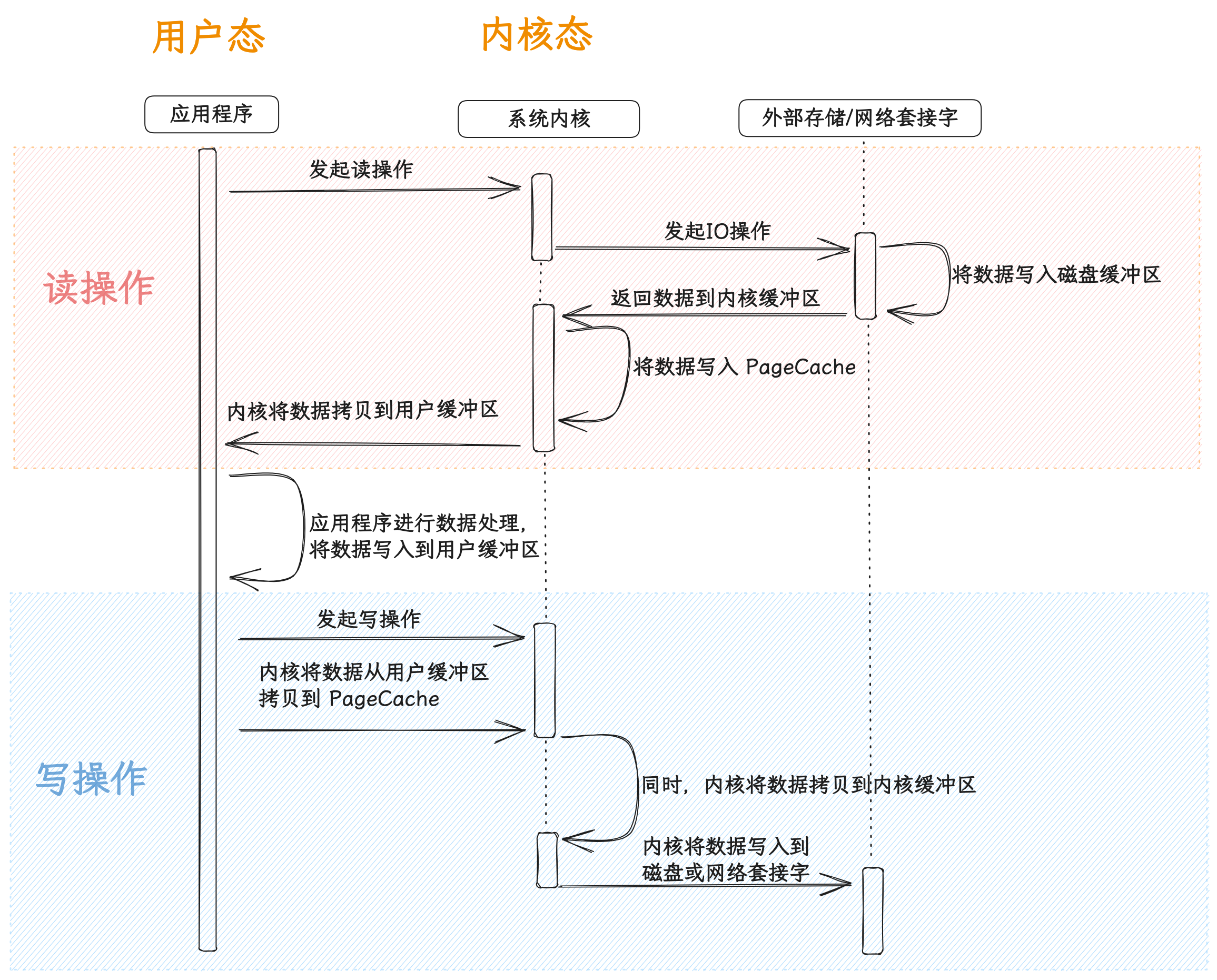
从读写流程中可以看出,一次读写发生了两次用户态和内核态的切换;
内核缓冲区
内核缓冲区指内存中专门用来给内核直接使用的内存空间。可以把它理解为应用程序和外部存储进行数据交互的一个中间介质。
应用程序想要读外部数据,要从这里读。应用程序想要写入外部存储,要通过内核缓冲区。
用户缓冲区
用户缓冲区可以理解为应用程序可以直接读写的内存空间。因为应用程序没法直接到内核读写数据, 所以应用程序想要处理数据,必须先通过用户缓冲区。
磁盘缓冲区
磁盘缓冲区是计算机内存中用于暂存从磁盘读取的数据或将数据写入磁盘之前的临时存储区域。它是一种优化磁盘 I/O 操作的机制,通过利用内存的快速访问速度,减少对慢速磁盘的频繁访问,提高数据读取和写入的性能和效率。
PageCache
+PageCache 是 Linux 内核对文件系统进行缓存的一种机制。它使用空闲内存来缓存从文件系统读取的数据块,加速文件的读取和写入操作。
当应用程序或进程读取文件时,数据会首先从文件系统读取到 PageCache 中。如果之后再次读取相同的数据,就可以直接从 PageCache 中获取,避免了再次访问文件系统。
同样,当应用程序或进程将数据写入文件时,数据会先暂存到 PageCache 中,然后由 Linux 内核异步地将数据写入磁盘,从而提高写入操作的效率。
内核态
- 内核态是操作系统内核运行的模式,当操作系统内核执行特权指令时,处于内核态。
- 在内核态下,操作系统内核拥有最高权限,可以访问计算机的所有硬件资源和敏感数据,执行特权指令,控制系统的整体运行。
- 内核态提供了操作系统管理和控制计算机硬件的能力,它负责处理系统调用、中断、硬件异常等核心任务。
用户态
这里的用户可以理解为应用程序,这个用户是对于计算机的内核而言的,对于内核来说,系统上的各种应用程序会发出指令来调用内核的资源,这时候,应用程序就是内核的用户。
- 用户态是应用程序运行的模式,当应用程序执行普通的指令时,处于用户态。
- 在用户态下,应用程序只能访问自己的内存空间和受限的硬件资源,无法直接访问操作系统的敏感数据或控制计算机的硬件设备。
- 用户态提供了一种安全的运行环境,确保应用程序之间相互隔离,防止恶意程序对系统造成影响。
模式切换
计算机为了安全性考虑,区分了内核态和用户态,应用程序不能直接调用内核资源,必须要切换到内核态之后,让内核来调用,内核调用完资源,再返回给应用程序,这个时候,系统在切换会用户态,应用程序在用户态下才能处理数据。
读写流程瓶颈
首先分析一下读操作:
- 首先应用程序向内核发起读请求,这时候进行一次模式切换了,从用户态切换到内核态;
- 内核向外部存储或网络套接字发起读操作;
- 将数据写入磁盘缓冲区;
- 系统内核将数据从磁盘缓冲区拷贝到内核缓冲区,顺便再将一份(或者一部分)拷贝到 PageCache;
- 内核将数据拷贝到用户缓冲区,供应用程序处理。此时又进行一次模态切换,从内核态切换回用户态;
写操作
- 应用程序向内核发起写请求,这时候进行一次模式切换了,从用户态切换到内核态;
- 内核将要写入的数据从用户缓冲区拷贝到 PageCache,同时将数据拷贝到内核缓冲区;
- 然后内核将数据写入到磁盘缓冲区,从而写入磁盘,或者直接写入网络套接字。
传统的数据读写操作会存在频繁的数据拷贝和用户空间切换,包括以下几个方面:
数据拷贝
在传统 I/O 中,数据的传输通常涉及多次数据拷贝。数据需要从应用程序的用户缓冲区复制到内核缓冲区,然后再从内核缓冲区复制到设备或网络缓冲区。这些数据拷贝过程导致了多次内存访问和数据复制,消耗了大量的 CPU 时间和内存带宽。
用户态和内核态的切换
由于数据要经过内核缓冲区,导致数据在用户态和内核态之间来回切换,切换过程中会有上下文的切换,如此一来,大大增加了处理数据的复杂性和时间开销。
每一次操作耗费的时间虽然很小,但是当并发量高了以后,积少成多,也是不小的开销。所以要提高性能、减少开销就要从以上两个问题下手了。
这时候,零拷贝技术就出来解决问题了。
零拷贝技术原理
零拷贝技术并非指完全没有数据拷贝的过程,而是减少用户态和内核态的切换次数以及CPU拷贝的次数。它通常通过直接内存访问(DMA)技术和内存映射(如mmap)等机制来实现。
- DMA技术:DMA允许硬件设备(如网卡、硬盘控制器等)直接访问内存,而无需CPU的介入。在数据传输过程中,DMA控制器负责将数据从源地址传输到目标地址,从而减少了CPU的拷贝工作。
- 内存映射:内存映射技术将文件或设备的内容映射到进程的地址空间中,使得进程可以直接访问这些数据,而无需通过传统的读/写系统调用。这种方式减少了数据在用户空间和内核空间之间的拷贝次数。
MPP内存映射实现
mmap是Linux内核提供的一种内存映射文件的方式,它可以将一个进程的虚拟地址映射到磁盘文件地址,实现零拷贝。具体来说,mmap通过以下机制实现零拷贝:
mmap的基本原理
mmap技术利用了虚拟内存的特性,将内核中的读缓冲区与用户空间的缓冲区进行映射。这种映射关系建立后,进程可以直接通过访问虚拟内存地址来读写文件内容。
mmap实现零拷贝的过程
映射建立:
- 用户进程通过mmap系统调用,请求将文件的某个部分或全部内容映射到进程的虚拟地址空间。
- 内核响应这个请求,创建映射关系,并将文件的页缓存(page cache)与进程的虚拟内存地址进行绑定。
数据访问:
- 当用户进程访问映射后的虚拟内存地址时,如果对应的内存页尚未加载到物理内存中,会触发缺页异常。
- 内核处理缺页异常,将文件内容从磁盘加载到页缓存,并更新进程的页表,使页表指向页缓存中的相应页。
数据读写:
- 用户进程对映射后的虚拟内存地址进行读写操作,这些操作实际上是对页缓存的读写。
- 由于页缓存与文件内容保持同步,因此这些操作也会反映到文件上。
减少拷贝次数:
- 在传统的文件读写操作中,数据需要从磁盘拷贝到页缓存,再从页缓存拷贝到用户空间缓冲区,最后从用户空间缓冲区拷贝到网络缓冲区或磁盘(如果是写操作)。
- 而使用mmap后,数据只需要从磁盘拷贝到页缓存一次,用户进程可以直接通过映射后的虚拟内存地址访问数据,无需将数据从内核缓冲区拷贝到用户缓冲区这一步。
如下图所示,是一个用户程序通过mmap从磁盘读取数据并通过网络发送出去的过程。
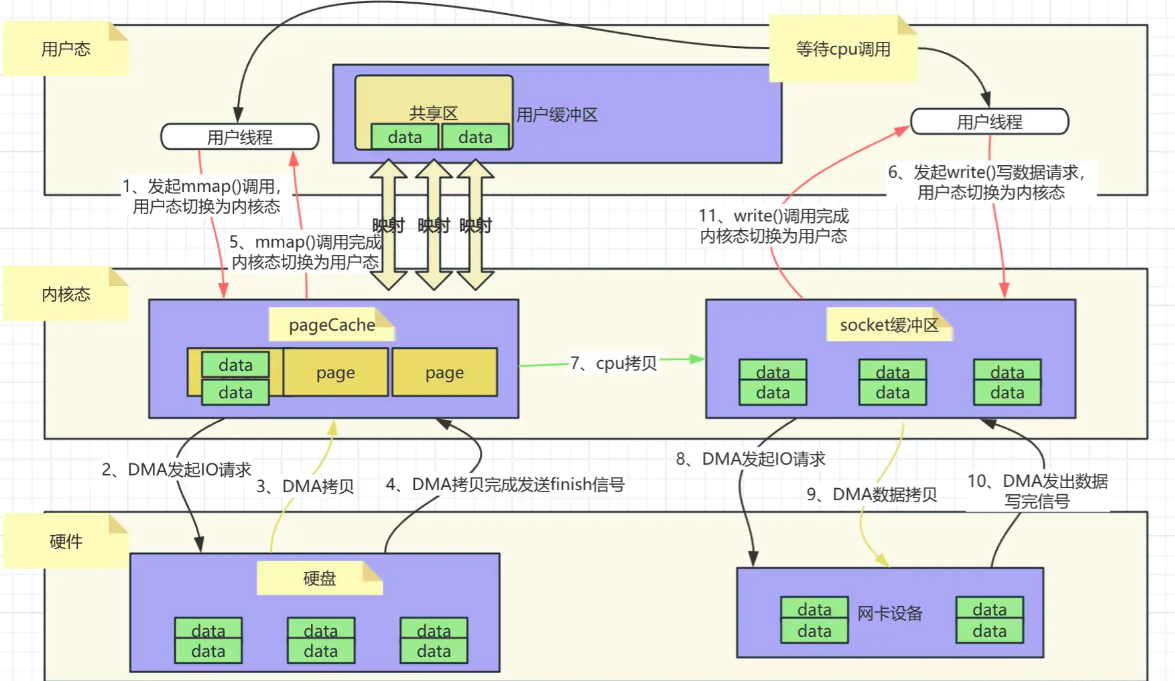
一共发生了2 次 DMA 拷贝,1 次 CPU 拷贝,CPU 切换次数:4 次用户态和内核态的切换。相比于传统的IO流程少了1次CPU拷贝。
mmap零拷贝的优势与限制
优势:
- 减少了数据拷贝次数和上下文切换次数,提高了IO操作的效率。
- 对于大文件传输,mmap可以显著提高性能。
- 提供进程间共享内存及互相通信的方式。不管是父子进程还是无亲缘关系进程,都可以将自身空间用户映射到同一个文件或者匿名映射到同一片区域。从而通过各自映射区域的改动,打到进程间通信和进程间共享的目的。
限制:
- mmap需要占用进程的虚拟地址空间,对于小文件传输,可能会由于文件内容不满一个页而浪费进程的虚拟地址空间,也就是产生碎片空间的浪费。
sendfile系统调用
sendfile原理
sendfile系统调用可以在内核态中直接将文件内容发送到网络设备的缓冲区,避免了数据在用户态和内核态之间的拷贝。
其工作原理如下:
文件描述符:
- sendfile系统调用需要两个文件描述符作为参数:输入文件描述符(in_fd)和输出文件描述符(out_fd)。输入文件描述符指向要发送的文件,输出文件描述符通常指向一个网络套接字。
数据传输:
- 当调用sendfile时,内核会直接从输入文件描述符对应的文件缓冲区中读取数据,并将其发送到输出文件描述符对应的网络缓冲区中。这个过程是在内核态中完成的,无需将数据复制到用户空间。
减少上下文切换和数据复制:
- 使用sendfile系统调用可以减少上下文切换和数据复制的次数。在传统的数据传输方式中,需要多次上下文切换和数据复制。而使用sendfile时,只需一次上下文切换(从用户态切换到内核态进行sendfile调用),并减少了数据在用户空间和内核空间之间的复制。
如下图所示,是一个用户程序通过sendfile从磁盘读取数据并通过网络发送出去的过程。
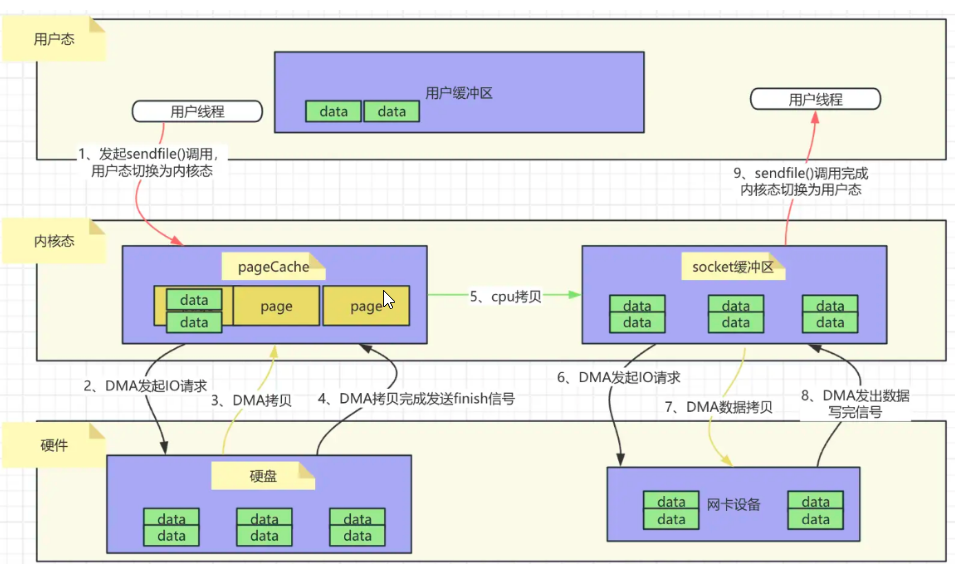
sendfile系统调用的实现细节
DMA(Direct Memory Access):
- 在sendfile系统调用的过程中,DMA技术被用来加速数据传输。DMA允许硬件设备(如磁盘和网络设备)直接访问内存,而无需CPU的介入。这进一步提高了数据传输的效率。
管道和环形缓冲区:
- 在某些实现中,sendfile可能会使用管道和环形缓冲区来优化数据传输。例如,当需要将文件数据拷贝至socket缓冲区时,可以临时创建一个管道(环形缓冲区),将文件数据先拷贝至管道,再将管道数据迁移至socket缓冲区。这个过程并不是真正的数据拷贝,而是将指针指向内存地址。
splice系统调用:
- 从Linux内核2.6.17版本开始,splice系统调用被用来在内部实现sendfile。splice可以将一个文件描述符的数据直接传输到另一个文件描述符,也可以将数据从一个文件描述符传输到网络设备的缓冲区。它支持零拷贝操作,并提供了更灵活的数据传输方式。
整个过程中只发生了2次上下文切换,1次cpu拷贝;相比mmap+write()又节省了2次上下文切换。同时内核缓冲区和用户缓冲区也无需建立内存映射,节省了内存上的占用开销。
直接内存访问(DMA)
DMA 是一种硬件特性,允许外设(如网络适配器、磁盘控制器等)直接访问系统内存,而无需通过 CPU 的介入。在数据传输时,DMA 可以直接将数据从内存传输到外设,或者从外设传输数据到内存,避免了数据在用户态和内核态之间的多次拷贝。
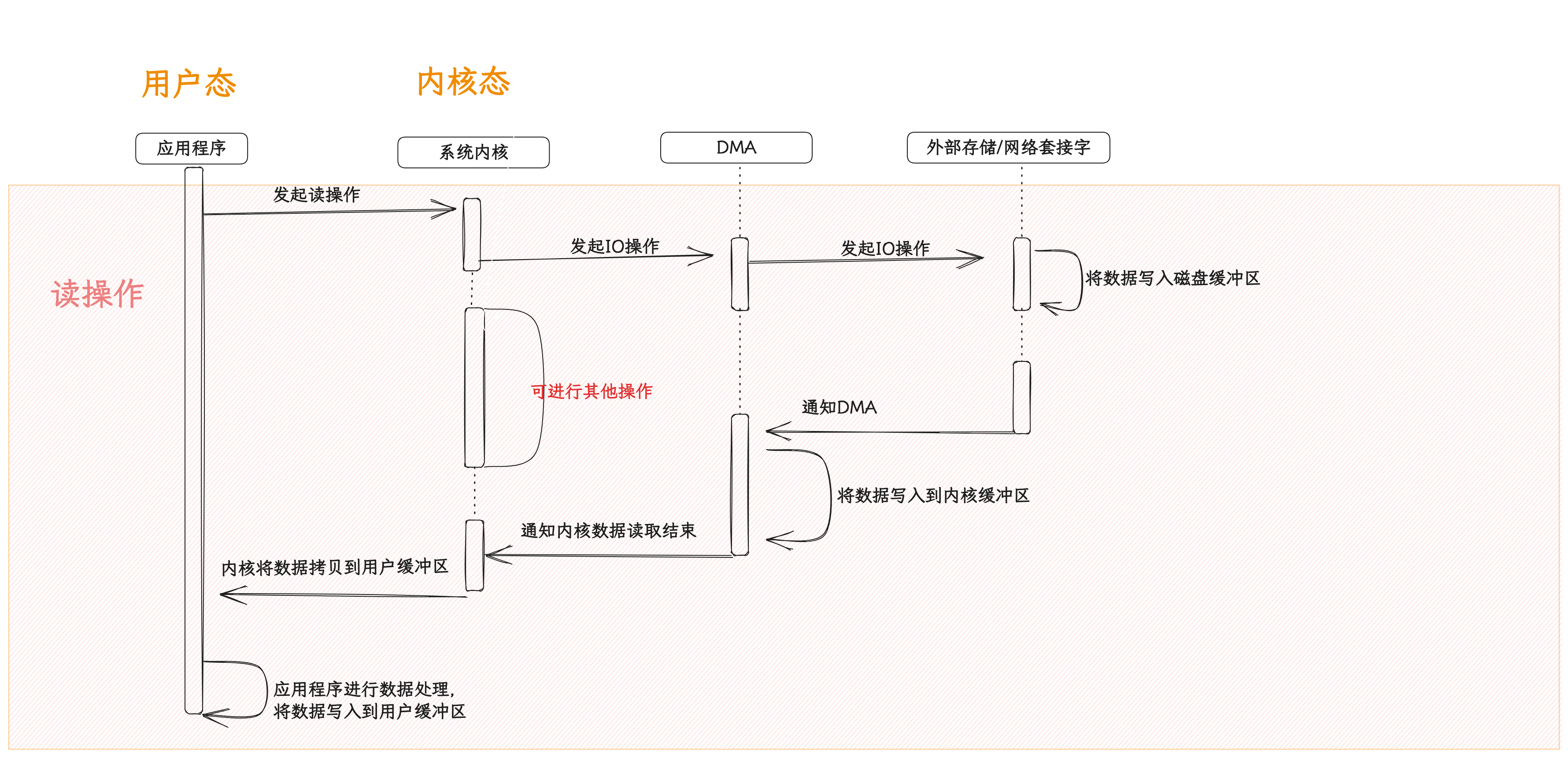
如上图所示,内核将数据读取的大部分数据读取操作都交个了 DMA 控制器,而空出来的资源就可以去处理其他的任务了。
共享内存
使用共享内存技术,应用程序和内核可以共享同一块内存区域,避免在用户态和内核态之间进行数据拷贝。应用程序可以直接将数据写入共享内存,然后内核可以直接从共享内存中读取数据进行传输,或者反之。
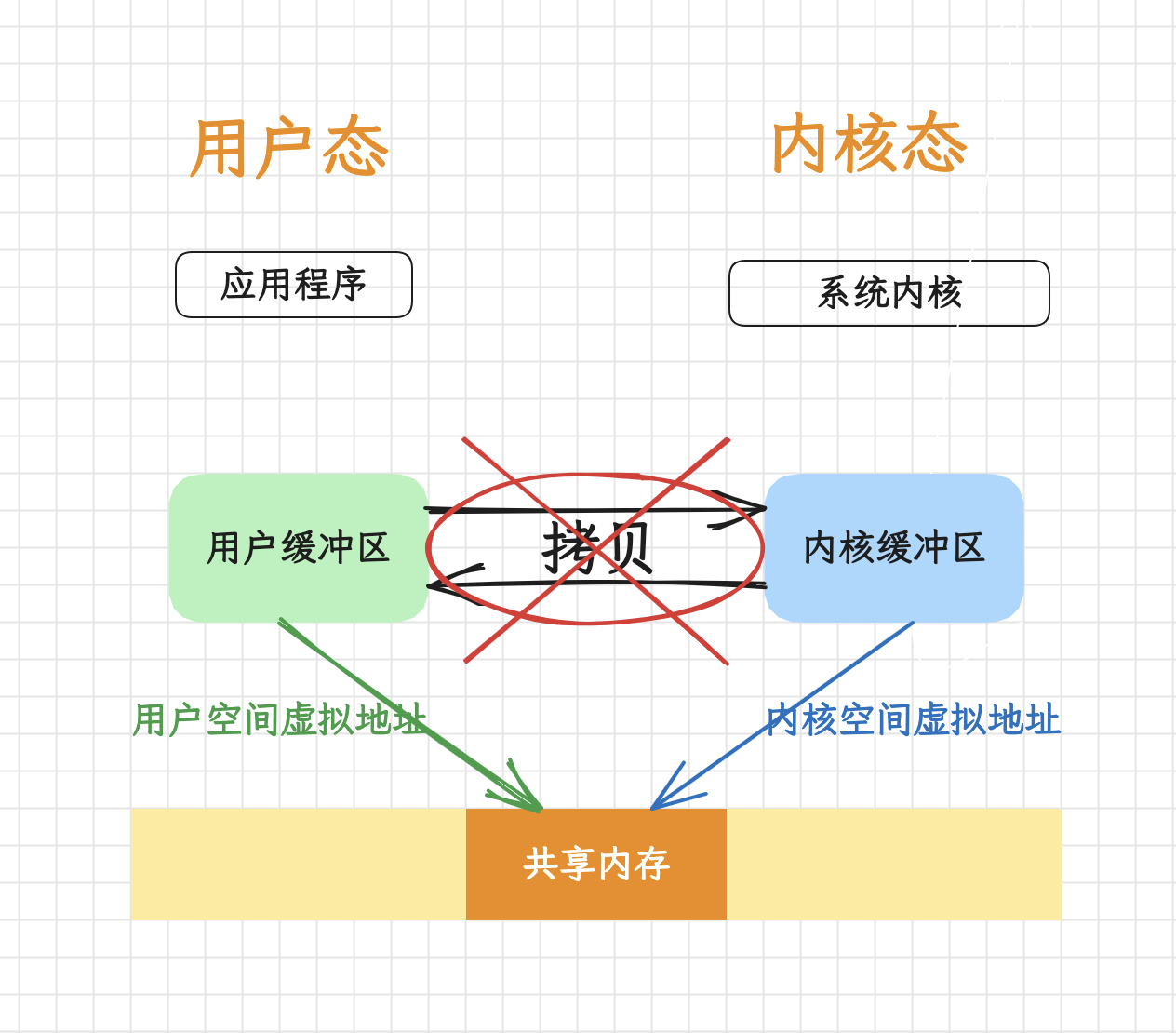
通过共享一块儿内存区域,实现数据的共享。就像程序中的引用对象一样,实际上就是一个指针、一个地址。
性能优化与资源利用
性能优化:
- 零拷贝技术旨在提高数据传输效率,但并非所有情况下都能达到最佳性能。例如,在某些情况下,由于系统资源限制或配置不当,零拷贝技术可能无法充分发挥其优势。
- 在使用零拷贝技术时,应根据具体应用场景和系统环境进行性能优化,如调整系统参数、优化代码逻辑等。
资源利用:
- 零拷贝技术减少了CPU和内存的开销,提高了系统资源利用率。然而,在某些情况下,如果系统资源不足或配置不当,可能会导致性能下降或资源竞争。
- 在使用零拷贝技术时,应确保系统资源得到合理的分配和利用,以避免资源竞争和性能瓶颈。