现在的大数据开发很多公司为了效率考虑,大多数使用sql,不管是hive sql 还是spark sql,其执行流程大多很类似,在我的工作中,更多的是使用spark sql来进行作业的开发,所以第一篇,我们先来从整体上分析一下spark sql的执行流程。
1、执行流程概述
sql在转换为RDD执行中会经过如下几个阶段:
大约 15 分钟
现在的大数据开发很多公司为了效率考虑,大多数使用sql,不管是hive sql 还是spark sql,其执行流程大多很类似,在我的工作中,更多的是使用spark sql来进行作业的开发,所以第一篇,我们先来从整体上分析一下spark sql的执行流程。
sql在转换为RDD执行中会经过如下几个阶段:
如果你没有兴趣/时间阅读全文,那么可以先试着设置以下几个参数:
上游数据必须得仍然存在,因抢占⽽kill的Task不消耗重试次数
重试
map,单split存在
推测执⾏,reduce shuffle block必须都存在
上游数据必须得仍然存在,参考Task容错,差异在所有Task都重跑,重试
| 参数 | 描述 | 源码默认值 | TQS默认值(adhoc/etl) |
|---|---|---|---|
| spark.executor.instances | 静态资源下:executor数 | 2 | TQS使用动态资源 |
| spark.executor.cores | 每个executor和CPU数 | 4 | 3/4 |
| spark.dynamicAllocation.enabled | 动态资源开关 | false | true/true |
| spark.dynamicAllocation.maxExecutors | 动态资源下:executor的最大个数 | 500 | 300/900 |
| spark.executor.memory | 每个executor的内存大小 | 8g | 5g/8g |
| spark.memory.fraction | executor用于计算的内存比例,剩余部分用于存储元数据和运行信息。对于executor内存开的较大的任务,可以适当提高这个值,让更多内存参与计算,但会增加OOM风险 | 0.6 | 0.7/0.6 |
| spark.executor.memoryOverhead/ spark.yarn.executor.memoryOverhead | 每个executor的堆外内存大小,堆外内存主要用于数据IO,对于报堆外OOM的任务要适当调大,单位Mb,与之配合要调大executor JVM参数,例如: set spark.executor.memoryOverhead=3072 set spark.executor.extraJavaOptions=-XX:MaxDirectMemorySize=2560m | 6144 | 3072/6144 |
| spark.sql.adaptive.enabled | Adaptive execution开关,包含自动调整并行度,解决数据倾斜等优化,详见https://github.com/Intel-bigdata/spark-adaptive | true | true/true |
| spark.sql.adaptive.minNumPostShufflePartitions | AE相关,动态最小的并行度 | 1 | 1/1 |
| spark.sql.adaptive.maxNumPostShufflePartitions | AE相关,动态最大的并行度,对于shuffle量大的任务适当增大可以减少每个task的数据量,如1024 | 1000 | 1000/500 |
| spark.sql.adaptive.shuffle.targetPostShuffleInputSize | AE相关,调整并发度时预期达到的单task数据量 | ||
| spark.sql.adaptive.shuffle.targetPostShuffleRowCount | AE相关,调整并发度时预期达到的单task数据行数 | ||
| spark.sql.adaptive.join.enabled | AE相关,开启后能够根据数据量自动判断能否将sortMergeJoin转换成broadcast join | true | true/true |
| spark.sql.adaptiveBroadcastJoinThreshold | AE相关,spark.sql.adaptive.join.enabled设置为true后会判断join的数据量是否小于该参数值,如果小于则能将sortMergeJoin转换成broadcast join | spark.sql.autoBroadcastJoinThreshold | spark.sql.autoBroadcastJoinThreshold |
| spark.sql.adaptive.skewedJoin.enabled | AE相关,开启后能够自动处理join时的数据倾斜,对于数据量明显高于中位数的task拆分成多个小task | false | true/false |
| spark.sql.adaptive.skewedPartitionFactor | AE相关,数据倾斜判定标准,当同一stage的某个task数据量超过中位数的N倍,将会判定为数据倾斜 | 5 | 3/5 |
| spark.sql.adaptive.skewedPartitionMaxSplits | AE相关,被判定为数据倾斜后最多会被拆分成的份数 | 5 | 6/5 |
| spark.shuffle.accurateBlockThreshold | AE相关,数据倾斜判定基于shuffle数据量统计,如果统计所有的block数据,消耗内存较大,因此设有阈值,当shuffle的单个数据块超过大小和行数阈值时,才会进入统计,这个参数即大小阈值 | 10010241024(100MB) | 4000000/10010241024 |
| spark.shuffle.accurateBlockRecordThreshold | AE相关,同上,行数阈值,如果设置了上面的数据倾斜处理开关,仍然倾斜,可能是因为这几个参数设得偏大,适当缩小 | 2 * 1024 * 1024 | 500000/2 * 1024 * 1024 |
| spark.sql.files.maxPartitionBytes | 默认一个task处理的数据大小,如果给的太小会造成最终任务task太多,太大会是输入环节计算较慢 | 1073741824 | 268435456/1073741824 |
| spark.datasource.splits.max | 第一阶段扫表的task上限,用户可以设置在50000,task太多会造成下阶段oom。如果task不够50000,则不做任何事情,否则限制task总数在50000。 (默认不限制,task数等于总的文件大小除以spark.sql.files.maxPartitionBytes) | 0 (不限制task上限) | 5000/50000 |
| spark.vcore.boost.ratio | vcore,虚拟核数,设置大于1的数可以使一个核分配多个task,对于简单sql可以提升CPU利用率,对于复杂任务有OOM风险 | 1 | 2/(ETL国际化是2,国内是1) |
| spark.shuffle.hdfs.enabled(长任务推荐) | HDFS based Spark Shuffle开关,可以提高任务容错性。遇到org.apache.spark.shuffle.FetchFailedException报错需设置 | false | false/false |
| spark.shuffle.hdfs.rootDir (推荐) | 根据机房不同设置不同的值 怀来:hdfs://haruna/spark_hl/shuffle/hdfs_dancenn 廊坊:hdfs://haruna/spark_lf/shuffle/hdfs_dancenn | 默认已配置,只需开启上一个参数即可 | |
| set spark.shuffle.io.maxRetries=1; set spark.shuffle.io.retryWait=0s; | 一般在开启hdfs shuffle后还可以开启这两个参数,避免不必要的重试和等待 | ||
| spark.shuffle.hdfs.replication | Hdfs Shuffle 文件的副本数 | 2 | |
| spark.sql.crossJoin.enabled | 对于会产生笛卡尔积的sql,默认配置是限制不能跑的,在hive里可以配置set hive.mapred.mode=nonstrict跳过限制,相对应的在spark里可以配置set spark.sql.crossJoin.enabled=true起到同样的效果。 | false | true/true |
| spark.sql.broadcastTimeout | broadcast joins时,广播数据最长等待时间,网络不稳定时,容易出现超时造成任务失败,可适当增大此参数。 | 300(单位:s) | 3000/3000 |
| spark.sql.autoBroadcastJoinThreshold | 表能够使用broadcast join的最大阈值 | 10MB | 20MB |
| spark.network.timeout | 网络连接超时参数 | 120s | 120s/120s |
| spark.maxRemoteBlockSizeFetchToMem | reduce端获取的remote block存放到内存的阈值,超过该阈值后数据会写磁盘,当出现数据量比较大的block时,建议调小该参数(比如512MB)。 | Long.MaxValue | 536870912/536870912 |
| spark.reducer.maxSizeInFlight | 控制从一个worker拉数据缓存的最大值 | 48m | 48m/48m |
| spark.merge.files.enabled | 合并输出文件,如果insert结果的输出文件数很多,希望合并,可以设为true,会多增加一个repartition stage合并文件,repartition的分区数由spark.merge.files.number控制 | false | |
| spark.merge.files.number | 控制合并输出文件的输出数量 | 512 | |
| spark.speculation | 推测执行开关。如果是原生任务很有可能没开这个参数,会出现个别task拖慢整个任务,可以开启这个参数。 | true | true |
| spark.speculation.multiplier | 开启推测执行的时间倍数阈值:当某个任务运行时间/中位数时间大于该值,触发推测执行。对于因为推测执行而浪费较多资源的任务可以适当调高这个参数。 | 1.5 | |
| spark.speculation.quantile | 同一个stage中的task超过这个参数比例的task完成后,才会开启推测执行。对于因为推测执行而浪费较多资源的任务可以适当调高这个参数。 | 0.75 | 0.98/0.98 |
| spark.default.parallelism | Spark Core默认并发度,原生spark程序并发度设置 | 200 | 200/200 |
| spark.sql.shuffle.partitions | Spark SQL默认并发度,AE开启后被spark.sql.adaptive.maxNumPostShufflePartitions取代 | 200 | 200/200 |
| spark.sql.sources.bucketing.enabled | 分桶表相关,当设置为false,会将分桶表当作普通表来处理。做为普通表会忽略分桶特性,部分情况性能会下降。但如果分桶表没有被正确生成(即表定义是分桶表,但数据未按分桶表生成)会报错RuntimeException: Invalid bucket file,避免这个错误,要将这个参数设为false | true | false/false |
| spark.hadoop.hive.metastore.client.socket.timeout | 连接hivemetastore的超时时间,对于出现超时导致失败,可以暂时扩大这个时间保证任务完成,但长远方案应该是优化相关逻辑,减少相应操作的耗时。 | 200 | 200 |
| spark.sql.partition.rownum.collect.enable | 统计生成固定分区表行数 | false | true |
| spark.sql.dynamic.partition.rownum.collect.enable | 统计生成动态分区表行数 | false | true |
| spark.yarn.am.waitTime | SparkContext启动等待时间,有时任务会出现如下报错,可能是偶然的系统波动导致的超时,可以扩大改参数值解决  |
100s | 200s |
| spark.sql.parquet.enableVectorizedReader | 开启parquet向量化读 | true | |
| spark.sql.orc.enableVectorizedReader | 开启orc向量化读 | true |
禁止通过增加执行资源的方式来达成任务的目的
大多数参数调整无大意义,线上场景也比较复杂,没必要精细化调整每个参数到最优,保持一类任务的参数大致统一才是最佳方案
尽可能控制任务的资源使用
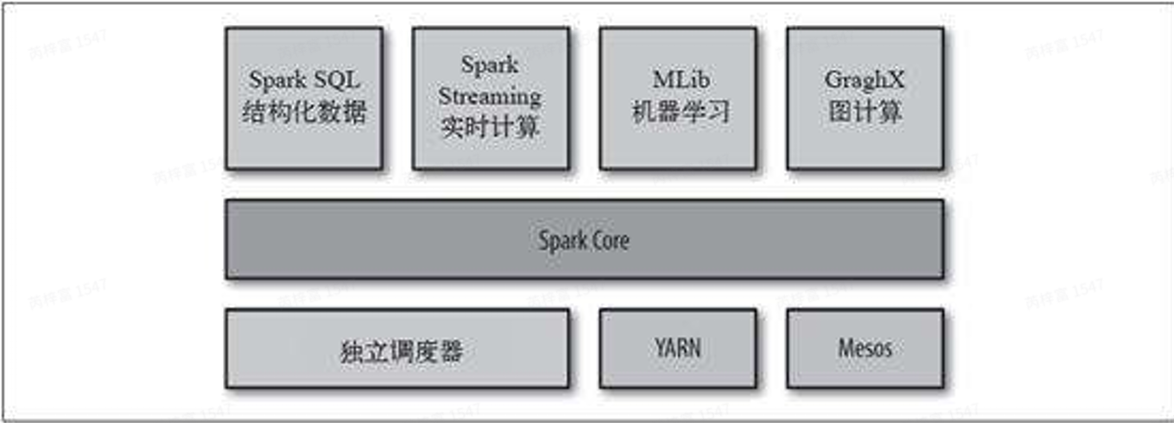
Spark 分布式计算框架由美国加州⼤学伯克利分校的AMP实验室开发。相⽐于Hadoop⾃带的 MapReduce计算框架,Spark优势明显。Spark⼀⽅⾯提供了更加灵活丰富的数据操作⽅式,有些 需要分解成⼏轮MapReduce作业的操作,可以在Spark⾥⼀轮实现;另⼀⽅⾯,每轮的计算结果都 可以分布式地存放在内存中,下⼀轮作业直接从内存中读取数据,节省⼤量磁盘IO开销。
Spark执⾏insert相关sql时,只能通过shuffle参数spark.sql.shuffle.partitions或者spark.sql.adaptive.maxNumPostShufflePartitions(开启AE:spark.sql.adaptive.enabled=true)来控制最后⽣成的⽂件个数。
如果想要调整最后⽣成的⽂件数量,就必须调整shuffle并⾏度,sql中所有stages的并⾏度都受该参数影响,这样可能会对任务的运⾏时⻓造成较⼤的影响,因此在Spark中增加合并⽂件的功能。
该功能⽐较适合的场景:insert相关的sql,sql处理的数据量⽐较⼤(如⼤于1T)且最后⽣成的数据量却较⼩(如⼩于100G)的情况
分享⽬标:
CREATE TABLE ies_dw_test.zhangfei_20200320_challenge_label_1 AS
2 SELECT * from(
3 SELECT /*+mapjoin(b)*/
4 b.*,
5 a.second_level_label_name,
6 count(1) as cn,
7 row_number() over( --row_number()
8 partition by b.challenge_ids
9 order by count(1) desc
10 ) as rn
11 FROM
12 aweme.mds_dm_item_id_stats a
13 JOIN ies_dw_test.guanyu_huati b --broadcast join
14 on a.challenge_ids = b.challenge_ids
15 where --filter
16 date = '${date}'
17 and item_create_day >= '20190901'
18 and a.challenge_ids is not null
19 group by --group by (aggregate)
20 b.time,
21 b.challenge_name,
22 b.challenge_ids,
23 b.discription,
24 a.second_level_label_name
25 ) t
26 where --filter
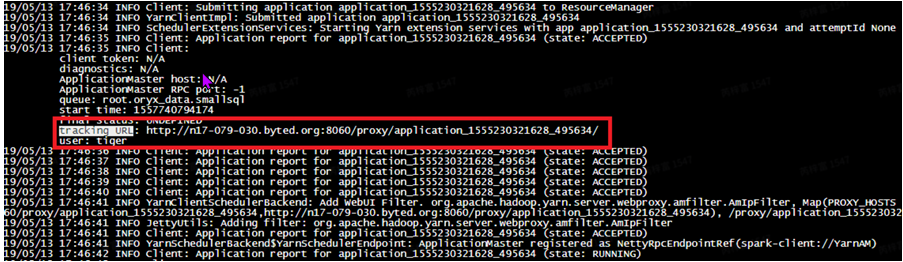
27 rn <= 2定位spark问题,⾸先需要找到任务的执⾏信息,主要包括sparkui,⽇志信息。 UI链接在⽇志⾥搜索trackingURL,找到任务对应的UI链接。