
分布式锁实现
- 分布式锁
2、分布式锁的各种实现
- 什么是分布式
- 什么是锁
- 什么是分布式锁
- 分布式锁的使用场景-为什么要使用分布式锁
- 分布式锁需要具备哪些功能/条件
- 分布式锁的解决方案
1 分布式锁介绍
1.1 什么是分布式
一个大型的系统往往被分为几个子系统来做,一个子系统可以部署在一台机器的多个 JVM(java虚拟机) 上,也可以部署在多台机器上。但是每一个系统不是独立的,不是完全独立的。需要相互通信,共同实现业务功能。
一句话来说:分布式就是通过计算机网络将后端工作分布到多台主机上,多个主机一起协同完成工作。对共享的变量进行安全的操作。
1.2 什么是锁--作用安全
现实生活中,当我们需要保护一样东西的时候,就会使用锁。例如门锁,车锁等等。很多时候可能许多人会共用这些资源,就会有很多个钥匙。但是有些时候我们希望使用的时候是独自不受打扰的,那么就会在使用的时候从里面反锁,等使用完了再从里面解锁。这样其他人就可以继续使用了。
JAVA程序中,当存在多个线程可以同时改变某个变量(可变共享变量,全区变量,静态变量)时,就需要对变量或代码块做同步,使其在修改这种变量时能够线性执行消除并发修改变量,而同步的本质是通过锁来实现的。
如 Java 中 synchronize 是在对象头设置标记,Lock 接口的实现类基本上都只是某一个 volitile 修饰的 int 型变量其保证每个线程都能拥有对该 int 的可见性和原子修改
1.4 什么是分布式锁
任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),最多只能同时满足两项。CAP
当在分布式模型下,数据只有一份(或有限制),此时需要利用锁的技术控制某一时刻修改数据的进程数。
分布式锁: 在分布式环境下,多个程序/线程都需要对某一份(或有限制)的数据进行修改时,针对程序进行控制,保证同一时间节点下,只有一个程序/线程对数据进行操作的技术。
1.5 分布式锁的真实使用场景
场景一:
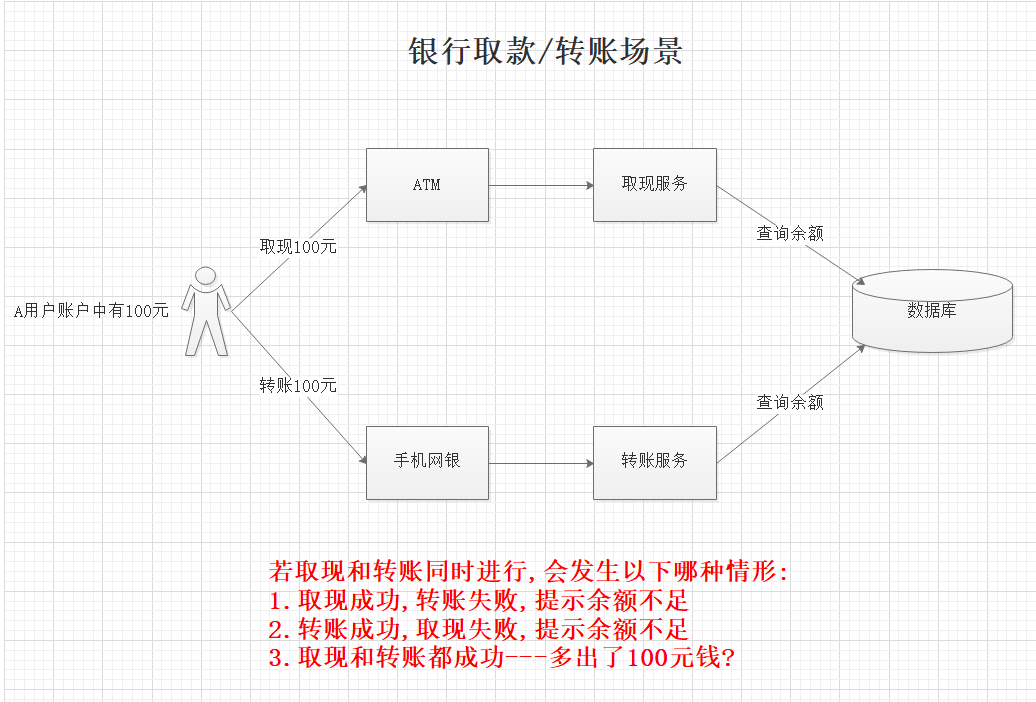
场景二:
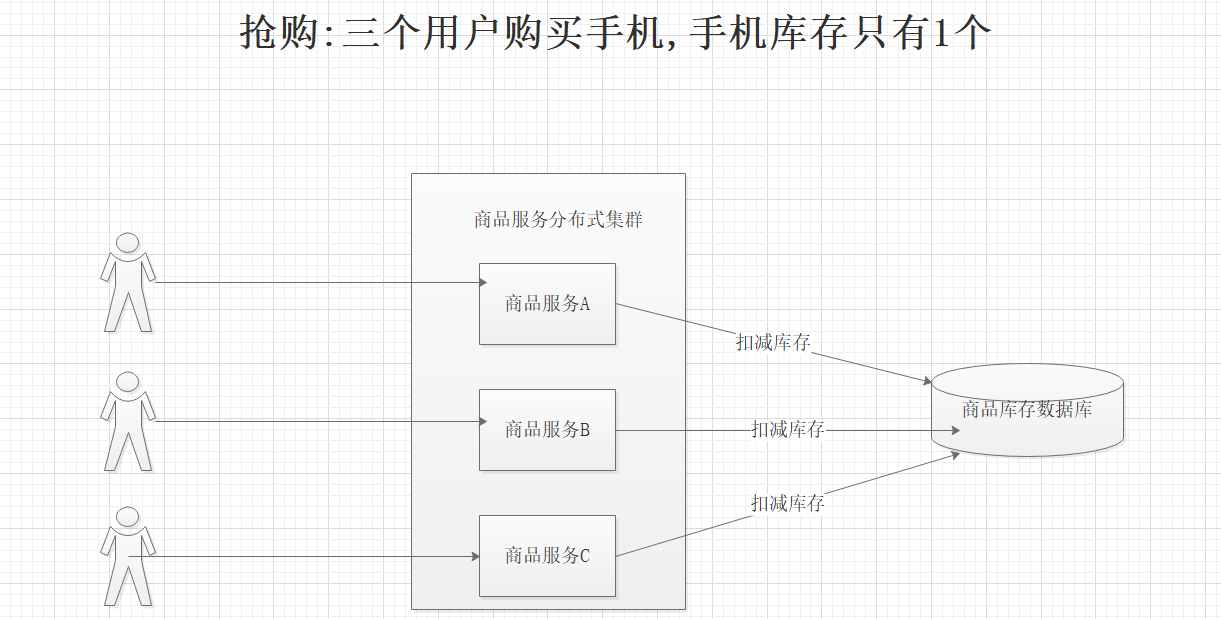
1.5 分布式锁的执行流程
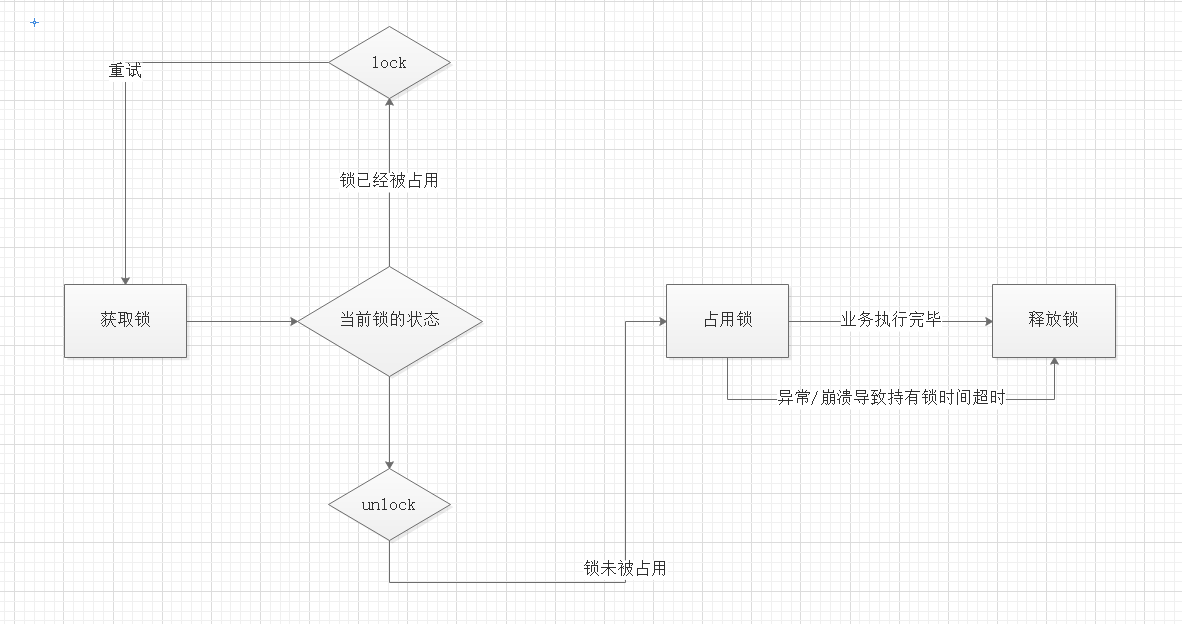
1.6 分布式锁具备的条件
- 互斥性:同一时刻只能有一个服务(或应用)访问资源,特殊情况下有读写锁,可以添加一个等待时间,多长时间获取不到锁就放弃获取锁。
- 原子性:一致性要求保证加锁和解锁的行为是原子性的
- 安全性:锁只能被持有该锁的服务(或应用)释放,谁获取到的锁,谁释放锁。
- 容错性:在持有锁的服务崩溃时,锁仍能得到释放避免死锁,可以添加超时时间或者自动多长时间释放锁。
- 可重用性:同一个客户端获得锁后可递归调用---重入锁和不可重入锁,一个服务可以给同一把锁再次添加锁,但是添加几把锁,释放就释放几次。
- 公平性:看业务是否需要公平,避免饿死--公平锁和非公平锁,使用先来先服务或者是优先级,非公平锁容易产生饿死。
- 支持阻塞和非阻塞:和 ReentrantLock 一样支持 lock 和 trylock 以及 tryLock(long timeOut)---阻塞锁和非阻塞锁PS:::自选锁,阻塞锁获取不到锁的话会一直循环等待,非阻塞锁如果一段时间获取不到锁会放弃获取锁。
- 高可用:获取锁和释放锁 要高可用
- 高性能:获取锁和释放锁的性能要好
- 持久性:锁按业务需要自动续约/自动延期
2.分布式锁的解决方案
2.1 数据库实现分布式锁
2.1.1 基于数据库表实现
准备工作:创建tb_program表,用于记录当前哪个程序正在使用数据
CREATE TABLE `tb_program` (
`program_no` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '程序的编号'
PRIMARY KEY (`program_no`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;实现步骤:
- 程序访问数据时,将程序的编号(insert)存入tb_program表;
- 当insert成功,代表该程序获得了锁,即可执行逻辑;
- 当program_no相同的其他程序进行insert时,由于主键冲突会导致insert失败,则代表获取锁失败;
- 获取锁成功的程序在逻辑执行完以后,删除该数据,代表释放锁。
但是这种方式也存在一些问题
- 这种锁没有失效时间,一旦释放锁的操作失败就会导致锁记录一直在数据库中,其它线程无法获得锁。这个缺陷也很好解决,比如可以做一个定时任务去定时清理。
- 这种锁的可靠性依赖于数据库。建议设置备库,避免单点,进一步提高可靠性。
- 这种锁是非阻塞的,因为插入数据失败之后会直接报错,想要获得锁就需要再次操作。如果需要阻塞式的,可以弄个for循环、while循环之类的,直至INSERT成功再返回。
- 这种锁也是非可重入的,因为同一个线程在没有释放锁之前无法再次获得锁,因为数据库中已经存在同一份记录了。想要实现可重入锁,可以在数据库中添加一些字段,比如获得锁的主机信息、线程信息等,那么在再次获得锁的时候可以先查询数据,如果当前的主机信息和线程信息等能被查到的话,可以直接把锁分配给它。
上面是基于数据库主键的唯一性实现的分布式锁。
2.1.2 基于数据库的排他锁实现
除了可以通过增删操作数据表中的记录以外,其实还可以借助数据中自带的锁来实现分布式的锁。
我们还用刚刚创建的那张数据库表,基于MySql的InnoDB引擎(MYSQL的引擎种类)可以通过数据库的排他锁来实现分布式锁。
当执行带有update for 的sql语句的时候,代表当前连接锁定当前的数据,这个是行锁。表锁,当前连接执行了带有update for的sql语句的时候,就对当前的这张表锁定,只有当前连接才可以操作这张表。上面所说的行锁和表锁都是排它锁。
实现步骤:
- 在查询语句后面增加
for update,数据库会在查询过程中给数据库表增加排他锁。当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁 - 获得排它锁的线程即可获得分布式锁,执行方法的业务逻辑
- 执行完方法之后,再通过
connection.commit();操作来释放锁。
实现代码
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.itheima</groupId>
<artifactId>mysql-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<!--依赖包-->
<dependencies>
<!--核心包-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>5.3.1</version>
</dependency>
<!--一般分词器,适用于英文分词-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>5.3.1</version>
</dependency>
<!--中文分词器-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-smartcn</artifactId>
<version>5.3.1</version>
</dependency>
<!--对分词索引查询解析-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>5.3.1</version>
</dependency>
<!--检索关键字高亮显示-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>5.3.1</version>
</dependency>
<!-- MySql -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.32</version>
</dependency>
<!-- Test dependencies -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>Book
//数据库表
public class Book {
// 图书ID
private Integer id;
// 图书名称
private String name;
// 图书价格
private Float price;
// 图书图片
private String pic;
// 图书描述
private String desc;
}BookDao
public interface BookDao {
/**
* 查询所有的book数据
* @return
*/
List<Book> queryBookList(String name) throws Exception;
}BookDaoImpl实现类
public class BookDaoImpl implements BookDao {
/***
* 查询数据库数据
* @return
* @throws Exception
*/
public List<Book> queryBookList(String name) throws Exception{
// 数据库链接
Connection connection = null;
// 预编译statement
PreparedStatement preparedStatement = null;
// 结果集
ResultSet resultSet = null;
// 图书列表
List<Book> list = new ArrayList<Book>();
try {
// 加载数据库驱动
Class.forName("com.mysql.jdbc.Driver");
// 连接数据库
connection = DriverManager.getConnection("jdbc:mysql://39.108.189.37:3306/lucene", "ybbmysql", "ybbmysql");
//关闭自动提交,否则数据库会自动提交事务
connection.setAutoCommit(false);
// SQL语句
String sql = "SELECT * FROM book where id = 1 for update";
// 创建preparedStatement
preparedStatement = connection.prepareStatement(sql);
// 获取结果集
resultSet = preparedStatement.executeQuery();
// 结果集解析
while (resultSet.next()) {
Book book = new Book();
book.setId(resultSet.getInt("id"));
book.setName(resultSet.getString("name"));
list.add(book);
}
System.out.println(name + "执行了for update");
System.out.println("结果为:" + list);
//锁行后休眠5秒
Thread.sleep(5000);
//休眠结束释放,也就是提交事务
connection.commit();
System.out.println(name + "结束");
} catch (Exception e) {
e.printStackTrace();
}
return list;
}
}测试类
public class Test {
private BookDao bookDao = new BookDaoImpl();
@org.junit.Test
public void testLock() throws Exception {
new Thread(new LockRunner("线程1")).start();
new Thread(new LockRunner("线程2")).start();
new Thread(new LockRunner("线程3")).start();
new Thread(new LockRunner("线程4")).start();
new Thread(new LockRunner("线程5")).start();
Thread.sleep(200000L);
}
class LockRunner implements Runnable {
private String name;
public LockRunner(String name) {
this.name = name;
}
public void run() {
try {
bookDao.queryBookList(name);
}catch (Exception e){
e.printStackTrace();
}
}
}
}执行结果

2.1.3 乐观锁
顾名思义,系统认为数据的更新在大多数情况下是不会产生冲突的,只在数据库更新操作提交的时候才对数据作冲突检测。如果检测的结果出现了与预期数据不一致的情况,则返回失败信息。
乐观锁大多数是基于数据版本(version)的记录机制实现的。何谓数据版本号?
即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表添加一个 “version”字段来实现读取出数据时,将此版本号一同读出,之后更新时,对此版本号加1。在更新过程中,会对版本号进行比较,如果是一致的,没有发生改变,则会成功执行本次操作;如果版本号不一致,则会更新失败。
为了更好的理解数据库乐观锁在实际项目中的使用,这里就列举一个典型的电商库存的例子。
一个电商平台都会存在商品的库存,当用户进行购买的时候就会对库存进行操作(库存减1代表已经卖出了一件)。我们将这个库存模型用下面的一张表optimistic_lock来表述,参考如下:
CREATE TABLE `optimistic_lock` (
`id` BIGINT NOT NULL AUTO_INCREMENT,
`resource` int NOT NULL COMMENT '锁定的资源',
`version` int NOT NULL COMMENT '版本信息',
`created_at` datetime COMMENT '创建时间',
`updated_at` datetime COMMENT '更新时间',
`deleted_at` datetime COMMENT '删除时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uiq_idx_resource` (`resource`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='数据库分布式锁表';其中:id表示主键;resource表示具体操作的资源,在这里也就是特指库存;version表示版本号。
在使用乐观锁之前要确保表中有相应的数据,比如:
INSERT INTO optimistic_lock(resource, version,created_at, updated_at) VALUES(20, 1, CURTIME(), CURTIME());如果只是一个线程进行操作,数据库本身就能保证操作的正确性。主要步骤如下:
STEP1 - 获取资源:SELECT resource FROM optimistic_lock WHERE id = 1
STEP2 - 执行业务逻辑
STEP3 - 更新资源:UPDATE optimistic_lock SET resource = resource -1 WHERE id = 1然而在并发的情况下就会产生一些意想不到的问题:比如两个线程同时购买一件商品,在数据库层面实际操作应该是库存(resource)减2,但是由于是高并发的情况,第一个线程执行之后(执行了STEP1、STEP2但是还没有完成STEP3),第二个线程在购买相同的商品(执行STEP1),此时查询出的库存并没有完成减1的动作,那么最终会导致2个线程购买的商品却出现库存只减1的情况。
在引入了version字段之后,那么具体的操作就会演变成下面的内容:
STEP1 - 获取资源: SELECT resource, version FROM optimistic_lock WHERE id = 1
STEP2 - 执行业务逻辑
STEP3 - 更新资源:UPDATE optimistic_lock SET resource = resource -1, version = version + 1 WHERE id = 1 AND version = oldVersion其实,借助更新时间戳(updated_at)也可以实现乐观锁,和采用version字段的方式相似:更新操作执行前线获取记录当前的更新时间,在提交更新时,检测当前更新时间是否与更新开始时获取的更新时间戳相等。
乐观锁的优点比较明显,由于在检测数据冲突时并不依赖数据库本身的锁机制,不会影响请求的性能,当产生并发且并发量较小的时候只有少部分请求会失败。
缺点是需要对表的设计增加额外的字段,增加了数据库的冗余,另外,当应用并发量高的时候,version值在频繁变化,则会导致大量请求失败,影响系统的可用性。
我们通过上述sql语句还可以看到,数据库锁都是作用于同一行数据记录上,这就导致一个明显的缺点,在一些特殊场景,如大促、秒杀等活动开展的时候,大量的请求同时请求同一条记录的行锁,会对数据库产生很大的写压力。所以综合数据库乐观锁的优缺点,乐观锁比较适合并发量不高,并且写操作不频繁的场景。
2.1.4 悲观锁
除了可以通过增删操作数据库表中的记录以外,我们还可以借助数据库中自带的锁来实现分布式锁。在查询语句后面增加FOR UPDATE,数据库会在查询过程中给数据库表增加悲观锁,也称排他锁。当某条记录被加上悲观锁之后,其它线程也就无法再改行上增加悲观锁。
悲观锁,与乐观锁相反,总是假设最坏的情况,它认为数据的更新在大多数情况下是会产生冲突的。
在使用悲观锁的同时,我们需要注意一下锁的级别。MySQL InnoDB引起在加锁的时候,只有明确地指定主键(或索引)的才会执行行锁 (只锁住被选取的数据),否则MySQL 将会执行表锁(将整个数据表单给锁住)。
在使用悲观锁时,我们必须关闭MySQL数据库的自动提交属性(参考下面的示例),因为MySQL默认使用autocommit模式,也就是说,当你执行一个更新操作后,MySQL会立刻将结果进行提交。
mysql> SET AUTOCOMMIT = 0;这样在使用FOR UPDATE获得锁之后可以执行相应的业务逻辑,执行完之后再使用COMMIT来释放锁。
我们不妨沿用前面的database_lock表来具体表述一下用法。假设有一线程A需要获得锁并执行相应的操作,那么它的具体步骤如下:
STEP1 - 获取锁:SELECT * FROM database_lock WHERE id = 1 FOR UPDATE;。
STEP2 - 执行业务逻辑。
STEP3 - 释放锁:COMMIT。如果另一个线程B在线程A释放锁之前执行STEP1,那么它会被阻塞,直至线程A释放锁之后才能继续。注意,如果线程A长时间未释放锁,那么线程B会报错,(lock wait time可以通过innodb_lock_wait_timeout来进行配置)。
上面的示例中演示了指定主键并且能查询到数据的过程(触发行锁),如果查不到数据那么也就无从“锁”起了。
如果未指定主键(或者索引)且能查询到数据,那么就会触发表锁,比如STEP1改为执行(这里的version只是当做一个普通的字段来使用,与上面的乐观锁无关):
SELECT * FROM database_lock WHERE description='lock' FOR UPDATE;或者主键不明确也会触发表锁,又比如STEP1改为执行:
SELECT * FROM database_lock WHERE id>0 FOR UPDATE;注意,虽然我们可以显示使用行级锁(指定可查询的主键或索引),但是MySQL会对查询进行优化,即便在条件中使用了索引字段,但是否真的使用索引来检索数据是由MySQL通过判断不同执行计划的代价来决定的,如果MySQL认为全表扫描效率更高,比如对一些很小的表,它有可能不会使用索引,在这种情况下InnoDB将使用表锁,而不是行锁。
在悲观锁中,每一次行数据的访问都是独占的,只有当正在访问该行数据的请求事务提交以后,其他请求才能依次访问该数据,否则将阻塞等待锁的获取。
悲观锁可以严格保证数据访问的安全。但是缺点也明显,即每次请求都会额外产生加锁的开销且未获取到锁的请求将会阻塞等待锁的获取,在高并发环境下,容易造成大量请求阻塞,影响系统可用性。
另外,悲观锁使用不当还可能产生死锁的情况。
2.1.5 优点及缺点
**优点:**简单,方便,快速实现
**缺点:**基于数据库,开销比较大,对数据库性能可能会存在影响
2.2 Redis实现分布式锁
Redis把数据存储在内存中,所以速度比较快。
2.2.1 基于 REDIS 的 SETNX()、EXPIRE() 、GETSET()方法做分布式锁
实现原理:
//setnx():setnx 的含义就是 SET if Not Exists,其主要有两个参数 setnx(key, value)。该方法是原子的,如果 key 不存在,则设置当前 key 成功,返回 1;如果当前 key 已经存在,则设置当前 key 失败,返回 0
//返回1表示当前没有锁,返回0表示当前有所//expire():expire 设置过期时间,要注意的是 setnx 命令不能设置 key 的超时时间,只能通过 expire() 来对 key 设置。设置时间主要是防止发生死锁//getset():这个命令主要有两个参数 getset(key,newValue)。该方法是原子的,对 key 设置 newValue 这个值,并且返回 key 原来的旧值。假设 key 原来是不存在的,那么多次执行这个命令,会出现下边的效果:
getset(key, “value1”) 返回 null 此时 key 的值会被设置为 value1
getset(key, “value2”) 返回 value1 此时 key 的值会被设置为 value2
//可以实现由程序自己控制锁的有效时间实现流程:
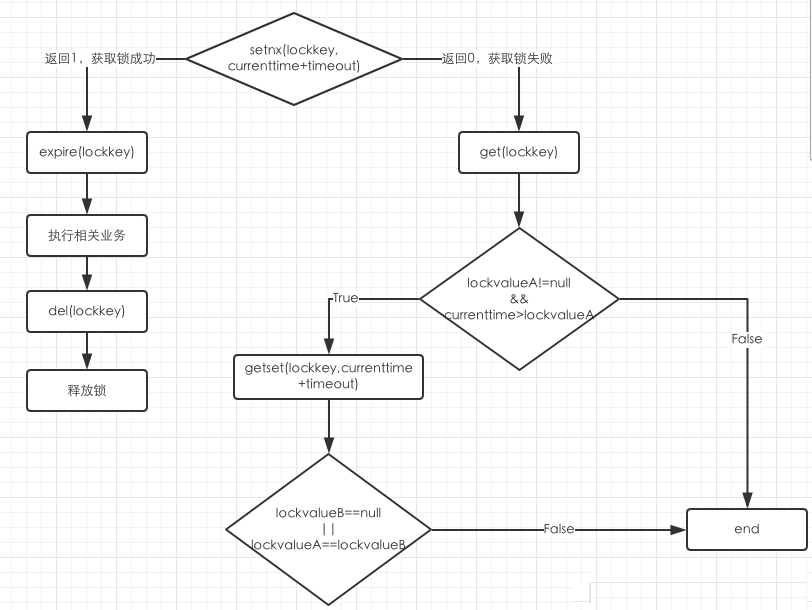
- setnx(lockkey, 当前时间+过期超时时间),如果返回 1,则获取锁成功;如果返回 0 则没有获取到锁。
- get(lockkey) 获取值 oldExpireTime ,并将这个 value 值与当前的系统时间进行比较,如果小于当前系统时间,则认为这个锁已经超时,可以允许别的请求重新获取。
- 计算 newExpireTime = 当前时间+过期超时时间,然后 getset(lockkey, newExpireTime) 会返回当前 lockkey 的值currentExpireTime。判断 currentExpireTime 与 oldExpireTime 是否相等,如果相等,说明当前 getset 设置成功,获取到了锁。如果不相等,说明这个锁又被别的请求获取走了,那么当前请求可以直接返回失败,或者继续重试。
- 在获取到锁之后,当前线程可以开始自己的业务处理,当处理完毕后,比较自己的处理时间和对于锁设置的超时时间,如果小于锁设置的超时时间,则直接执行 delete 释放锁;如果大于锁设置的超时时间,则不需要再锁进行处理。
代码实现
pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.6.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.itheima</groupId>
<artifactId>redis</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>redis</name>
<description>redis实现分布式锁测试</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>RedisUtil工具类
@Component
public class RedisUtil {
//定义默认超时时间:单位毫秒
private static final Integer LOCK_TIME_OUT = 10000;
@Autowired
private StringRedisTemplate stringRedisTemplate;
/**
* 外部调用加锁方法
*/
public Boolean tryLock(String key, Long timeout) throws Exception{
//获取当前系统时间设置为开始时间
Long startTime = System.currentTimeMillis();
//设置返回默认值-false:加锁失败
boolean flag = false;
//死循环获取锁:1.获取锁成功退出 2.获取锁超时退出
while(true){
//判断是否超时
if((System.currentTimeMillis() - startTime) >= timeout){
break;
}else{
//获取锁
flag = lock(key);
//判断是否获取成功
if(flag){
break;
}else{
//休息0.1秒重试,降低服务压力
Thread.sleep(100);
}
}
}
return flag;
}
/**
* 加锁实现
* @param key
* @return
*/
private Boolean lock(String key){
return (Boolean) stringRedisTemplate.execute((RedisCallback) redisConnection -> {
//获取当前系统时间
Long time = System.currentTimeMillis();
//设置锁超时时间
Long timeout = time + LOCK_TIME_OUT + 1;
//setnx加锁并获取解锁结果
Boolean result = redisConnection.setNX(key.getBytes(), String.valueOf(timeout).getBytes());
//加锁成功返回true
if(result){
return true;
}
//加锁失败判断锁是否超时
if(checkLock(key, timeout)){
//getset设置值成功后,会返回旧的锁有效时间
byte[] newtime = redisConnection.getSet(key.getBytes(), String.valueOf(timeout).getBytes());
if(time > Long.valueOf(new String(newtime))){
return true;
}
}
//默认加锁失败
return false;
});
}
/**
* 释放锁
*/
public Boolean release(String key){
return (Boolean) stringRedisTemplate.execute((RedisCallback) redisConnection -> {
Long del = redisConnection.del(key.getBytes());
if (del > 0){
return true;
}
return false;
});
}
/**
* 判断锁是否超时
*/
private Boolean checkLock(String key, Long timeout){
return (Boolean) stringRedisTemplate.execute((RedisCallback) redisConnection -> {
//获取锁的超时时间
byte[] bytes = redisConnection.get(key.getBytes());
try {
//判断锁的有效时间是否大与当前时间
if(timeout > Long.valueOf(new String(bytes))){
return true;
}
}catch (Exception e){
e.printStackTrace();
return false;
}
return false;
});
}
}RedisController测试类
@RestController
@RequestMapping(value = "/redis")
public class RedisController {
@Autowired
private RedisUtil redisUtil;
/**
* 获取锁
* @return
*/
@GetMapping(value = "/lock/{name}")
public String lock(@PathVariable(value = "name")String name) throws Exception{
Boolean result = redisUtil.tryLock(name, 3000L);
if(result){
return "获取锁成功";
}
return "获取锁失败";
}
/**
* 释放锁
* @param name
*/
@GetMapping(value = "/unlock/{name}")
public String unlock(@PathVariable(value = "name")String name){
Boolean result = redisUtil.release(name);
if(result){
return "释放锁成功";
}
return "释放锁失败";
}
}2.2.2 优点及缺点
优点:性能极高
缺点:失效时间设置没有定值。设置的失效时间太短,方法没等执行完锁就自动释放了,那么就会产生并发问题。如果设置的时间太长,其他获取锁的线程就可能要平白的多等一段时间,用户体验会降低。
2.3 zookeeper实现分布式锁
节点分类:
- 持久节点:也就是普通节点。
- 临时节点:当客户端连接zk,就会创建一个临时节点,当客户端退出,就会删除临时节点。临时节点的创建,按照客户端连接的顺序创建。
2.3.1 zookeeper 锁相关基础知识
- zookeeper 一般由多个节点构成(单数),采用 zab 一致性协议。因此可以将 zk 看成一个单点结构,对其修改数据其内部自动将所有节点数据进行修改而后才提供查询服务。
- zookeeper 的数据以目录树的形式,每个目录称为 znode, znode 中可存储数据(一般不超过 1M),还可以在其中增加子节点。
- 子节点有三种类型。
- 序列化节点,每在该节点下增加一个节点自动给该节点的名称上自增。
- 临时节点,一旦创建这个 znode 的客户端与服务器失去联系,这个 znode 也将自动删除。
- 最后就是普通节点。
- Watch 机制,client 可以监控每个节点的变化,当产生变化会给 client 产生一个事件。
2.3.2 zookeeper 分布式锁的原理
- 获取和释放锁原理:利用临时节点与 watch 机制。每个锁占用一个普通节点 /lock,当某一个客户端需要获取锁时在 /lock 目录下创建一个临时节点,创建成功则表示获取锁成功,失败则 watch/lock 节点,有删除操作后再去争锁。临时节点好处在于当进程挂掉后能自动上锁的节点自动删除即取消锁,有其他客户端来申请锁的话,会自动的接着创建临时节点,但是序号不同。
- 获取锁的顺序原理:上锁为创建临时有序节点,每个上锁的节点均能创建节点成功,只是其序号不同。只有序号最小的可以拥有锁,如果这个节点序号不是最小的则 watch 序号比本身小的前一个节点 (公平锁)。
先来先服务,先来的服务可以获取到锁。每一个临时节点存储前一个节点的状态。
临时节点如果断开,就相当于锁就释放了。
2.3.3 zookeeper实现分布式锁流程
简易流程
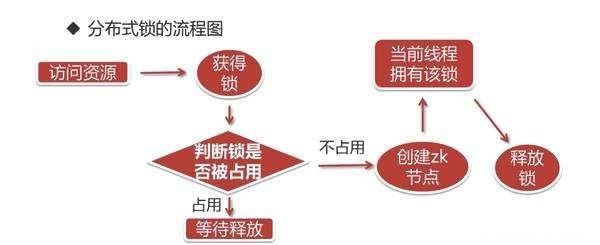
获取锁流程:
- 先有一个锁根节点,lockRootNode,这可以是一个永久的节点
- 客户端获取锁,先在 lockRootNode 下创建一个顺序的临时节点,保证客户端断开连接,节点也自动删除.
- 调用 lockRootNode 父节点的 getChildren() 方法,获取所有的节点,并从小到大排序,如果创建的最小的节点是当前节点,则返回 true,获取锁成功,否则,关注比自己序号小的节点的释放动作(exist watch),这样可以保证每一个客户端只需要关注一个节点,不需要关注所有的节点,避免羊群效应。
- 如果有节点释放操作,重复步骤 3
释放锁流程:
只需要删除步骤 2 中创建的节点即可
2.3.4 排他锁
排他锁( Exclusive Locks,简称Ⅹ锁),又称为写锁或独占锁,是一种基本的锁类型。
如果事务T1对数据对象O1加上了排他锁,那么在整个加锁期间,只允许事务T1对O1进行读取和更新操作,其他任何事务都不能再对这个数据对象进行任何类型的操作直到T1释放了排他锁.
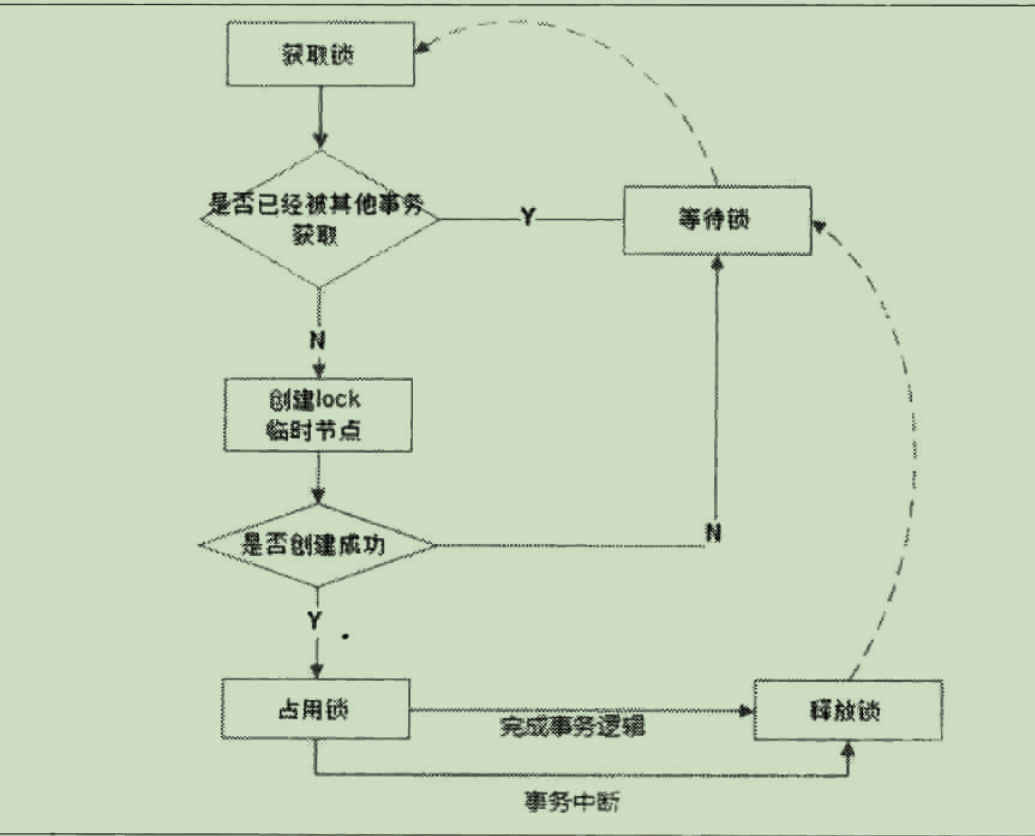
在通常的Java开发编程中,有两种常见的方式可以用来定义锁,分别是synchronized机制和JDK5提供的 ReentrantLock。然而,在 ZooKeeper中,没有类似于这样的API可以直接使用,而是通过 ZooKeeper上的数据节点来表示一个锁,例如/ exclusive_lockl/lock节点就可以被定义为一个锁,如图6-14所示。

获取锁
在需要获取排他锁时,所有的客户端都会试图通过调用 create()接口,在/exclusive_lock节点下创建临时子节点 exclusive_lock/lock。Zooκeper会保证在所有的客户端中,最终只有一个客户端能够创建成功,那么就可以认为该客户端获取了锁。同时,所有没有获取到锁的客户端就需要到/exclusive_lock节点上注册一个子节点变更的 Watcher监听,以便实时监听到lock节点的变更情况。
释放锁
在“定义锁”部分,我们已经提到, exclusive_lockl/lock是一个临时节点,因此在以下两种情况下,都有可能释放锁。
- 当前获取锁的客户端机器发生宕机,那么 ZooKeeper上的这个临时节点就会被移除。
- 正常执行完业务逻辑后,客户端就会主动将自己创建的临时节点删除。
无论在什么情况下移除了lock节点, ZooKeeper都会通知所有在/exclusive_lock节点上注册了子节点变更 Watcher监听的客户端。这些客户端在接收到通知后,再次重新发起分布式锁获取,即重复“获取锁”过程。整个排他锁的获取和释放流程可以用下图表示。
2.3.5 共享锁
共享锁( Shared Locks,简称S锁),又称为读锁,同样是一种基本的锁类型。如果事务T对数据对象O加上了共享锁,那么当前事务只能对O进行读取操作,其他事务也只能对这个数据对象加共享锁一直到该数据对象上的所有共享锁都被释放。
共享锁和排他锁最根本的区别在于,加上排他锁后,数据对象只对一个事务可见,而加上共享锁后,数据对所有事务都可见。下面我们就来看看如何借助 ZooKeeper来实现共享锁。
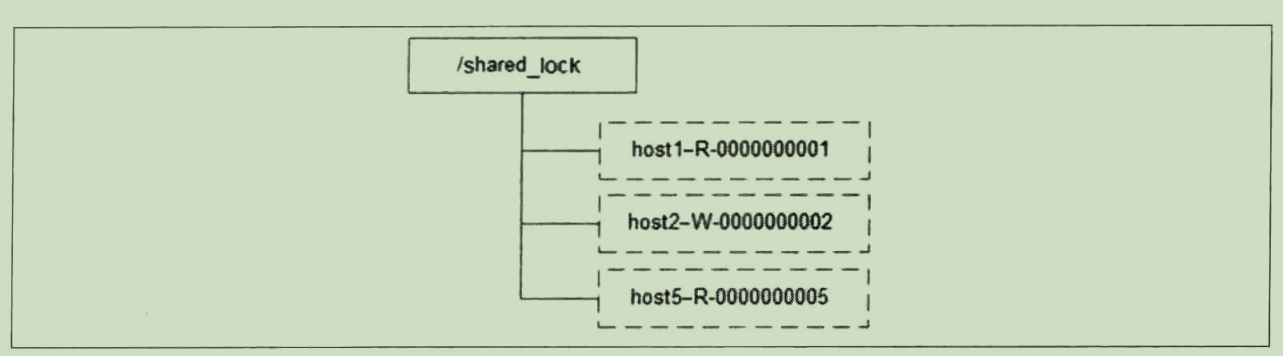
定义锁
和排他锁一样,同样是通过 ZooKeeper上的数据节点来表示一个锁,是一个类似于“/ shared_lock/Hostname}-请求类型-序号”的临时顺序节点,例如/shared_lock192.168.0.1-R-00000000那么,这个节点就代表了一个共享锁。
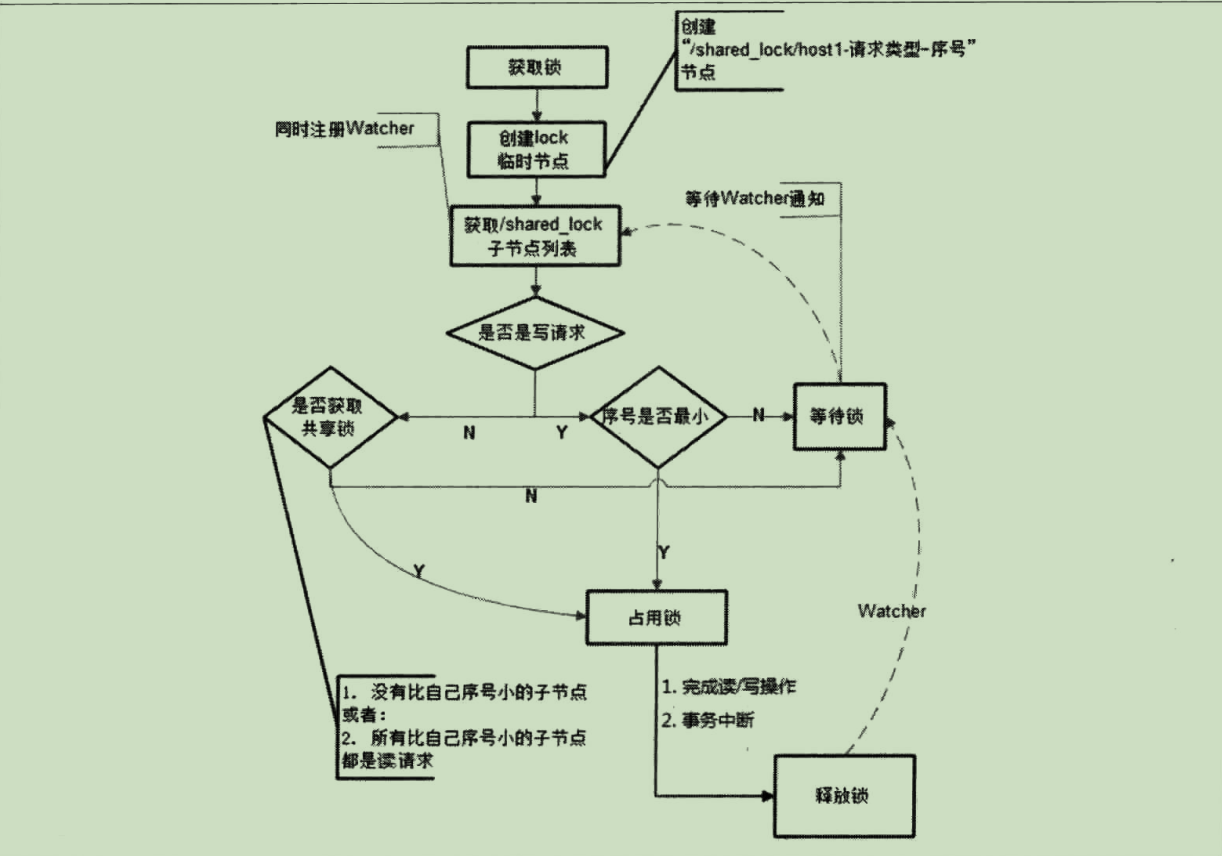
获取锁
在需要获取共享锁时,所有客户端都会到 shared_lock这个节点下面创建一个临时顺序节点,如果当前是读请求,那么就创建例如/shared_lock/92.l68.0.1-R-000000节点;如果是写请求,那么就创建例如/shared_lock./192.168.0.1-W-00000000节点。
判断读写顺序
根据共享锁的定义,不同的事务都可以同时对同一个数据对象进行读取操作,而更新操作必须在当前没有任何事务进行读写操作的情况下进行。基于这个原则,我们来看看如何通过 ZooKeeper的节点来确定分布式读写顺序,大致可以分为如下4个步骤。
创建完节点后,获取 /shared_lock节点下的所有子节点,并对该节点注册子节点变更的 Watcher监听
确定自己的节点序号在所有子节点中的顺序。
对于读请求:
如果没有比自己序号小的子节点,或是所有比自己序号小的子节点都是读请求,那么表明自己已经成功获取到了共享锁,同时开始执行读取逻辑。
如果比自己序号小的子节点中有写请求,那么就需要进入等待,对于写请求如果自己不是序号最小的子节点,那么就需要进入等待。
接收到 Watcher通知后,重复步骤1。
释放锁
释放锁的逻辑和排他锁是一样的。
2.3.2 优点及缺点
优点:
- 客户端如果出现宕机故障的话,锁可以马上释放,因为创建的是临时节点,宕机的话临时节点会删除,锁自然也就是释放了。
- 可以实现阻塞式锁,通过 watcher 监听,实现起来也比较简单
- 集群模式,稳定性比较高
缺点:
- 一旦网络有任何的抖动,Zookeeper 就会认为客户端已经宕机,就会断掉连接,其他客户端就可以获取到锁。
- 性能不高,因为每次在创建锁和释放锁的过程中,都要动态创建、销毁临时节点来实现锁功能。ZK 中创建和删除节点只能通过 Leader 服务器来执行,然后将数据同步到所有的 Follower 机器上。(zookeeper对外提供服务的只有leader)
2.4 consul实现分布式锁(eureka/Register:保存服务的IP 端口 服务列表)
2.4.1 实现原理及流程
基于Consul注册中心的Key/Value存储来实现分布式锁以及信号量的方法主要利用Key/Value存储API中的acquire和release操作来实现。acquire和release操作是类似Check-And-Set的操作:
//获取锁
acquire操作只有当锁不存在持有者时才会返回true,并且set设置的Value值,同时执行操作的session会持有对该Key的锁,否则就返回false
//acquire(key,value)方法成功返回true,失败返回false,key存在就失败,key不存在就成功
//释放锁
release操作则是使用指定的session来释放某个Key的锁,如果指定的session无效,那么会返回false,否则就会set设置Value值,并返回true
release(key)删除key对应的锁
//类比redis的实现实现流程
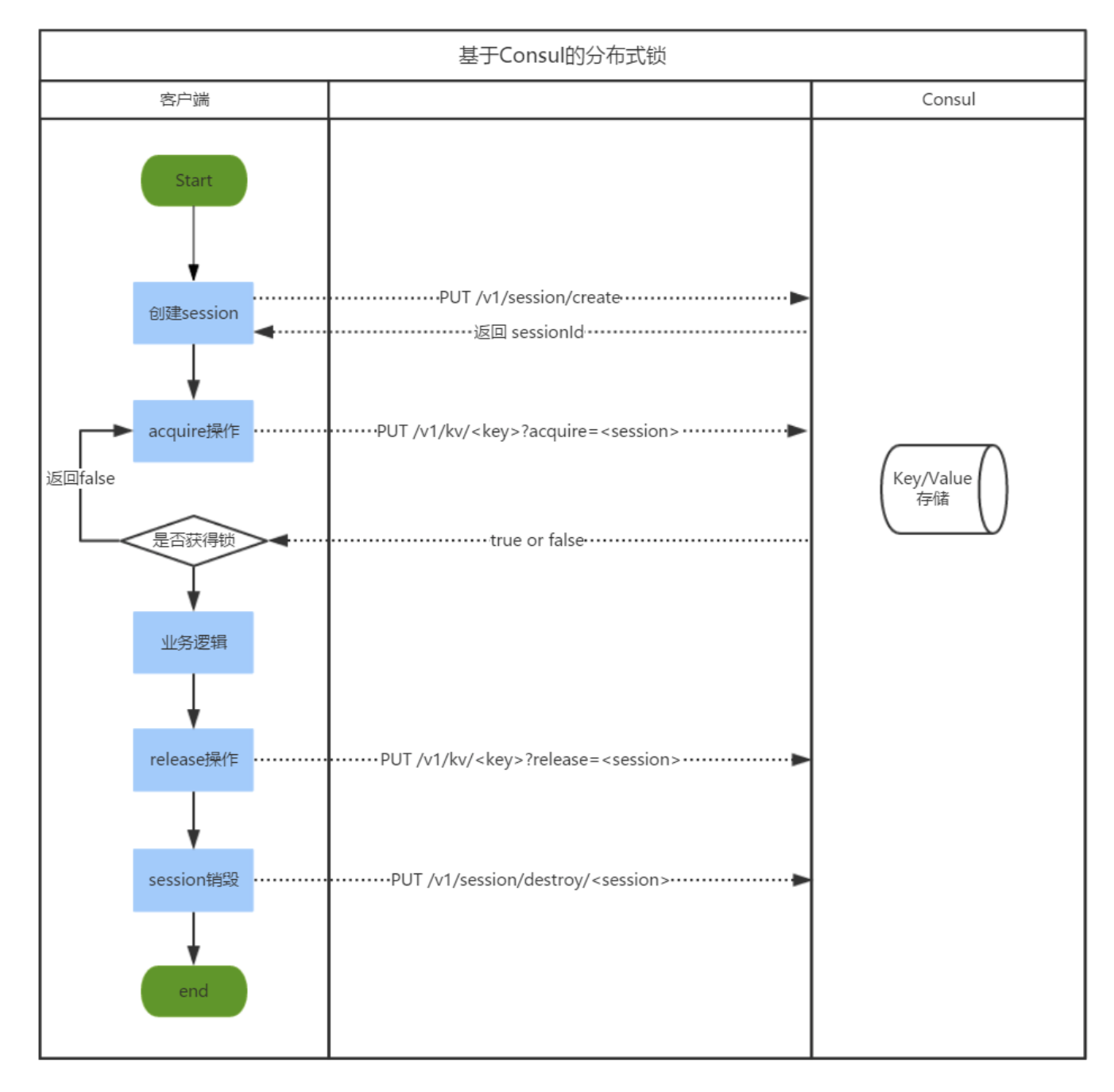
实现步骤:
- 客户端创建会话session,得到sessionId;
- 使用acquire设置value的值,若acquire结果为false,代表获取锁失败;
- acquire结果为true,代表获取锁成功,客户端执行业务逻辑;
- 客户端业务逻辑执行完成后,执行release操作释放锁;
- 销毁当前session,客户端连接断开。
代码:
下载consul
启动consul命令: consul agent -dev
pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.5.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>demo-consul</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>demo-consul</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
<spring-cloud.version>Hoxton.SR3</spring-cloud.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-consul-discovery</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>public class ConsulUtil {
private ConsulClient consulClient;
private String sessionId = null;
/**
* 构造函数
*/
public ConsulUtil(ConsulClient consulClient) {
this.consulClient = consulClient;
}
/**
* 创建session
*/
private String createSession(String name, Integer ttl){
NewSession newSession = new NewSession();
//设置锁有效时长
newSession.setTtl(ttl + "s");
//设置锁名字
newSession.setName(name);
String value = consulClient.sessionCreate(newSession, null).getValue();
return value;
}
/**
* 获取锁
*/
public Boolean lock(String name, Integer ttl){
//定义获取标识
Boolean flag = false;
//创建session
sessionId = createSession(name, ttl);
//死循环获取锁
while (true){
//执行acquire操作
PutParams putParams = new PutParams();
putParams.setAcquireSession(sessionId);
flag = consulClient.setKVValue(name, "local" + System.currentTimeMillis(), putParams).getValue();
if(flag){
break;
}
}
return flag;
}
/**
* 释放锁
*/
public Boolean release(String name){
//执行acquire操作
PutParams putParams = new PutParams();
putParams.setReleaseSession(sessionId);
Boolean value = consulClient.setKVValue(name, "local" + System.currentTimeMillis(), putParams).getValue();
return value;
}测试代码:
@SpringBootTest
class DemoApplicationTests {
@Test
public void testLock() throws Exception {
new Thread(new LockRunner("线程1")).start();
new Thread(new LockRunner("线程2")).start();
new Thread(new LockRunner("线程3")).start();
new Thread(new LockRunner("线程4")).start();
new Thread(new LockRunner("线程5")).start();
Thread.sleep(200000L);
}
class LockRunner implements Runnable {
private String name;
public LockRunner(String name) {
this.name = name;
}
@Override
public void run() {
ConsulUtil lock = new ConsulUtil(new ConsulClient());
try {
if (lock.lock("test", 10)) {
System.out.println(name + "获取到了锁");
//持有锁5秒
Thread.sleep(5000);
//释放锁
lock.release("test");
System.out.println(name + "释放了锁");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}结果

2.4.2 优点及缺点
**优点:**基于consul注册中心即可实现分布式锁,实现简单、方便、快捷
缺点:
- lock delay:consul实现分布式锁存在延迟,一个节点释放锁了,另一个节点不能立马拿到锁。需要等待lock delay时间后才可以拿到锁。
- 高负载的场景下,不能及时的续约,导致session timeout, 其他节点拿到锁。