
线上进程内存动态查看
线上进程内存动态查看
工具说明
- jinfo:可以输出并修改运行时的java 进程的opts。
- jps:与unix上的ps类似,用来显示本地的java进程,可以查看本地运行着几个java程序,并显示他们的进程号。
- jstat:一个极强的监视VM内存工具。可以用来监视VM内存内的各种堆和非堆的大小及其内存使用量。
- jmap:打印出某个java进程(使用pid)内存内的所有'对象'的情况(如:产生那些对象,及其数量)。
JPS
Java版的ps命令,查看java进程及其相关的信息,如果你想找到一个java进程的pid,那可以用jps命令替代linux中的ps命令了,简单而方便。
命令格式:jps [options] [hostid]
options参数解释:
- -l : 输出主类全名或jar路径
- -q : 只输出LVMID
- -m : 输出JVM启动时传递给main()的参数
- -v : 输出JVM启动时显示指定的JVM参数
案例
jps -l 输出jar包路径,类全名
jps -m 输出main参数
jps -v 输出JVM参数JSTAT命令
说明
jstat命令是使用频率比较高的命令,主要用来查看JVM运行时的状态信息,包括内存状态、垃圾回收等。
命令格式:jstat [option] LVMID [interval] [count]
其中LVMID是进程id,interval是打印间隔时间(毫秒),count是打印次数(默认一直打印)
option:参数选项
-t:可以在打印的列加上Timestamp列,用于显示系统运行的时间
-h:可以在周期性数据输出的时候,指定输出多少行以后输出一次表头
vmid:Virtual Machine ID( 进程的 pid)
interval:执行每次的间隔时间,单位为毫秒
count:用于指定输出多少次记录,缺省则会一直打印
option参数解释:
-class:class loader的行为统计
-compiler:HotSpt JIT编译器行为统计
-gc:垃圾回收堆的行为统计
-gccapacity:各个垃圾回收代容量(young,old,perm)和他们相应的空间统计
-gcutil:垃圾回收统计概述
-gccause 垃圾收集统计概述(同-gcutil),附加最近两次垃圾回收事件的原因
-gcnew:新生代行为统计
-gcnewcapacity:新生代与其相应的内存空间的统计
-gcold:年老代和永生代行为统计
-gcoldcapacity:年老代行为统计
-gcpermcapacity:永生代行为统计
-printcompilation:HotSpot编译方法统计案例
查看系统加载类个数
此命令可以帮助我们查看加载的类个数信息以及占用的内存情况;
//首先进入到jdk安装目录的bin目录下
jstat -class 进程号
jstat -class 5052
Loaded Bytes Unloaded Bytes Time
7846 14968.0 0 0.0 3.11- Loaded:加载类的数量
- Bytes:加载类的size,单位为Byte
- Unloaded:卸载类的数目
- Bytes:卸载类的size,单位为Byte
- Time:加载与卸载类花费的时间
查看jvm编译类个数
查看jvm编译的类个数信息:
jstat -complier 进程号
jstat -compiler 5052
Compiled Failed Invalid Time FailedType FailedMethod
5415 1 0 9.98 1 java/net/URLClassLoader$1 run- Compiled:编译任务执行数量
- Failed:编译任务执行失败数量
- Invalid:编译任务执行失效数量
- Time:编译任务消耗时间
- FailedType:最后一个编译失败任务的类型
- FailedMethod:最后一个编译失败任务所在的类及方法
查看gc信息以及次数
查看gc的信息以及次数:
jstat -gc 进程号
jstat -gc 5052
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
7680.0 7680.0 0.0 0.0 206848.0 110596.4 67584.0 10392.8 35496.0 33196.7 4608.0 4210.7 6 0.072 2 0.068 0.139- S0C:年轻代中第一个survivor(幸存区)的容量 (字节)
- S1C:年轻代中第二个survivor(幸存区)的容量 (字节)
- S0U:年轻代中第一个survivor(幸存区)目前已使用空间 (字节)
- S1U:年轻代中第二个survivor(幸存区)目前已使用空间 (字节)
- EC:年轻代中Eden(伊甸园)的容量 (字节)
- EU:年轻代中Eden(伊甸园)目前已使用空间 (字节)
- OC:Old代的容量 (字节)
- OU:Old代目前已使用空间 (字节)
- MC:metaspace(元空间)的容量 (字节)
- MU:metaspace(元空间)目前已使用空间 (字节)
- CCSC:当前压缩类空间的容量 (字节)
- CCSU:当前压缩类空间目前已使用空间 (字节)
- YGC:从应用程序启动到采样时年轻代中gc次数
- YGCT:从应用程序启动到采样时年轻代中gc所用时间(s)
- FGC:从应用程序启动到采样时old代(全gc)gc次数
- FGCT:从应用程序启动到采样时old代(全gc)gc所用时间(s)
- GCT:从应用程序启动到采样时gc用的总时间(s)
GCT = YGCT + FGCT
查看不同堆区域内存使用大小
查看young,old和perm区的对象和使用大小:
jstat -gccapacity 进程号
jstat -gccapacity 5052
NGCMN NGCMX NGC S0C S1C EC OGCMN OGCMX OGC OC MCMN MCMX MC CCSMN CCSMX CCSC YGC FGC
40960.0 649216.0 224256.0 7680.0 7680.0 206848.0 81920.0 1298432.0 67584.0 67584.0 0.0 1081344.0 35496.0 0.0 1048576.0 4608.0 6 2
jstat -gccapacity -h5 5052 1000 #-h5:每5行显示一次表头 1000:每1秒钟显示一次,单位为毫秒- NGCMN:年轻代(young)中初始化(最小)的大小(字节)
- NGCMX:年轻代(young)的最大容量 (字节)
- NGC:年轻代(young)中当前的容量 (字节)
- S0C:年轻代中第一个survivor(幸存区)的容量 (字节)
- S1C:年轻代中第二个survivor(幸存区)的容量 (字节)
- EC:年轻代中Eden(伊甸园)的容量 (字节)
- OGCMN:old代中初始化(最小)的大小 (字节)
- OGCMX:old代的最大容量(字节)
- OGC:old代当前新生成的容量 (字节)
- OC:Old代的容量 (字节)
- MCMN:metaspace(元空间)中初始化(最小)的大小 (字节)
- MCMX:metaspace(元空间)的最大容量 (字节)
- MC:metaspace(元空间)当前新生成的容量 (字节)
- CCSMN:最小压缩类空间大小
- CCSMX:最大压缩类空间大小
- CCSC:当前压缩类空间大小
- YGC:从应用程序启动到采样时年轻代中gc次数
- FGC:从应用程序启动到采样时old代(全gc)gc次数
元数据空间统计
jstat -gcmetacapacity 5052
MCMN MCMX MC CCSMN CCSMX CCSC YGC FGC FGCT GCT
0.0 1081344.0 35496.0 0.0 1048576.0 4608.0 6 2 0.068 0.139- MCMN:最小元数据容量
- MCMX:最大元数据容量
- MC:当前元数据空间大小
- CCSMN:最小压缩类空间大小
- CCSMX:最大压缩类空间大小
- CCSC:当前压缩类空间大小
- YGC:从应用程序启动到采样时年轻代中gc次数
- FGC:从应用程序启动到采样时old代(全gc)gc次数
- FGCT:从应用程序启动到采样时old代(全gc)gc所用时间(s)
- GCT:从应用程序启动到采样时gc用的总时间(s)
新生代垃圾回收统计
jstat -gcnew 5052
S0C S1C S0U S1U TT MTT DSS EC EU YGC YGCT
7680.0 7680.0 0.0 0.0 5 15 7680.0 206848.0 149606.4 6 0.072- S0C:年轻代中第一个survivor(幸存区)的容量 (字节)
- S1C:年轻代中第二个survivor(幸存区)的容量 (字节)
- S0U:年轻代中第一个survivor(幸存区)目前已使用空间 (字节)
- S1U:年轻代中第二个survivor(幸存区)目前已使用空间 (字节)
- TT:持有次数限制
- MTT:最大持有次数限制
- DSS:期望的幸存区大小
- EC:年轻代中Eden(伊甸园)的容量 (字节)
- EU:年轻代中Eden(伊甸园)目前已使用空间 (字节)
- YGC:从应用程序启动到采样时年轻代中gc次数
- YGCT:从应用程序启动到采样时年轻代中gc所用时间(s)
新生代内存统计
jstat -gcnewcapacity 5052
NGCMN NGCMX NGC S0CMX S0C S1CMX S1C ECMX EC YGC FGC
40960.0 649216.0 224256.0 216064.0 7680.0 216064.0 7680.0 648192.0 206848.0 6 2- NGCMN:年轻代(young)中初始化(最小)的大小(字节)
- NGCMX:年轻代(young)的最大容量 (字节)
- NGC:年轻代(young)中当前的容量 (字节)
- S0CMX:年轻代中第一个survivor(幸存区)的最大容量 (字节)
- S0C:年轻代中第一个survivor(幸存区)的容量 (字节)
- S1CMX:年轻代中第二个survivor(幸存区)的最大容量 (字节)
- S1C:年轻代中第二个survivor(幸存区)的容量 (字节)
- ECMX:年轻代中Eden(伊甸园)的最大容量 (字节)
- EC:年轻代中Eden(伊甸园)的容量 (字节)
- YGC:从应用程序启动到采样时年轻代中gc次数
- GC:从应用程序启动到采样时old代(全gc)gc次数
老年代垃圾回收统计
jstat -gcold 5052
MC MU CCSC CCSU OC OU YGC FGC FGCT GCT
35496.0 33196.7 4608.0 4210.7 67584.0 10392.8 6 2 0.068 0.139- MC:metaspace(元空间)的容量 (字节)
- MU:metaspace(元空间)目前已使用空间 (字节)
- CCSC:压缩类空间大小
- CCSU:压缩类空间使用大小
- OC:Old代的容量 (字节)
- OU:Old代目前已使用空间 (字节)
- YGC:从应用程序启动到采样时年轻代中gc次数
- FGC:从应用程序启动到采样时old代(全gc)gc次数
- FGCT:从应用程序启动到采样时old代(全gc)gc所用时间(s)
- GCT:从应用程序启动到采样时gc用的总时间(s)
老年代内存统计
jstat -gcoldcapacity 5052
OGCMN OGCMX OGC OC YGC FGC FGCT GCT
81920.0 1298432.0 67584.0 67584.0 6 2 0.068 0.139- OGCMN:old代中初始化(最小)的大小 (字节)
- OGCMX:old代的最大容量(字节)
- OGC:old代当前新生成的容量 (字节)
- OC:Old代的容量 (字节)
- YGC:从应用程序启动到采样时年轻代中gc次数
- FGC:从应用程序启动到采样时old代(全gc)gc次数
- FGCT:从应用程序启动到采样时old代(全gc)gc所用时间(s)
- GCT:从应用程序启动到采样时gc用的总时间(s)
垃圾回收统计
jstat -gcutil 12888 1000 3
12888为pid,每隔1000毫秒打印一次,打印3次输出
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
6.17 0.00 6.39 33.72 93.42 90.57 976 57.014 68 53.153 110.168
6.17 0.00 6.39 33.72 93.42 90.57 976 57.014 68 53.153 110.168
6.17 0.00 6.39 33.72 93.42 90.57 976 57.014 68 53.153 110.168字段解释:
- S0:年轻代中第一个survivor(幸存区)已使用的占当前容量百分比
- S1:年轻代中第二个survivor(幸存区)已使用的占当前容量百分比
- E:年轻代中Eden(伊甸园)已使用的占当前容量百分比
- O:old代已使用的占当前容量百分比
- M:元数据区已使用的占当前容量百分比
- CCS:压缩类空间已使用的占当前容量百分比
- YGC :从应用程序启动到采样时年轻代中gc次数
- YGCT :从应用程序启动到采样时年轻代中gc所用时间(s)
- FGC :从应用程序启动到采样时old代(全gc)gc次数
- FGCT :从应用程序启动到采样时old代(全gc)gc所用时间(s)
- GCT:从应用程序启动到采样时gc用的总时间(s)
垃圾回收堆行为统计
jstat -gc 12888 1000 3-gc和-gcutil参数类似,只不过输出字段不是百分比,而是实际的值。
输出
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
25600.0 25600.0 0.0 1450.0 204800.0 97460.7 512000.0 172668.8 345736.0 322997.7 48812.0 44209.0 977 57.040 68 53.153 110.193
25600.0 25600.0 0.0 1450.0 204800.0 97460.7 512000.0 172668.8 345736.0 322997.7 48812.0 44209.0 977 57.040 68 53.153 110.193
25600.0 25600.0 0.0 1450.0 204800.0 97460.7 512000.0 172668.8 345736.0 322997.7 48812.0 44209.0 977 57.040 68 53.153 110.193字段解释:
- S0C survivor0大小
- S1C survivor1大小
- S0U survivor0已使用大小
- S1U survivor1已使用大小
- EC Eden区大小
- EU Eden区已使用大小
- OC 老年代大小
- OU 老年代已使用大小
- MC 方法区大小
- MU 方法区已使用大小
- CCSC 压缩类空间大小
- CCSU 压缩类空间已使用大小
- YGC 年轻代垃圾回收次数
- YGCT 年轻代垃圾回收消耗时间
- FGC 老年代垃圾回收次数
- FGCT 老年代垃圾回收消耗时间
- GCT 垃圾回收消耗总时间
-gccause
jstat -gccause 5052
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT LGCC GCC
0.00 0.00 87.76 15.38 93.52 91.38 6 0.072 2 0.068 0.139 Metadata GC Threshold No GC- LGCC:最后一次GC原因
- GCC:当前GC原因(No GC 为当前没有执行GC)
jinfo
说明
在很多情况下,Java应用程序不会指定所有的Java虚拟机参数。而此时,开发人员可能不知道某一个具体的Java虚拟机参数的默认值。在这种情况下,可能需要通过查找文档获取某个参数的默认值。这个查找过程可能是非常艰难的。但有了 jinfo工具,开发人员可以很方便地找到Java虚拟机参数的当前值。
jinfo不仅可以查看运行时某一个Java虚拟机参数的实际取值, 甚至可以在运行时修改部分参 数,并使之立即生效。 但是,并非所有参数都支持动态修改。参数只有被标记 manageable的flag可以被实时修改。其实,这个修改能力是 极其有限的。
基本命令
基本语法
jinfo [options] pidjinfo -sysprops pid:输出系统属性
no option:输出全部的参数和系统属性
-flag name:输出对应名称的参数
-flag [+|-]name:开启或者关闭对应名称的参数 只有被标记为 manageable 的参数才可以被动态修改
-flag name=value:设定对应名称的参数
-flags:输出全部的参数使用案例
查看是否打印GC详细日志
jinfo -flag PrintGCDetails 6936
输出:
-XX:-PrintGCDetails
PrintGCDetails前面有个-号,就表示没开启GC日志;jinfo -flags pid:查看曾经赋过值的参数值
开启GC日志打印参数
jinfo -flag +PrintGCDetails 6936
查看修改后的参数
jinfo -flag PrintGCDetails 6936
-XX:+PrintGCDetails
+PrintGCDetails:+表示已开启参数使用jinfo -flags 6936命令查看

jinfo -flag <具体参数> pid: 查看具体参数的值
jinfo -flag MaxHeapSize 6936
-XX:MaxHeapSize=1994391552使用jinfo修改运行时参数值
jinfo不仅可以查看运行时某一个Java虚拟机参数的实际取值, 甚至可以在运行时修改部分参 数,并使之立即生效。 但是,并非所有参数都支持动态修改。参数只有被标记 manageable的flag可以被实时修改。其实,这个修改能力是 极其有限的;
首先查看那些值可以被修改:java -XX:+PrintFlagsFinal -version | grep "manageable"
java -XX:+PrintFlagsFinal -version | grep "manageable"
intx CMSAbortablePrecleanWaitMillis = 100 {manageable}
intx CMSTriggerInterval = -1 {manageable}
intx CMSWaitDuration = 2000 {manageable}
bool HeapDumpAfterFullGC = false {manageable}
bool HeapDumpBeforeFullGC = false {manageable}
bool HeapDumpOnOutOfMemoryError = false {manageable}
ccstr HeapDumpPath = {manageable}
uintx MaxHeapFreeRatio = 100 {manageable}
uintx MinHeapFreeRatio = 0 {manageable}
bool PrintClassHistogram = false {manageable}
bool PrintClassHistogramAfterFullGC = false {manageable}
bool PrintClassHistogramBeforeFullGC = false {manageable}
bool PrintConcurrentLocks = false {manageable}
bool PrintGC = false {manageable}
bool PrintGCDateStamps = false {manageable}
bool PrintGCDetails = false {manageable}
bool PrintGCID = false {manageable}
bool PrintGCTimeStamps = false {manageable}
java version "1.8.0_161"
Java(TM) SE Runtime Environment (build 1.8.0_161-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.161-b12, mixed mode)修改参数值语法:
布尔类型: jinfo -flag +-参数 pid
非布尔类型: jinfo -flag 参数名=参数值 pid
修改布尔类型参数:
jinfo -flag +PrintGC 6936查看修改后的值:

或者使用命令:jinfo -flag PrintGC 6936
查看jvm参数值
- java -XX: -PrintFlagslnitial 查看所有JVM参数启动的初始值
- java -XX:+PrintFlagsFinal 查看所有JVM参数的最终值(这个用的更多一些)
- java -XX: +PrintCommandLineFlags 查看那些已经被用户或者JVM设置过的详细的XX参数的名称和值
上面前两个用的比较多一些,特别是第二个
查看jvm所有最终参数值
输出所有jvm最终参数到文件中:java -XX:+PrintFlagsFinal > PrintFlagsFinal1.log
输出jvm初始参数
输出jvm初始参数到jvm:
java -XX:+PrintFlagsInitial > PrintFlagsInitial.log
输出用户修改过的参数
java -XX:+PrintCommandLineFlags >> PrintCommandLineFlags.log
查看JVM参数和系统配置
jinfo 11888
jinfo -flags 11888
jinfo -sysprops 11888查看打印GC日志参数
jinfo -flag PrintGC 11888
jinfo -flag PrintGCDetails 11888打开GC日志参数
jinfo -flag +PrintGC 11888
jinfo -flag +PrintGCDetails 11888关闭GC日志参数
jinfo -flag -PrintGC 11888
jinfo -flag -PrintGCDetails 11888还可以使用下面的命令查看那些参数可以使用jinfo命令来管理:
java -XX:+PrintFlagsFinal -version | grep manageable常用JVM参数
- -Xms:初始堆大小,默认为物理内存的1/64(<1GB);默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制
- -Xmx:最大堆大小,默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制
- -Xmn:新生代的内存空间大小,注意:此处的大小是(eden+ 2 survivor space)。与jmap -heap中显示的New gen是不同的。整个堆大小=新生代大小 + 老生代大小 + 永久代大小。
- 在保证堆大小不变的情况下,增大新生代后,将会减小老生代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
- -XX:SurvivorRatio:新生代中Eden区域与Survivor区域的容量比值,默认值为8。两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10。
- -Xss:每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。应根据应用的线程所需内存大小进行适当调整。
- 在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。一般小的应用, 如果栈不是很深, 应该是128k够用的,
- 大的应用建议使用256k。这个选项对性能影响比较大,需要严格的测试。和threadstacksize选项解释很类似,官方文档似乎没有解释,
- 在论坛中有这样一句话:"-Xss
is` `translatedina VM flag named ThreadStackSize”一般设置这个值就可以了。
- -XX:PermSize:设置永久代(perm gen)初始值。默认值为物理内存的1/64。
- -XX:MaxPermSize:设置持久代最大值。物理内存的1/4。
jmap
说明
jmap是用来生成堆dump文件和查看堆相关的各类信息的命令,例如查看finalize执行队列,heap的详细信息和使用情况。
堆Dump是反应Java堆使用情况的内存镜像,其中主要包括系统信息、虚拟机属性、完整的线程Dump、所有类和对象的状态等。 一般,在内存不足、GC异常等情况下,我们就会怀疑有内存泄露。这个时候我们就可以制作堆Dump来查看具体情况。分析原因。
常见错误:
- outOfMemoryError 年老代内存不足。
- outOfMemoryError:PermGen Space 永久代内存不足。
- outOfMemoryError:GC overhead limit exceed 垃圾回收时间占用系统运行时间的98%或以上。
命令格式
jmap [option] <pid> (连接正在执行的进程)
jmap [option] <executable <core> (连接一个core文件)
jmap [option] [server_id@]<remote server IP or hostname> (链接远程服务器)option参数解释:
- `<no option>`如果使用不带选项参数的jmap打印共享对象映射,将会打印目标虚拟机中加载的每个共享对象的起始地址、映射大小以及共享对象文件的路径全称。这与Solaris的pmap工具比较相似。
- -heap :打印java heap摘要
- -histo:打印jvm heap的直方图。其输出信息包括类名,对象数量,对象占用大小。
- -histo`[:live]`打印每个class的实例数目,内存占用,类全名信息. VM的内部类名字开头会加上前缀”*”. 如果live子参数加上后,只统计活的对象数量.
- -dump:`[live,]`format=b,file=<filename>使用hprof二进制形式,输出jvm的heap内容到文件, live子选项是可选的,假如指定live选项,那么只输出活的对象到文件.
- -permstat:打印permanent generation heap情况, 包含每个classloader的名字,活泼性,地址,父classloader和加载的class数量. 另外,内部String的数量和占用内存数也会打印出来.
- -F强迫.在pid没有响应的时候使用-dump或者-histo参数. 在这个模式下,live子参数无效.
- -clstats :打印类加载器统计信息
- -finalizerinfo:打印在f-queue中等待执行finalizer方法的对象,即正等候回收的对象的信息.
- `-dump:<dump-options> 生成java堆的dump文件`
- dump-options:
- live 只转储存活的对象,如果没有指定则转储所有对象
- format=b 二进制格式
- `file=<file> 转储文件到 <file>`从安全点日志看,从Heap Dump开始,整个JVM都是停顿的,考虑到IO(虽是写到Page Cache,但或许会遇到background flush),几G的Heap可能产生几秒的停顿,在生产环境上执行时谨慎再谨慎。
live的选项,实际上是产生一次Full GC来保证只看还存活的对象。有时候也会故意不加live选项,看历史对象。
Dump出来的文件建议用JDK自带的VisualVM或Eclipse的MAT插件打开,对象的大小有两种统计方式:
- 本身大小(Shallow Size):对象本来的大小。
- 保留大小(Retained Size): 当前对象大小 + 当前对象直接或间接引用到的对象的大小总和。
看本身大小时,占大头的都是char[] ,byte[]之类的,没什么意思(用jmap -histo:live pid 看的也是本身大小)。所以需要关心的是保留大小比较大的对象,看谁在引用这些char[], byte[]。
(MAT能看的信息更多,但VisualVM胜在JVM自带,用法如下:命令行输入jvisualvm,文件->装入->堆Dump->检查 -> 查找20保留大小最大的对象,就会触发保留大小的计算,然后就可以类视图里浏览,按保留大小排序了)
参数信息
- executable Java executable from which the core dump was produced.(可能是产生core dump的java可执行程序)
- core 将被打印信息的core dump文件
- remote-hostname-or-IP 远程debug服务的主机名或ip
- server-id 唯一id,假如一台主机上多个远程debug服务,用此选项参数标识服务器
案例
jmap -heap pid 展示pid的整体堆信息
jmap -heap 6936
Attaching to process ID 6936, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.161-b12
using thread-local object allocation.
Parallel GC with 13 thread(s)
Heap Configuration: # 堆内存初始化配置
MinHeapFreeRatio = 0 #-XX:MinHeapFreeRatio设置JVM堆最小空闲比率
MaxHeapFreeRatio = 100 #-XX:MaxHeapFreeRatio设置JVM堆最大空闲比率
MaxHeapSize = 1994391552 (1902.0MB) #-XX:MaxHeapSize=设置JVM堆的最大大小
NewSize = 41943040 (40.0MB) #-XX:NewSize=设置JVM堆的‘新生代’的默认大小
MaxNewSize = 664797184 (634.0MB) #-XX:MaxNewSize=设置JVM堆的‘新生代’的最大大小
OldSize = 83886080 (80.0MB) #-XX:OldSize=设置JVM堆的‘老生代’的大小
NewRatio = 2 #-XX:NewRatio=:‘新生代’和‘老生代’的大小比率
SurvivorRatio = 8 #-XX:SurvivorRatio=设置年轻代中Eden区与Survivor区的大小比值
MetaspaceSize = 21807104 (20.796875MB) `#-XX:PermSize=<value>`:设置JVM堆的‘持久代’的初始大小
CompressedClassSpaceSize = 1073741824 (1024.0MB) `#-XX:MaxPermSize=<value>`:设置JVM堆的‘持久代’的最大大小
MaxMetaspaceSize = 17592186044415 MB # 元空间最大的大小
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
PS Young Generation #新生代区内存分布,包含伊甸园区+1个Survivor区
Eden Space: # eden区域
capacity = 208666624 (199.0MB) # eden区域容量
used = 190727624 (181.89203643798828MB) # eden区域使用量
free = 17939000 (17.10796356201172MB) # eden区域空闲大小
91.40303338592376% used # eden区域使用比率
From Space: #其中一个Survivor区的内存分布
capacity = 7864320 (7.5MB)
used = 0 (0.0MB)
free = 7864320 (7.5MB)
0.0% used
To Space: #另一个Survivor区的内存分布
capacity = 8388608 (8.0MB)
used = 0 (0.0MB)
free = 8388608 (8.0MB)
0.0% used
PS Old Generation # 老年代内存分布
capacity = 70254592 (67.0MB)
used = 10615008 (10.123260498046875MB)
free = 59639584 (56.876739501953125MB)
15.109344026935634% used
17170 interned Strings occupying 1725592 bytes.如果from区使用率一直是100% 说明程序创建大量的短生命周期的实例,使用jstat统计一下jvm在内存回收中发生的频率耗时以及是否有full gc,使用这个数据来评估一内存配置参数、gc参数是否合理;
jmap -histo pid 展示class的内存情况
说明:instances(实例数)、bytes(大小)、classs name(类名)。它基本是按照使用使用大小逆序排列的。
jmap -histo 6936
num #instances #bytes class name
----------------------------------------------
1: 112625 10723936 [C
2: 18918 3440224 [I
3: 36930 1866560 [Ljava.lang.Object;
4: 71009 1704216 java.lang.String
5: 26666 1573816 [B
6: 8476 942728 java.lang.Class
7: 37708 904992 java.util.ArrayList
8: 25216 806912 java.util.concurrent.ConcurrentHashMap$Node
9: 10655 784616 [Ljava.util.HashMap$Node;
10: 15112 725376 java.nio.HeapByteBuffer
11: 19957 638624 java.util.HashMap$Node
12: 6588 579744 java.lang.reflect.Method
13: 11807 566736 java.util.HashMap
14: 14679 469728 java.util.ArrayList$Itr
15: 6715 429760 java.util.stream.ReferencePipeline$2
16: 10733 429320 java.util.LinkedHashMap$Entry
17: 10567 422680 java.util.HashMap$EntryIterator
18: 7343 411208 java.util.stream.ReferencePipeline$Head
19: 6101 390464 java.util.regex.Matcher
20: 12202 292848 java.util.Formatter$FixedString
21: 7100 284000 java.util.HashMap$KeyIterator
22: 4870 272720 java.util.LinkedHashMap
23: 4842 271152 sun.nio.cs.UTF_8$Encoder
24: 16865 269840 java.lang.Object
25: 4719 264264 java.util.concurrent.ConcurrentHashMap$ValueIterator
26: 5287 253776 org.apache.kafka.common.utils.Timer
27: 6305 252200 java.util.HashMap$KeySpliterator
28: 6123 245624 [J
29: 10212 245088 java.lang.StringBuilder
30: 6101 244040 [Ljava.util.Formatter$Flags;
31: 6101 244040 java.util.Formatter$FormatSpecifier说明
#instance 是对象的实例个数
#bytes 是总占用的字节数
class name 对应的就是 Class 文件里的 class 的标识
B 代表 byte
C 代表 char
D 代表 double
F 代表 float
I 代表 int
J 代表 long
Z 代表 boolean
前边有 [ 代表数组, [I 就相当于 int[]
对象用 [L+ 类名表示从打印结果看,存在大量的[C,[I对象,只知道它占用了那么大的内存,但不知道由什么对象创建的。下一步需要将其他dump出来,使用内存分析工具进一步明确它是由谁引用的、由什么对象。
jmap -histo:live pid>a.log
可以观察heap中所有对象的情况(heap中所有生存的对象的情况)。包括对象数量和所占空间大小。 可以将其保存到文本中去,在一段时间后,使用文本对比工具,可以对比出GC回收了哪些对象。
jmap -histo:live 这个命令执行,JVM会先触发gc,然后再统计信息。
dump 将内存使用的详细情况输出到文件
jmap -dump:live,format=b,file=a.log pid
说明:内存信息dump到a.log文件中。
这个命令执行,JVM会将整个heap的信息dump写入到一个文件,heap如果比较大的话,就会导致这个过程比较耗时,并且执行的过程中为了保证dump的信息是可靠的,所以会暂停应用。
该命令通常用来分析内存泄漏OOM,通常做法是:
- 首先配置JVM启动参数,让JVM在遇到OutOfMemoryError时自动生成Dump文件
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path- 然后使用命令
jmap -dump:format=b,file=/path/heap.bin 进程ID如果只dump heap中的存活对象,则加上选项-live。
- 然后使用MAT分析工具,如jhat命令,eclipse的mat插件。
转存存活对象
jmap -dump:live,format=b,file=dump.hprof 12888这个命令是要把java堆中的存活对象信息转储到dump.hprof文件
统计存活对象统计信息
jmap -histo:live 12888 | more输出存活对象统计信息:
num #instances #bytes class name
----------------------------------------------
1: 46608 1111232 java.lang.String
2: 6919 734516 java.lang.Class
3: 4787 536164 java.net.SocksSocketImpl
4: 15935 497100 java.util.concurrent.ConcurrentHashMap$Node
5: 28561 436016 java.lang.Object查看进程详细堆信息
jmap命令可以用来查看堆中的活动对象及大小
jmap -heap 6936
Attaching to process ID 12888, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.25-b02
using thread-local object allocation.
Parallel GC with 4 thread(s)
Heap Configuration: //堆内存初始化配置
MinHeapFreeRatio = 0 //对应jvm启动参数-XX:MinHeapFreeRatio设置JVM堆最小空闲比率(default 40)
MaxHeapFreeRatio = 100 //对应jvm启动参数 -XX:MaxHeapFreeRatio设置JVM堆最大空闲比率(default 70)
MaxHeapSize = 1073741824 (1024.0MB) //对应jvm启动参数-XX:MaxHeapSize=设置JVM堆的最大大小
NewSize = 22020096 (21.0MB) //对应jvm启动参数-XX:NewSize=设置JVM堆的新生代的默认大小
MaxNewSize = 357564416 (341.0MB) //对应jvm启动参数-XX:MaxNewSize=设置JVM堆的新生代的最大大小
OldSize = 45088768 (43.0MB) //对应jvm启动参数-XX:OldSize=<value>:设置JVM堆的老年代的大小
NewRatio = 2 //对应jvm启动参数-XX:NewRatio=:新生代和老生代的大小比率
SurvivorRatio = 8 //对应jvm启动参数-XX:SurvivorRatio=设置新生代中Eden区与Survivor区的大小比值
MetaspaceSize = 21807104 (20.796875MB) // 元数据区大小
CompressedClassSpaceSize = 1073741824 (1024.0MB) //类压缩空间大小
MaxMetaspaceSize = 17592186044415 MB //元数据区最大大小
G1HeapRegionSize = 0 (0.0MB) //G1垃圾收集器每个Region大小
Heap Usage: //堆内存使用情况
PS Young Generation
Eden Space: //Eden区内存分布
capacity = 17825792 (17.0MB) //Eden区总容量
used = 12704088 (12.115562438964844MB) //Eden区已使用
free = 5121704 (4.884437561035156MB) //Eden区剩余容量
71.26801434685203% used //Eden区使用比率
From Space: //其中一个Survivor区的内存分布
capacity = 2097152 (2.0MB)
used = 1703936 (1.625MB)
free = 393216 (0.375MB)
81.25% used
To Space: //另一个Survivor区的内存分布
capacity = 2097152 (2.0MB)
used = 0 (0.0MB)
free = 2097152 (2.0MB)
0.0% used
PS Old Generation
capacity = 52428800 (50.0MB) //老年代容量
used = 28325712 (27.013504028320312MB) //老年代已使用
free = 24103088 (22.986495971679688MB) //老年代空闲
54.027008056640625% used //老年代使用比率
15884 interned Strings occupying 2075304 bytes.性能分析
发现问题
- 使用uptime或者top命令查看CPU的Load情况,Load越高说明问题越严重;
- 使用jstat查看FGC发生的频率及FGC所花费的时间,FGC发生的频率越快、花费的时间越高,问题越严重;
导出数据:在应用快要发生FGC的时候把堆导出来
查看快要发生FGC使用命令:
jmap -heap <pid>

以上截图包括了新生代、老年代及持久代的当前使用情况,如果不停的重复上面的命令,会看到这些数字的变化,变化越大说明系统存在问题的可能性越大,特别是被红色圈起来的老年代的变化情况。现在看到的这个值为使用率为99%或才快接近的时候,就立即可以执行导出堆栈的操作了。
注:这是因为我这里没有在jvm参数中使用"-server"参数,也没有指定FGC的阀值,在线上的应用中通过会指定CMSInitiatingOccupancyFraction这个参数来指定当老年代使用了百分之多少的时候,通过CMS进行FGC,当然这个参数需要和这些参数一起使用“-XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:+UseCMSInitiatingOccupancyOnly”,CMSInitiatingOccupancyFraction的默认值是68,现在中文站线上的应用都是70,也就是说当老年代使用率真达到或者超过70%时,就会进行FGC。
导出dump数据文件
jmap -dump:format=b,file=heap.bin <pid>
这个时候会在当前目录以生成一个heap.bin这个二进制文件。
通过命令查看大对象
也是使用jmap的命令,只不过参数使用-histo
使用:jmap -histo <pid>|less
可得到如下包含对象序号、某个对象示例数、当前对象所占内存的大小、当前对象的全限定名,如下图:
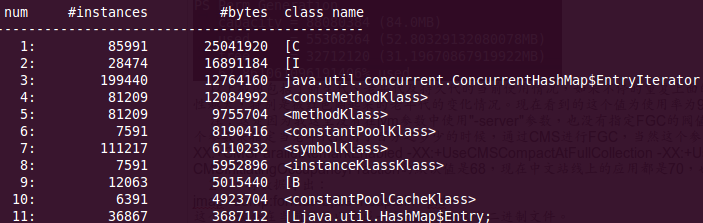
查看对象数最多的对象,并按降序排序输出:
执行:jmap -histo <pid>|grep alibaba|sort -k 2 -g -r|less
查看占用内存最多的最象,并按降序排序输出:
执行:jmap -histo <pid>|grep alibaba|sort -k 3 -g -r|less
数据分析,将dump文件使用工具打开
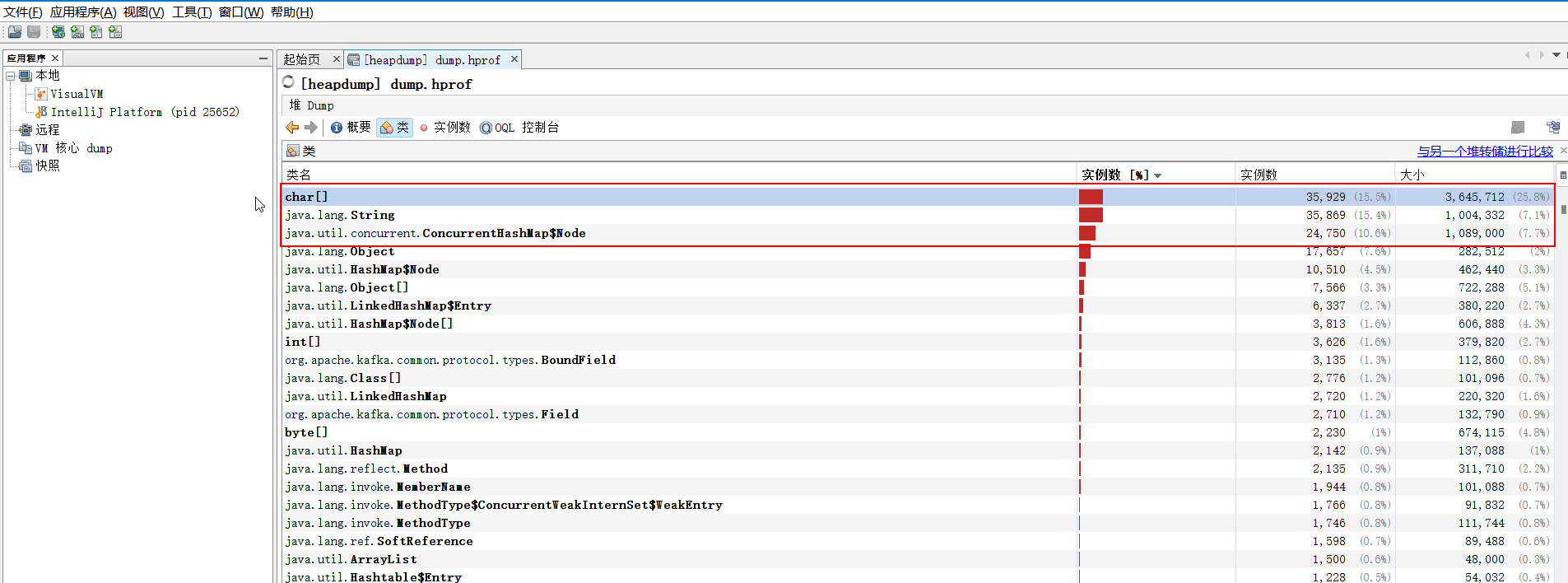
总结
- 如果程序内存不足或者频繁GC,很有可能存在内存泄露情况,这时候就要借助Java堆Dump查看对象的情况。
- 要制作堆Dump可以直接使用jvm自带的jmap命令
- 可以先使用jmap -heap命令查看堆的使用情况,看一下各个堆空间的占用情况。
- 使用jmap -histo:[live]查看堆内存中的对象的情况。如果有大量对象在持续被引用,并没有被释放掉,那就产生了内存泄露,就要结合代码,把不用的对象释放掉。
- 也可以使用 jmap -dump:format=b,file=命令将堆信息保存到一个文件中,再借助jhat命令查看详细内容
- 在内存出现泄露、溢出或者其它前提条件下,建议多dump几次内存,把内存文件进行编号归档,便于后续内存整理分析。
- 在用cms gc的情况下,执行jmap -heap有些时候会导致进程变T,因此强烈建议别执行这个命令,如果想获取内存目前每个区域的使用状况,可通过jstat -gc或jstat -gccapacity来拿到。
Jhat
说明
jhat是用来分析jmap生成dump文件的命令,jhat内置了应用服务器,可以通过网页查看dump文件分析结果,jhat一般是用在离线分析上。
jhat 一般与 jmap 搭配使用,用于分析 jmap 生成的堆转储快照。jhat 是一个命令行工具,使用起来比较简便,但功能也相对简陋。如果条件允许的话,建议使用 JProfiler 或者 IBM HeapAnalyzer 等功能更强大的工具来分析 heapdump 文件。
命令格式:jhat [option] [dumpfile]
option参数解释:
-J<flag>:因为 jhat 命令实际上会启动一个 JVM 来执行,通过 -J 可以在启动 JVM 时传入一些启动参数。例如,-J-Xmx512m 指定运行 jhat 的 JVM 使用的最大堆内存为 512 MB。 如果需要使用多个 JVM 启动参数,则传入多个 -Jxxxxxx。
-stack false|true:关闭跟踪对象分配调用堆栈。如果分配位置信息在堆转储中不可用,则必须将此标志设置为 false。默认值为 true。
-refs false|true:关闭对象引用跟踪。默认情况下,返回的指针是指向其他特定对象的对象,如反向链接或输入引用(referrers or incoming references),,会统计/计算堆中的所有对象。
-port port-number:设置 jhat HTTP server 的端口号,默认值 7000。
-exclude exclude-file:指定对象查询时需要排除的数据成员列表文件。 例如,如果文件列出了 java.lang.String.value,那么当从某个特定对象 Object o 计算可达的对象列表时,引用路径涉及 java.lang.String.value 的都会被排除。
-baseline exclude-file:指定一个基准堆转储(baseline heap dump)。 在两个 heap dump 文件中有相同 object ID 的对象会被标记为不是新的(marked as not being new),其他对象被标记为新的(new)。在比较两个不同的堆转储时很有用。
-debug int:设置 debug 级别,0 表示不输出调试信息。 值越大则表示输出更详细的 debug 信息。
-version:启动后只显示版本信息就退出。
- -debug <int>: debug级别
- 0: 无debug输出
- Debug hprof file parsing
- Debug hprof file parsing, no server
- -version 分析报告版本使用案例
jhat dump.hprofip:7000 既可以访问

最底部给出了可以查看的列表:

分别为:
- All classes including platform:所有在堆中创建对象的类,包括 JDK 中定义的类。
- Show all members of the rootset:从根集能引用到的对象。
- Show instance counts for all classes (including platform):所有类(包括 JDK 中定义的类)的实例数量。
- Show instance counts for all classes (excluding platform):所有类(不包括 JDK 中定义的类)的实例数量。
- Show heap histogram:堆实例的分布表。
jstack
说明
jstack是用来查看JVM线程快照的命令,线程快照是当前JVM线程正在执行的方法堆栈集合。使用jstack命令可以定位线程出现长时间卡顿的原因,例如死锁,死循环等。jstack还可以查看程序崩溃时生成的core文件中的stack信息。
命令格式
jstack [option] <pid> // 打印某个进程的堆栈信息
option选项:
jstack [-l] <pid> (连接运行中的进程)
jstack -F [-m] [-l] <pid> (连接挂起的进程)
jstack [-m] [-l] <executable> <core> (连接core文件)
jstack [-m] [-l] [server_id@]<remote server IP or hostname> (连接远程debug服务器)option参数解释:
-F 当使用jstack <pid>无响应时,强制输出线程堆栈。
-m 同时输出java和本地堆栈(混合模式),以星号为前缀的帧是Java方法栈帧,而不以星号为前缀的是本地方法栈帧。
-l 除堆栈外,显示关于锁的附加信息,在发生死锁时可以用jstack -l pid来观察锁持有情况线程状态分析
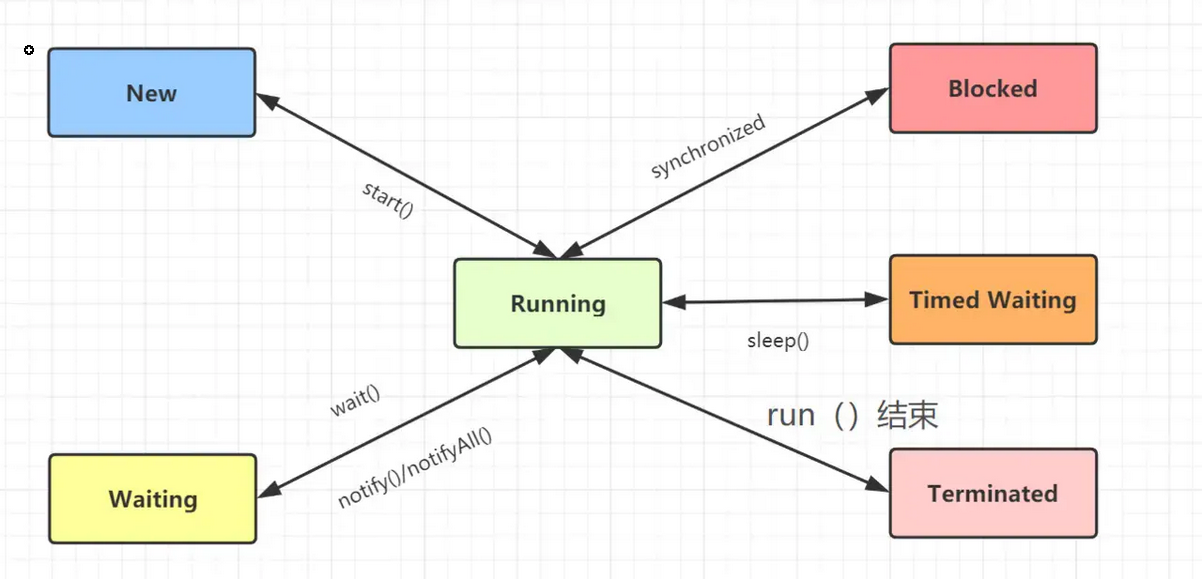
Java语言定义了6种线程池状态:
- New:创建后尚未启动的线程处于这种状态,不会出现在Dump中。
- RUNNABLE:包括Running和Ready。线程开启start()方法,会进入该状态,在虚拟机内执行的。
- Waiting:无限的等待另一个线程的特定操作。
- Timed Waiting:有时限的等待另一个线程的特定操作。
- 阻塞(Blocked):在程序等待进入同步区域的时候,线程将进入这种状态,在等待监视器锁。
- 结束(Terminated):已终止线程的线程状态,线程已经结束执行。
Dump文件的线程状态一般其实就以下3种:
- RUNNABLE,线程处于执行中
- BLOCKED,线程被阻塞
- WAITING,线程正在等待
Monitor监视锁
因为Java程序一般都是多线程运行的,Java多线程跟监视锁环环相扣,所以我们分析线程状态时,也需要回顾一下Monitor监视锁知识。

- 线程想要获取monitor,首先会进入Entry Set队列,它是Waiting Thread,线程状态是Waiting for monitor entry。
- 当某个线程成功获取对象的monitor后,进入Owner区域,它就是Active Thread。
- 如果线程调用了wait()方法,则会进入Wait Set队列,它会释放monitor锁,它也是Waiting Thread,线程状态in Object.wait()
- 如果其他线程调用 notify() / notifyAll() ,会唤醒Wait Set中的某个线程,该线程再次尝试获取monitor锁,成功即进入Owner区域。
Dump 文件分析关注重点:
- runnable,线程处于执行中
- deadlock,死锁(重点关注)
- blocked,线程被阻塞 (重点关注)
- Parked,停止
- locked,对象加锁
- waiting,线程正在等待
- waiting to lock 等待上锁
- Object.wait(),对象等待中
- waiting for monitor entry 等待获取监视器(重点关注)
- Waiting on condition,等待资源(重点关注),最常见的情况是线程在等待网络的读写
查看线程堆栈信息
此命令用来查看进程下jvm的运行状态:
jstack 进程号jstack分析cpu过高问题
示例代码
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* className: TestCpuHight
* description:
* author: MrR
* date: 2024/11/25 13:03
* version: 1.0
*/
public class TestCpuHight{
private static ExecutorService executorService = Executors.newFixedThreadPool(5);
private static Object lock = new Object();
public static void main(String[] args) {
Task task1 = new Task();
Task task2 = new Task();
System.out.println("提交task1....");
executorService.submit(task1);
System.out.println("提交task2....");
executorService.submit(task2);
}
static class Task implements Runnable{
@Override
public void run() {
synchronized (lock){
long sum = 0;
while (true){
try {
Thread.sleep(200);
sum++;
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
}
}循环导致cpu占用过高;
使用jstack分析cpu过高问题步骤:
- top
- top -Hp pid
- jstack pid
- jstack -l [PID] >/tmp/log.txt
- 分析堆栈信息
使用top命令查看占用cpu过高的进程

在服务器上,我们可以通过top命令查看各个进程的cpu使用情况,它默认是按cpu使用率由高到低排序的;
从上图中,我们可以看到pid为11957的进程cpu占用很高;
查看各个线程cpu占用情况
top -Hp pid:查看进程中线程cpu占用情况;
通过top -Hp 11975可以查看该进程下,各个线程的cpu使用情况,如下:

上图中看到线程12010 cpu占用率为99.9%,因此我们重点分析该线程的堆栈数据;
jstack命令查看进程堆栈信息
jstack -l pid 命令查看进程堆栈信息;
通过top命令定位到cpu占用率较高的线程之后,接着使用jstack pid命令来查看当前java进程的堆栈状态;
将线程堆栈信息重定向到本地文件,然后将cpu占用率较高的线程id号转换为十六进制;
例如本例子中线程号12010转换为16进制为:2eea,我们使用此编号去堆栈文件中定位线程的堆栈信息;
"pool-1-thread-2" #19 prio=5 os_prio=0 tid=0x00007f36b0127000 nid=0x2eeb waiting for monitor entry [0x00007f362f9fa000]
java.lang.Thread.State: BLOCKED (on object monitor)
at TestCpuHight$Task.run(TestCpuHight.java:31)
- waiting to lock <0x00000000d86744f0> (a java.lang.Object)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Locked ownable synchronizers:
- <0x00000000d8676ca8> (a java.util.concurrent.ThreadPoolExecutor$Worker)
"pool-1-thread-1" #18 prio=5 os_prio=0 tid=0x00007f36b0125800 nid=0x2eea runnable [0x00007f362fafa000]
java.lang.Thread.State: RUNNABLE
at TestCpuHight$Task.run(TestCpuHight.java:33)
- locked <0x00000000d86744f0> (a java.lang.Object)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Locked ownable synchronizers:
- <0x00000000d8676870> (a java.util.concurrent.ThreadPoolExecutor$Worker)如上,我们定位到:pool-1-thread-1,nid=0x2eea,可以看到该线程处于running状态,并且处于锁占用状态;具体代码在TestCpuHight.java:33位置;

这段代码刚好就是true循环位置,因此也就定位到cpu占用高的原因;
jstack分析死锁问题
什么是死锁:死锁是指两个或两个以上的线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法进行下去。
死锁代码
import java.util.concurrent.locks.ReentrantLock;
/**
* className: DeadLock
* description:
* author: MrR
* date: 2024/11/25 20:15
* version: 1.0
*/
public class DeadhLock {
public static ReentrantLock lock1 = new ReentrantLock();
public static ReentrantLock lock2 = new ReentrantLock();
public static void deadhLock(){
Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
try {
lock1.lock();
System.out.println(Thread.currentThread().getName() + " get the lock1");
Thread.sleep(1000);
lock2.lock();
System.out.println(Thread.currentThread().getName() + " get the lock2");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread thread2 = new Thread(new Runnable() {
@Override
public void run() {
try {
lock2.lock();
System.out.println(Thread.currentThread().getName() + " get the lock1");
Thread.sleep(1000);
lock1.lock();
System.out.println(Thread.currentThread().getName() + " get the lock2");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
//设置线程名字,方便分析堆栈信息
thread1.setName("mythread-thread1");
thread2.setName("mythread-thread2");
thread1.start();
thread2.start();
}
public static void main(String[] args) {
deadhLock();
}
}两个线程已经抢占到自己的锁,然后分别在去抢占对方的锁,因此会发生僵持,在没有打断的情况下,很明显发生了死锁:
mythread-thread1 get the lock1
mythread-thread2 get the lock1jstack排查死锁的步骤
- 在终端中输入jps查看当前运行的java程序
- 使用 jstack -l pid 查看线程堆栈信息
- 分析堆栈信息
首先通过jps命令进程pid号:

通过jstack -l 59281 >> jstack.log 重定向进程的堆栈信息;
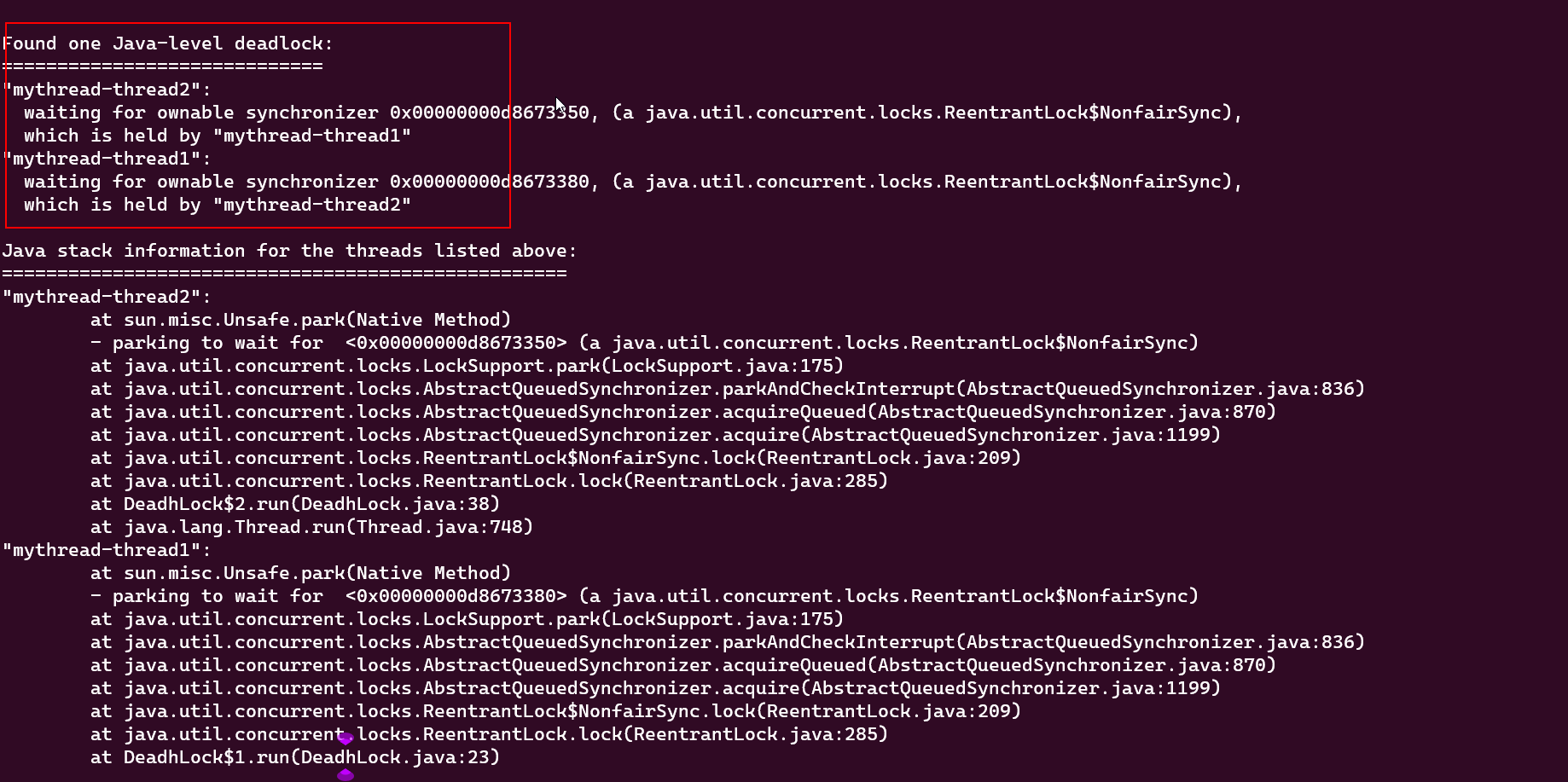
从堆栈数据,可以看到mythread-thread2线程在获取 0x00000000d8673350锁对象,但是这把锁被mythread-thread1所持有;
然后mythread-thread1线程在获取0x00000000d8673380这把锁,但是被mythread-thread2线程2所持有,因此两个线程分别抢占对方的锁,发生死锁;